

En resumen;DR
|
Toda organización que maneja datos confidenciales se enfrenta a una realidad simple: un eslabón débil en la seguridad de los datos puede resultar en daños financieros, legales y de reputación masivos. Solo en 2024, las empresas de todo el mundo incurrieron en un costo promedio de violación de 4,45 millones de dólares, siendo los datos personales y financieros uno de los tipos de datos más frecuentemente atacados.
Lo que es aún más preocupante es que muchas de estas violaciones no ocurrieron en los sistemas de producción; sucedieron porque los datos confidenciales quedaron expuestos en entornos que no son de producción, como el desarrollo, las pruebas o el análisis.
Esto deja una cosa clara: proteger los datos confidenciales en cada etapa de su ciclo de vida ya no se trata solo de cumplimiento, se trata de proteger su negocio de un riesgo real y medible.
Al aplicar las técnicas correctas de enmascaramiento de datos, puede asegurarse de que, incluso si se accede a los datos sin autorización, sigan siendo inútiles para los atacantes, al tiempo que satisfacen las necesidades comerciales.
En este blog, descubrirá seis mejores prácticas prácticas de enmascaramiento de datos que pueden ayudar a su organización a reducir la exposición, fortalecer la seguridad y cumplir con confianza los requisitos reglamentarios.
La importancia del enmascaramiento de datos: por qué es importante para su organización
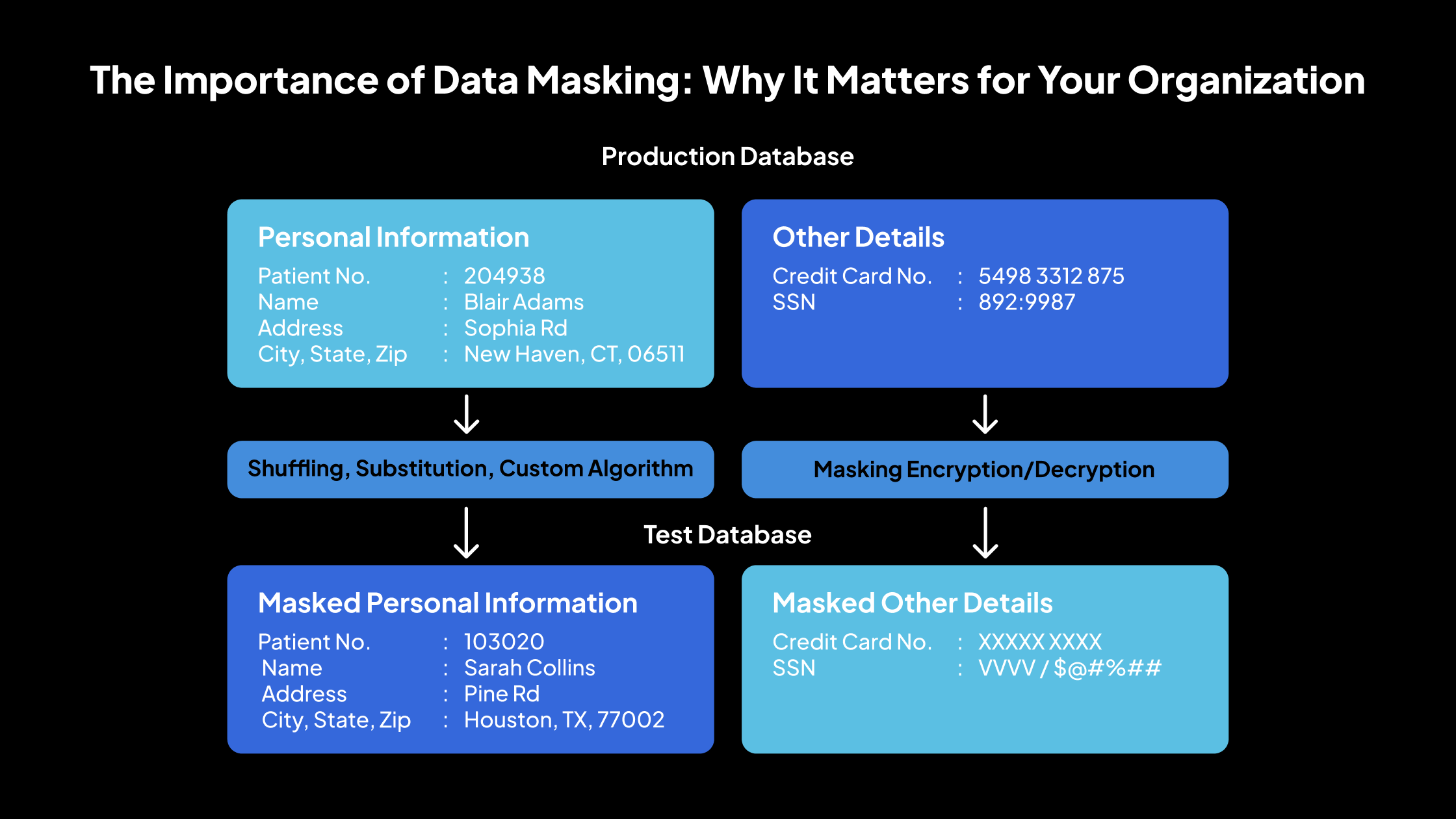
El enmascaramiento de datos es un método para reemplazar la información confidencial con datos realistas pero falsos. Se utiliza principalmente para proteger los detalles confidenciales, manteniendo al mismo tiempo la usabilidad de los datos para actividades que no son de producción, como las pruebas de software, la formación o las demostraciones.
Los datos enmascarados conservan el mismo formato que los originales, pero sus valores se alteran para que no se puedan rastrear ni revertir para revelar la información real. Las técnicas de enmascaramiento estándar incluyen la mezcla de caracteres, la sustitución de palabras o números y el uso del cifrado. Aquí está el por qué el enmascaramiento de datos es esencial:
Protege contra las violaciones de datos
El enmascaramiento de datos ayuda a proteger a las organizaciones de amenazas como la pérdida de datos, el acceso no autorizado y el uso indebido por parte de personas internas. Al enmascarar los detalles confidenciales, incluso si los datos quedan expuestos durante un ataque, siguen siendo inutilizables para los ciberdelincuentes. El enmascaramiento reduce el riesgo de este impacto financiero al hacer que los datos no tengan sentido para los atacantes.
Seguridad en la nube
Muchas organizaciones están moviendo sus datos a entornos de nube. El enmascaramiento de datos reduce los riesgos asociados con el almacenamiento de información confidencial en la nube al garantizar que los datos expuestos o mal gestionados no puedan comprometer a la organización. Esto es especialmente importante ya que el 85% de las empresas ahora operan en entornos multi-nube.
Intercambio seguro de datos
Los datos enmascarados permiten a las empresas compartir información con usuarios autorizados, como desarrolladores, evaluadores o analistas, sin revelar los detalles reales de los clientes o de la empresa. Esto garantiza el cumplimiento de las normas de privacidad al tiempo que apoya el desarrollo y la innovación.
Cumplimiento normativo
El enmascaramiento de datos apoya el cumplimiento de las regulaciones de protección de datos, como GDPR, HIPAA, y CCPA. Estas leyes exigen que las organizaciones aseguren los datos personales y confidenciales. El enmascaramiento es una forma eficaz de cumplir con estas obligaciones legales durante actividades como las pruebas y el análisis.
Mejor saneamiento de datos
La simple eliminación de archivos a menudo deja rastros de datos que pueden recuperarse. El enmascaramiento proporciona una capa adicional de protección al sobrescribir los valores originales con datos falsos, lo que hace que la recuperación y el uso indebido de los datos eliminados sean mucho más difíciles.
-
Utilidad de los datos para las pruebas y la formación
Los datos enmascarados conservan la misma estructura y formato que los originales, lo que permite utilizarlos en pruebas de software, formación de usuarios o entornos de demostración sin exponer información confidencial. Esto garantiza escenarios realistas sin arriesgarse a fugas de datos.
6 Mejores prácticas de enmascaramiento de datos para el cumplimiento y la seguridad

A continuación, se presentan seis mejores prácticas esenciales de enmascaramiento de datos que ayudan a proteger los datos confidenciales, respaldan el cumplimiento y fortalecen la postura de seguridad de su organización.
1. Realizar un descubrimiento y clasificación exhaustivos de los datos
Una estrategia sólida de enmascaramiento de datos comienza con la identificación exacta de qué datos requieren protección y dónde se almacenan. Sin esta base, los esfuerzos de enmascaramiento pueden pasar por alto datos críticos o aplicar un enmascaramiento innecesario, lo que resulta en riesgos e ineficiencias.
Identificar los datos confidenciales
El primer paso es localizar y comprender todos los datos confidenciales que maneja su organización. Esto incluye:
| Información de identificación personal (PII) | Información de salud protegida (PHI) | Datos financieros |
| Datos que pueden identificar a un individuo, como nombres, direcciones, números de teléfono, números de la seguridad social y números de pasaporte. | Los registros de salud, los diagnósticos, los detalles del tratamiento y la información del seguro están cubiertos por regulaciones como HIPAA. | Números de tarjetas de crédito, detalles de cuentas bancarias, historiales de transacciones y registros fiscales. |
Los datos confidenciales pueden almacenarse en formatos estructurados (por ejemplo, bases de datos, almacenes de datos) o en formatos no estructurados (por ejemplo, documentos, correos electrónicos, hojas de cálculo). Es esencial mapear todas las ubicaciones donde residen estos datos, incluidos los sistemas locales, los entornos de nube y las plataformas de terceros.
No identificar los repositorios de datos ocultos u olvidados es un riesgo de seguridad importante. Un estudio del Instituto Ponemon de 2023 encontró que el 67% de las organizaciones tenían datos confidenciales en ubicaciones que desconocían, lo que aumentaba la exposición a las infracciones.
Utilizar herramientas automatizadas
Dada la escala y la complejidad de los entornos de TI modernos, el descubrimiento manual de datos es ineficiente y propenso a errores. Las organizaciones deben adoptar herramientas automatizadas de descubrimiento y clasificación de datos que utilicen tecnologías como:
- Coincidencia de patrones (por ejemplo, detección de formatos de números de tarjetas de crédito o números de la seguridad social)
- Modelos de aprendizaje automático e IA para reconocer tipos de datos en varios sistemas
- Escaneo de metadatos para evaluar las propiedades de los archivos y los esquemas de las bases de datos
Estas herramientas pueden escanear grandes volúmenes de datos, identificar elementos confidenciales y clasificarlos con precisión en tiempo real o de forma programada. Además, la automatización ayuda a mantener un inventario actualizado de los datos confidenciales a medida que los sistemas evolucionan, los datos se expanden y se introducen nuevas fuentes.
Ejemplos de herramientas de descubrimiento de datos ampliamente utilizadas, como Microsoft Purview, ayudan a integrarse con las herramientas de enmascaramiento de datos, reduciendo así tanto el tiempo como el riesgo asociado con los procesos manuales.
Establecer la taxonomía de datos
Una vez que se identifican los datos, deben clasificarse según el nivel de sensibilidad, el requisito reglamentario y el caso de uso empresarial. Esto se conoce como la construcción de una taxonomía de datos. Una taxonomía bien definida ayuda a determinar:
- ¿Qué datos requieren enmascaramiento o cifrado?
- ¿Qué técnicas de enmascaramiento deben aplicarse?
- ¿Quién puede acceder a los datos enmascarados o no enmascarados?
- ¿Qué normativas se aplican a cada categoría de datos?
Una taxonomía podría incluir categorías como:
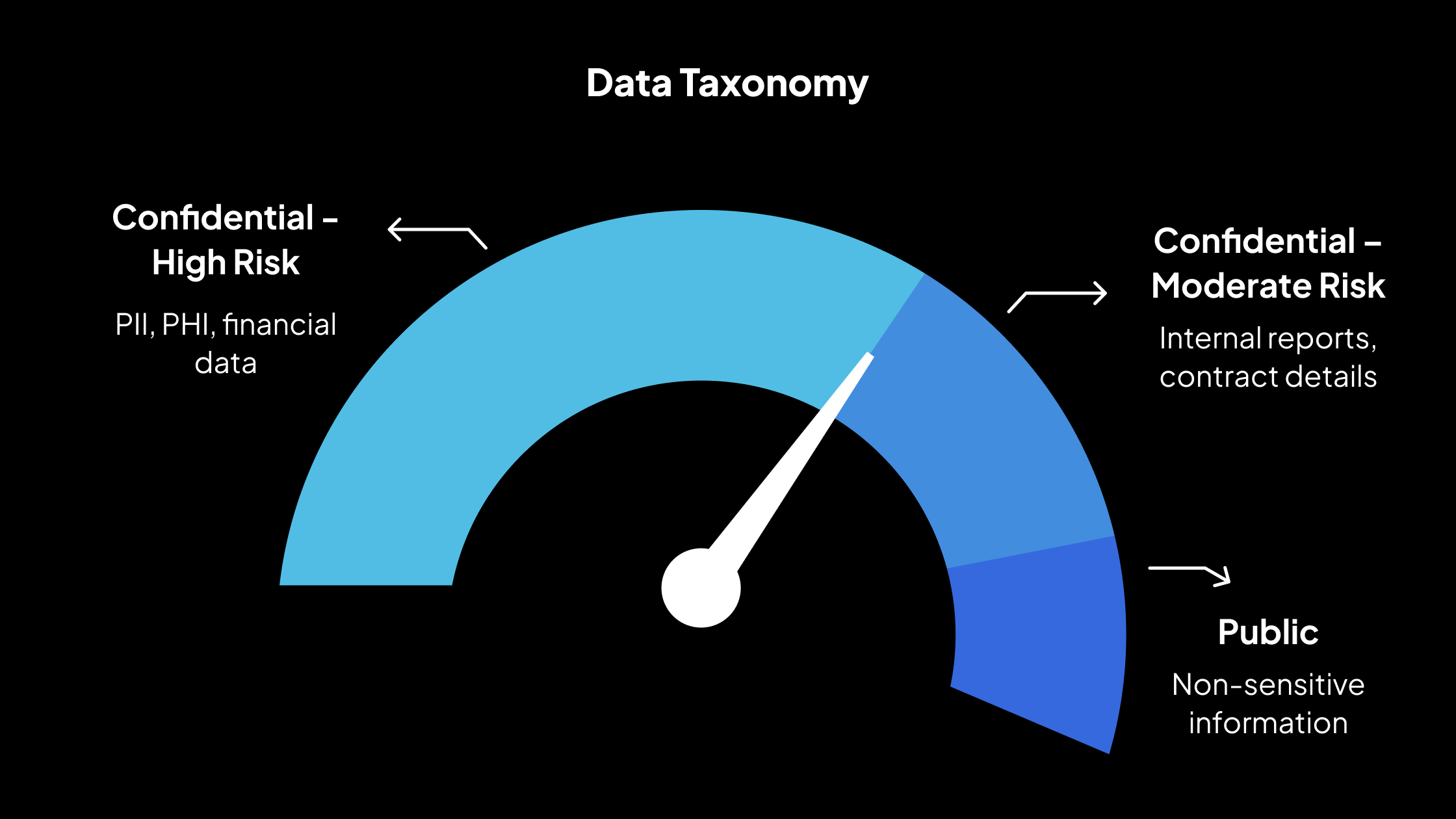
- Confidencial – Alto riesgo: PII, PHI, datos financieros (siempre deben enmascararse en entornos que no son de producción)
- Confidencial – Riesgo moderado: Informes internos, detalles del contrato (el enmascaramiento depende del caso de uso)
- Público: Información no confidencial (no se requiere enmascaramiento)
El establecimiento y el mantenimiento de esta taxonomía garantizan la coherencia en toda la organización y simplifican los informes reglamentarios y las auditorías. También permite una aplicación precisa y basada en el riesgo del enmascaramiento de datos, lo que reduce tanto los gastos generales operativos como la ofuscación innecesaria de los datos.
2. Elija las técnicas de enmascaramiento de datos adecuadas
La selección de la técnica correcta de enmascaramiento de datos es crucial para lograr un equilibrio entre la seguridad, el cumplimiento y la usabilidad. La elección depende del tipo de datos, el propósito del enmascaramiento y el entorno en el que se utilizarán los datos enmascarados.
Enmascaramiento de datos estático vs. dinámico
Enmascaramiento estático de datos (SDM)
El enmascaramiento estático de datos implica la creación de una copia enmascarada de una base de datos o un conjunto de datos. El proceso de enmascaramiento se realiza una vez en los datos originales, y el conjunto de datos resultante se utiliza entonces en entornos que no son de producción (por ejemplo, desarrollo, pruebas, formación).
Los datos enmascarados son persistentes y se almacenan por separado de los datos originales. SDM asegura que los datos confidenciales nunca se expongan en estos entornos porque los datos originales nunca salen de los sistemas de producción.
Enmascaramiento dinámico de datos (DDM)
El enmascaramiento dinámico de datos aplica el enmascaramiento sobre la marcha, en tiempo de ejecución de la consulta. Los datos originales permanecen intactos en la base de datos, pero los usuarios ven los valores enmascarados en función de sus derechos de acceso. Las reglas de enmascaramiento se aplican en tiempo real, lo que garantiza que los datos confidenciales estén protegidos sin necesidad de conjuntos de datos separados.
Se utiliza en los sistemas de producción en los que determinados usuarios (por ejemplo, los equipos de soporte, los contratistas) requieren vistas restringidas, así como en los portales de atención al cliente en los que es necesaria una visibilidad parcial de los datos. DDM ofrece flexibilidad y reduce los gastos generales de almacenamiento, pero requiere una configuración cuidadosa del control de acceso.
Métodos de enmascaramiento
Sustitución
La sustitución reemplaza los valores confidenciales con valores realistas, pero falsos, de un conjunto de datos predefinido. Por ejemplo, reemplazar los nombres reales con nombres de una lista de muestra. Se utiliza para el enmascaramiento de PII (nombres, direcciones) y es adecuado para entornos de prueba y demostración donde se requieren datos realistas.
Barajado
El barajado aleatoriza los datos dentro de una columna. Por ejemplo, los correos electrónicos de los clientes podrían ser barajados para que ningún registro conserve su correo electrónico original. Se utiliza para pruebas internas donde el formato importa, pero las relaciones de valor exactas no, y en escenarios donde la consistencia de los datos entre las filas no es crítica.
Cifrado
El cifrado transforma los datos en un formato ilegible utilizando algoritmos criptográficos. Solo los usuarios autorizados con claves de descifrado pueden acceder a los datos originales.
Se utiliza para proteger los datos confidenciales en tránsito o en reposo, así como en entornos de alta seguridad donde los datos deben ser cifrados para usuarios específicos.
Tokenización
La tokenización reemplaza los datos confidenciales con un valor único generado aleatoriamente (token). La relación entre los datos originales y el token se mantiene en una bóveda de tokens segura.
Se utiliza para el procesamiento de pagos (por ejemplo, reemplazar los números de tarjetas de crédito con tokens)
Y en los sistemas que requieren la trazabilidad entre los datos originales y los enmascarados
Preservar la integridad de los datos
Es esencial que el enmascaramiento de datos no rompa las aplicaciones o los procesos que dependen de los datos. La integridad referencial garantiza que las relaciones entre los elementos de datos (por ejemplo, las restricciones de clave externa en las bases de datos) permanezcan intactas después del enmascaramiento.
Aquí hay algunas consideraciones
- Enmascaramiento consistente: El mismo valor original siempre debe asignarse al mismo valor enmascarado cuando sea necesario (por ejemplo, los ID de cliente en las tablas).
- Preservación del formato: Los datos enmascarados deben conservar el formato de los datos originales (por ejemplo, formatos de fecha, longitudes de cadena) para evitar errores en las aplicaciones que los utilizan.
- Compatibilidad con la lógica empresarial: El enmascaramiento no debe interferir con la lógica del sistema, los informes o el análisis.
No preservar la integridad puede provocar fallos en las pruebas, resultados incorrectos o sistemas rotos en entornos que no son de producción.
3. Implementar controles de acceso basados en roles (RBAC)
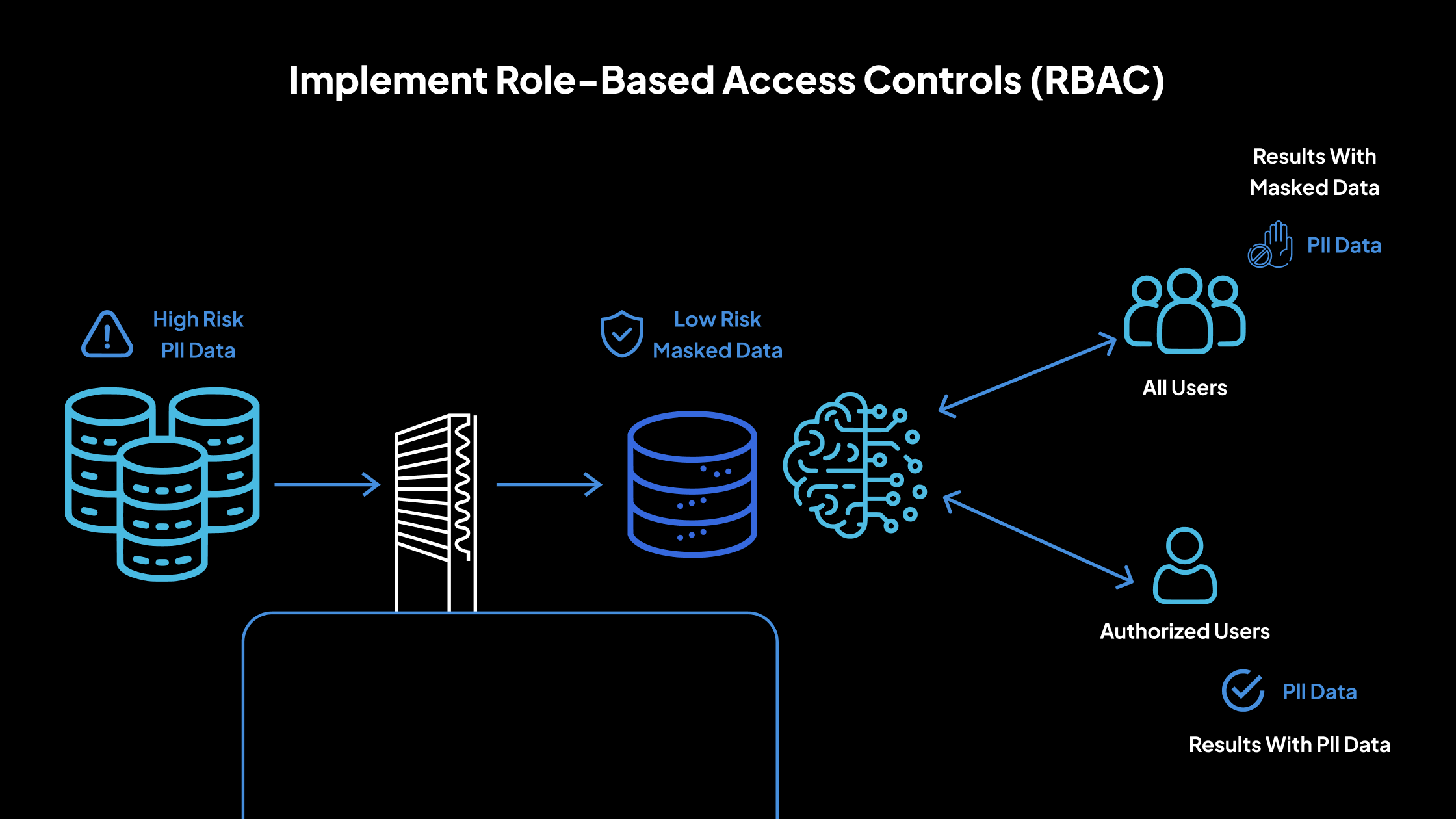
El control de acceso basado en roles (RBAC) es un mecanismo de seguridad que ayuda a garantizar que los datos confidenciales solo sean accesibles para las personas autorizadas. Al asignar permisos basados en los roles de trabajo, las organizaciones pueden reducir el riesgo de exposición no autorizada de los datos y mantener el cumplimiento de las regulaciones de protección de datos.
Definir los roles de usuario
El primer paso en RBAC es definir claramente los roles de usuario dentro de la organización. Cada rol debe reflejar funciones y responsabilidades laborales específicas. Por ejemplo:
| Administrador de la base de datos | Desarrollador | Analista de datos |
| Requiere acceso para administrar y mantener las bases de datos, incluidos los datos enmascarados y no enmascarados. | Necesita acceso a los datos enmascarados para las pruebas, pero no acceso a los datos de producción o no enmascarados. | Puede trabajar con datos agregados o anonimizados, sin acceso a datos personales identificables. |
Los roles deben asignarse a los derechos de acceso basándose en el principio del privilegio mínimo; a los usuarios solo se les conceden los permisos necesarios para realizar sus funciones. Esto reduce el riesgo de uso indebido accidental o intencional de datos confidenciales.
Restringir el acceso a los datos confidenciales
Una vez que se definen los roles, es crucial hacer cumplir las restricciones de acceso. Los datos confidenciales, como la información de identificación personal (PII) o la información de salud protegida (PHI), solo deben ser visibles en forma no enmascarada para las personas con una necesidad comercial legítima.
Por ejemplo, los desarrolladores que trabajan en entornos que no son de producción solo deben interactuar con datos que estén enmascarados o anonimizados. Los equipos de atención al cliente pueden ver datos parciales (por ejemplo, los últimos cuatro dígitos de una tarjeta de crédito) en lugar de conjuntos de datos completos.
Estas restricciones ayudan a proteger los datos de las amenazas internas y la exposición accidental al tiempo que apoyan las operaciones comerciales. Las bases de datos y aplicaciones modernas a menudo proporcionan soporte integrado para los permisos basados en roles, lo que facilita la aplicación de estos controles.
Supervisar y auditar el acceso
RBAC debe ser apoyado por la supervisión y auditoría continuas para asegurar que las políticas de acceso se cumplen y para identificar cualquier anomalía. Esto implica registrar todas las actividades de acceso a los datos, incluyendo las consultas realizadas contra los datos confidenciales, los cambios en las reglas de enmascaramiento y las modificaciones de los permisos.
La revisión periódica de los registros de auditoría ayuda a identificar los intentos de acceso no autorizados o los patrones sospechosos, y la generación de informes para fines de cumplimiento demuestra a los reguladores que el acceso a los datos está controlado y supervisado.
Las herramientas de supervisión automatizadas pueden proporcionar alertas en tiempo real cuando se violan las políticas de acceso, lo que permite una acción rápida para contener los riesgos potenciales.
4. Auditar y actualizar regularmente las políticas de enmascaramiento
El enmascaramiento de datos no es una actividad única. A medida que los entornos empresariales, los sistemas de datos y los requisitos reglamentarios evolucionan, las políticas de enmascaramiento deben revisarse y actualizarse para garantizar la eficacia continua. Un enfoque sistemático para auditar y actualizar estas políticas ayuda a las organizaciones a reducir el riesgo y mantener el cumplimiento.
Adaptarse a los cambios
Las políticas de enmascaramiento deben ser lo suficientemente flexibles para ajustarse cuando cambian los elementos clave del entorno empresarial o técnico.
Ejemplos de tales cambios incluyen modificaciones a las estructuras de datos, tales como nuevos campos añadidos a una base de datos o cambios de esquema en un almacén de datos, actualizaciones en los procesos de negocio que introducen nuevos flujos de datos o cambian la forma en que se manejan los datos confidenciales y las regulaciones de privacidad de datos nuevas o revisadas (por ejemplo, actualizaciones de GDPR, CCPA, o la introducción de nuevas leyes regionales).
Si las reglas de enmascaramiento no tienen en cuenta estos cambios, los datos confidenciales podrían quedar expuestos. Por lo tanto, las organizaciones deben tener un proceso formal para actualizar las políticas de enmascaramiento cada vez que cambien los sistemas o los requisitos de cumplimiento. Este proceso debe involucrar la colaboración entre los equipos de gobierno de datos, cumplimiento y TI para asegurar que todos los ángulos estén cubiertos.
Realizar revisiones periódicas
Las organizaciones deben realizar auditorías regulares para verificar que sus políticas y controles de enmascaramiento están funcionando como se pretende. Estas revisiones deben verificar que todos los datos confidenciales están enmascarados adecuadamente en todos los entornos, incluyendo las réplicas de producción, las copias de seguridad y los sistemas de prueba.
Comprobación de la deriva de políticas, donde las reglas de enmascaramiento pueden dejar de estar alineadas con las necesidades comerciales o regulatorias actuales, y prueba de la eficacia del enmascaramiento, asegurando que los datos enmascarados no puedan ser objeto de ingeniería inversa o reidentificados.
Un ciclo de auditoría podría ser trimestral o semestral, dependiendo de la sensibilidad de los datos y los requisitos reglamentarios. Los resultados de la auditoría deben documentarse y compartirse con las partes interesadas, incluidos los equipos de cumplimiento y seguridad.
Incorporar bucles de retroalimentación
Los resultados de la auditoría deben alimentar directamente el proceso de mejora de las prácticas de enmascaramiento. Este bucle de retroalimentación garantiza que las debilidades identificadas durante las auditorías conduzcan a mejoras prácticas en las técnicas o políticas de enmascaramiento, que los nuevos riesgos se aborden con prontitud, evitando la exposición de datos antes de que los problemas se agraven, y que las estrategias de enmascaramiento sigan estando alineadas con los objetivos empresariales y las normas reglamentarias.
La incorporación de comentarios ayuda a crear un ciclo de mejora continua. Las políticas de enmascaramiento no deben permanecer estáticas; deben evolucionar en función de los hallazgos internos y los cambios externos para garantizar la seguridad y el cumplimiento de los datos.
5. Integrar el enmascaramiento de datos en el ciclo de vida del desarrollo
Para construir sistemas seguros y conformes, el enmascaramiento de datos debe integrarse en cada etapa del ciclo de vida del desarrollo de software (SDLC). Esto garantiza que los datos confidenciales estén protegidos no solo en la producción, sino también en entornos que no son de producción, donde los datos suelen estar en mayor riesgo debido a un acceso más amplio y a menos controles.
Proteger los entornos que no son de producción
Los entornos de desarrollo, prueba y formación a menudo requieren datos realistas para simular las condiciones de producción. Sin embargo, el uso de datos de producción reales en estos entornos crea un riesgo de seguridad significativo. Los sistemas que no son de producción a menudo tienen controles de seguridad más bajos, un acceso más amplio por parte de terceros o contratistas y un mayor riesgo de fuga accidental de datos.
Aplique siempre el enmascaramiento de datos a los datos confidenciales antes de copiarlos o moverlos a entornos que no son de producción. Las técnicas de enmascaramiento deben garantizar que los datos conserven su estructura e integridad referencial para que las actividades de prueba y desarrollo no se vean interrumpidas.
Esto protege la información de identificación personal (PII), la información sanitaria protegida (PHI) y los datos financieros de una exposición innecesaria, al tiempo que permite a los equipos trabajar con conjuntos de datos realistas.
Automatizar los procesos de enmascaramiento
El enmascaramiento manual de datos requiere mucho tiempo, es propenso a errores y es difícil de escalar en los entornos de desarrollo modernos, en particular los que emplean prácticas ágiles o DevOps. Para abordar esto, las organizaciones deben integrar herramientas automatizadas de enmascaramiento de datos en sus conductos CI/CD.
La automatización garantiza que el enmascaramiento se aplique de forma coherente cada vez que se actualizan los datos en entornos que no son de producción, reduce el error humano y hace cumplir el cumplimiento de las políticas de enmascaramiento.
Las soluciones de enmascaramiento automatizadas se pueden configurar para que se ejecuten como parte de los procesos de construcción, implementación o actualización de datos. Esto garantiza que no entren datos sin enmascarar en los sistemas de prueba o desarrollo, lo que respalda los principios de seguridad por diseño.
Educar a los equipos de desarrollo
La tecnología por sí sola no es suficiente. Los equipos de desarrollo y pruebas deben comprender la importancia del enmascaramiento de datos y su papel en las prácticas de software seguras. Sin una conciencia adecuada, los equipos podrían eludir los controles de enmascaramiento o exponer involuntariamente datos confidenciales.
Explique los riesgos asociados con el uso de datos de producción reales en entornos que no son de producción. Guíe las prácticas de codificación segura que se alineen con los requisitos de enmascaramiento de datos. Enseñe cómo trabajar con datos enmascarados durante la depuración, las pruebas y el análisis sin comprometer la seguridad.
Los talleres periódicos, la documentación y la integración de temas de seguridad de datos en los programas de incorporación al desarrollo ayudan a construir una cultura de concienciación sobre la seguridad.
6. Garantizar el cumplimiento de las normas de protección de datos
El enmascaramiento de datos desempeña un papel crucial para ayudar a las organizaciones a cumplir con las leyes de protección de datos. Para lograr y mantener el cumplimiento, es esencial alinear las prácticas de enmascaramiento con las normas legales, documentar estos esfuerzos y supervisar continuamente los cambios normativos.
Comprender los requisitos reglamentarios
Las diferentes leyes de protección de datos especifican cómo las organizaciones deben manejar y proteger la información confidencial. Es esencial comprender las obligaciones relacionadas con el enmascaramiento de datos en virtud de estas regulaciones:
- RGPD (Reglamento General de Protección de Datos): exige a los responsables y encargados del tratamiento que apliquen medidas técnicas adecuadas, como la seudonimización y el enmascaramiento de datos, para proteger los datos personales (artículo 32). El enmascaramiento apoya los principios del RGPD al minimizar la exposición de información identificable en entornos que no son de producción o durante el intercambio de datos.
- HIPAA (Ley de Portabilidad y Responsabilidad del Seguro Médico) — Exige la salvaguarda de la información sanitaria protegida (PHI). El enmascaramiento ayuda a cumplir los requisitos de la norma de privacidad y seguridad de la HIPAA al desidentificar la PHI cuando se utiliza fuera de los sistemas clínicos.
- CCPA (Ley de Privacidad del Consumidor de California) — Enfatiza los derechos del consumidor sobre la información personal. El enmascaramiento de datos reduce el riesgo de divulgación no autorizada, lo que favorece el cumplimiento de las disposiciones de seguridad de datos de la CCPA.
La comprensión de estos requisitos legales ayuda a determinar dónde y cómo se debe aplicar el enmascaramiento, garantizando que las estrategias de enmascaramiento estén diseñadas para satisfacer necesidades de cumplimiento específicas.
Documentar los esfuerzos de cumplimiento
Para demostrar el cumplimiento durante las auditorías o las revisiones reglamentarias, es esencial mantener registros claros y precisos de las actividades de enmascaramiento de datos. Esto incluye m Documentos de política de enmascaramiento que describen qué elementos de datos se enmascaran, las técnicas utilizadas y las razones del enmascaramiento.
Registros de procesos que muestran cómo se aplica el enmascaramiento durante las migraciones de datos, las actualizaciones de entornos o las actividades de intercambio de datos. Registros de acceso que detallan quién aplicó o modificó las reglas de enmascaramiento, junto con las fechas y horas de estos cambios. Una documentación adecuada no solo apoya la preparación para la auditoría, sino que también ayuda a los equipos internos a revisar y mejorar las prácticas de enmascaramiento a lo largo del tiempo.
Manténgase informado sobre las actualizaciones legales
Las regulaciones de privacidad de datos continúan evolucionando a medida que los gobiernos introducen nuevas leyes y actualizan las existentes. Por ejemplo, la expansión de las leyes de privacidad a nivel estatal de EE. UU. (como la Ley de privacidad de Colorado) ha añadido nuevas obligaciones de cumplimiento.
Las organizaciones deben mantenerse al día sobre estos cambios para garantizar que las prácticas de enmascaramiento sigan cumpliendo las normas. Esto se puede lograr mediante revisiones legales periódicas en colaboración con los equipos de cumplimiento o legales, la supervisión de las actualizaciones de los organismos reguladores oficiales y los grupos de defensa de la privacidad, y el ajuste de las políticas y herramientas de enmascaramiento según sea necesario para alinearse con los nuevos requisitos.
Mantenerse proactivo reduce el riesgo de incumplimiento y garantiza que las medidas de protección de datos sigan siendo eficaces a medida que cambian las leyes.
Proteja la información confidencial con la herramienta inteligente de enmascaramiento de datos de Avahi
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi proporciona herramientas que permiten a las organizaciones gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es Data Masker, diseñado para proteger los datos financieros y de identificación personal, a la vez que respalda la eficiencia operativa.
Descripción general del Data Masker de Avahi
El Data Masker de Avahi es una herramienta versátil de protección de datos diseñada para ayudar a las organizaciones a gestionar de forma segura la información confidencial en diversas industrias, incluyendo la atención sanitaria, las finanzas, el comercio minorista y los seguros.
La herramienta permite a los equipos enmascarar datos confidenciales como números de cuenta, registros de pacientes, identificadores personales y detalles de transacciones sin interrumpir los flujos de trabajo operativos.
El Data Masker de Avahi garantiza que solo los usuarios autorizados puedan ver o interactuar con datos confidenciales aplicando técnicas avanzadas de enmascaramiento y aplicando el control de acceso basado en roles. Esto es especialmente importante cuando varios departamentos o proveedores externos acceden a los datos.
Ya sea protegiendo la información de salud del paciente en cumplimiento con HIPAA, anonimizando los registros financieros para PCI DSS o asegurando los datos del cliente para GDPR, la herramienta ayuda a las organizaciones a minimizar el riesgo de acceso no autorizado al tiempo que preserva la usabilidad de los datos para fines de desarrollo, análisis y supervisión del fraude.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, reconocemos la importancia crucial de proteger la información confidencial, a la vez que mantenemos flujos de trabajo operativos perfectos.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programar una llamada de demostración
Preguntas frecuentes
1) ¿Cuáles son las mejores prácticas de enmascaramiento de datos que deben seguir las organizaciones?
Las mejores prácticas de enmascaramiento de datos abarcan la realización de un descubrimiento exhaustivo de datos, la selección de las técnicas de enmascaramiento adecuadas, la implementación de controles de acceso basados en roles, la auditoría periódica de las políticas de enmascaramiento, la integración del enmascaramiento en el ciclo de vida del desarrollo y la garantía del cumplimiento de las normas de protección de datos. Estas prácticas ayudan a proteger la información confidencial al tiempo que apoyan las necesidades operativas y de cumplimiento.
2) ¿Por qué es necesario el enmascaramiento de datos para el cumplimiento y la seguridad?
El enmascaramiento de datos es crucial porque evita el acceso no autorizado a los datos confidenciales, reduce el riesgo de violaciones de datos y garantiza el cumplimiento de regulaciones como GDPR, HIPAA y CCPA. Permite a las organizaciones trabajar con datos realistas en entornos que no son de producción sin exponer información confidencial real.
3) ¿Cuál es la diferencia entre el enmascaramiento de datos estático y dinámico?
El enmascaramiento de datos estático crea una copia enmascarada de un conjunto de datos utilizado en entornos que no son de producción, como el desarrollo o las pruebas. El enmascaramiento de datos dinámico enmascara los datos en tiempo de ejecución de la consulta, mostrando valores enmascarados a los usuarios no autorizados al tiempo que conserva los datos originales en los sistemas de producción.
4) ¿Cómo apoya el enmascaramiento de datos la seguridad en la nube?
El enmascaramiento de datos apoya la seguridad en la nube al garantizar que los datos confidenciales almacenados o procesados en la nube estén ofuscados. Incluso si los datos de la nube se manejan mal o se exponen, los datos enmascarados son inútiles para los atacantes. Esto es crucial ya que la mayoría de las organizaciones ahora dependen de entornos multi-nube.
5) ¿Afecta el enmascaramiento de datos a la utilidad de los datos para las pruebas y el análisis?
No. Cuando se hace correctamente, el enmascaramiento de datos preserva el formato y la estructura de los datos originales. Esto permite a los equipos realizar pruebas, formación y análisis realistas sin exponer información confidencial.



