

En este blog, exploramos cómo se comportan los modelos fundacionales de AWS Bedrock en diversas condiciones de carga e introducimos una metodología de prueba reutilizable para ayudarle a comprender las características de rendimiento en sus propias aplicaciones. Nuestros hallazgos revelan que el tamaño del prompt influye significativamente en los patrones de escalado, y los prompts grandes degradan el rendimiento más rápidamente a medida que aumenta la concurrencia en comparación con los prompts más pequeños. Demostramos cómo las pruebas de rendimiento conectan los valores de cuota abstractos con la planificación de la capacidad en el mundo real, lo que ayuda a construir casos más sólidos para las solicitudes de aumento de cuota cuando sea necesario.
Al integrar modelos de lenguaje grandes (LLM) en sistemas de producción, en particular los que se sirven en servicios gestionados como AWS Bedrock, la comprensión de las características de rendimiento es fundamental tanto para el éxito técnico como para el empresarial. Las pruebas de rendimiento se vuelven aún más cruciales al considerar las cuotas de servicio que AWS impone al uso de Bedrock.
En este blog, nos proponemos lograr varios objetivos clave:
Al compartir nuestro enfoque y nuestros hallazgos, pretendemos ayudar a comprender mejor las características de rendimiento de los modelos de AWS Bedrock y a tomar decisiones informadas al diseñar sus aplicaciones.
Las cuentas de AWS tienen cuotas predeterminadas para Amazon Bedrock que restringen el número de solicitudes que puede realizar dentro de plazos específicos. Estas cuotas afectan directamente a la escalabilidad y a la experiencia del usuario de su aplicación.
Las cuotas de servicio clave para Amazon Bedrock incluyen:
Estas cuotas se aplican específicamente a la inferencia bajo demanda y representan el uso combinado en las API de Converse, ConverseStream, InvokeModel e InvokeModelWithResponseStream para cada modelo fundacional, región de AWS y cuenta de AWS. Tenga en cuenta que la inferencia por lotes opera bajo cuotas de servicio separadas. Para obtener más información sobre cómo funcionan estas cuotas, consulte Cuotas para Amazon Bedrock.
El conocimiento de estas cuotas es crucial al diseñar la arquitectura de su aplicación. Si sus requisitos de uso superan las cuotas predeterminadas asignadas a su cuenta de AWS, deberá solicitar un aumento, un proceso que requiere justificación. Para obtener orientación sobre el escalado con Amazon Bedrock, consulte Escalado con Amazon Bedrock.
Uno de los mayores desafíos con las cuotas de AWS Bedrock es la traducción de métricas abstractas como TPM y RPM en capacidad de aplicación práctica. ¿Qué significan realmente estos números para su caso de uso específico?
Las pruebas de rendimiento ayudan a responder preguntas críticas como:
Mediante la realización de pruebas de rendimiento específicas con sus prompts reales y los patrones de uso esperados, puede traducir los valores de cuota abstractos en una planificación de capacidad concreta: “Con nuestra cuota actual, podemos soportar X usuarios concurrentes con tiempos de respuesta de Y segundos”.
Las pruebas de rendimiento no son meramente un ejercicio técnico, sino una necesidad estratégica al implementar aplicaciones LLM en AWS Bedrock. Al establecer un enfoque sistemático para medir y analizar el rendimiento del modelo en diversas condiciones de carga, obtiene información crítica que informa todo, desde las decisiones arquitectónicas hasta la planificación de la capacidad y la gestión de cuotas.
Ahora vamos a explorar cómo implementar esta metodología de prueba en la práctica, examinando el código, las métricas y las técnicas de visualización que le darán una visión profunda de las características de rendimiento de su modelo.
Antes de profundizar en los resultados específicos de las pruebas, es esencial comprender cómo abordamos el desafío de probar sistemáticamente los modelos de AWS Bedrock. Nuestra metodología prioriza la reproducibilidad, las variables controladas y la simulación realista de las condiciones de producción. Al crear un marco estructurado en lugar de realizar pruebas ad hoc, podemos obtener información valiosa que se traslada directamente a los entornos de producción.
El marco de pruebas aprovecha la biblioteca asyncio de Python para crear patrones de carga controlados y reproducibles con varios componentes clave:
Este diseño modular nos permite aislar cada componente para la optimización y la depuración, manteniendo al mismo tiempo un enfoque de prueba cohesivo.
El marco admite dos enfoques de prueba distintos:
En este modo, cada lote de solicitudes concurrentes se completa totalmente antes de que comience el siguiente lote. Este enfoque proporciona mediciones limpias y aisladas sin interferencias entre lotes, lo que lo hace ideal para:
En este modo más realista, los nuevos lotes de solicitudes se lanzan a intervalos fijos, independientemente de si los lotes anteriores se han completado. Este enfoque simula mejor los patrones de tráfico del mundo real donde:
Este enfoque de modo dual nos permite tanto establecer líneas de base de rendimiento claras (secuencial) como observar cómo se comporta el sistema en condiciones de carga más realistas (intervalo).
El marco de pruebas necesita gestionar muchas solicitudes concurrentes sin convertirse en un cuello de botella en sí mismo. Configuramos un grupo de subprocesos con capacidad suficiente utilizando el ThreadPoolExecutor de Python como se muestra a continuación:
custom_executor = ThreadPoolExecutor(max_workers)
loop = asyncio.get_running_loop()
loop.set_default_executor(custom_executor)
Esto proporciona capacidad suficiente para gestionar cientos de solicitudes concurrentes sin que el propio marco de pruebas se convierta en un cuello de botella. El marco está diseñado para ser configurable, lo que le permite probar diferentes niveles de concurrencia, patrones de solicitud y configuraciones de modelo con una metodología coherente.
El núcleo de nuestro marco de pruebas es la función call_chat, que gestiona las llamadas individuales a la API de AWS Bedrock mientras realiza un seguimiento de las métricas de tiempo precisas:
async def call_chat(chat, prompt):
“””
Increments the counter, records the start time, makes a synchronous API call in a separate thread,
then records the end time and decrements the counter before returning the parsed result
with the request start and end times added.
“””
global active_invoke_calls
async with active_invoke_lock:
active_invoke_calls += 1
try:
# Record the start time before calling the API.
request_start = datetime.now()
result = await asyncio.to_thread(chat.invoke_stream_parsed, prompt)
# Record the end time after the call completes.
request_end = datetime.now()
# Add the start and end times to the result.
result[‘request_start’] = request_start.isoformat()
result[‘request_end’] = request_end.isoformat()
return result
finally:
async with active_invoke_lock:
active_invoke_calls -= 1
Esta función proporciona varias capacidades críticas:
Nuestra función run_all_tests sirve como orquestador para todo el proceso de prueba:
async def run_all_tests(
chat,
prompt,
n_runs=60,
num_calls=40,
use_logger=True,
schedule_mode=”interval”,
batch_interval=1.0
):
# Implementation handles scheduling based on the selected mode
# Collects and processes results
# Returns structured data for analysis
La función run_all_tests lanza varios lotes de llamadas de acuerdo con el modo de programación especificado:
Al mantener este enfoque de orquestación unificado, garantizamos una metodología de prueba coherente en diferentes modelos y configuraciones, lo que permite realizar comparaciones válidas.
Para evaluar eficazmente el rendimiento de LLM, debe realizar un seguimiento de las métricas correctas. En esta sección se exploran las métricas esenciales que proporcionan información significativa sobre las características de rendimiento de sus modelos de AWS Bedrock.
Al evaluar los modelos fundacionales, varias métricas son particularmente relevantes:
Estas métricas se recopilan para cada solicitud y luego se agregan para el análisis.
Para calcular los tokens por segundo (TPS), utilizamos la inversa del tiempo por token de salida:
tokens_per_second = 1/time_per_output_token
Los TPS determinan cuántos tokens puede generar el modelo por segundo. Los valores más altos indican velocidades de generación más rápidas.
Nuestro marco calcula automáticamente las distribuciones estadísticas para estas métricas, lo que le permite comprender no solo el rendimiento promedio, sino también la varianza y los valores atípicos:
tps_metric = “tokens_per_second”
mean_val = df[tps_metric].mean()
median_val = df[tps_metric].median()
min_val = df[tps_metric].min()
max_val = df[tps_metric].max()
Estas estadísticas de resumen revelan la estabilidad y la coherencia del rendimiento de su modelo. Una gran diferencia entre la media y la mediana podría indicar un rendimiento sesgado, mientras que una alta varianza entre los valores mínimo y máximo sugiere un rendimiento inestable.
Los datos sin procesar por sí solos no son suficientes para obtener información práctica de las pruebas de rendimiento. Las técnicas de visualización eficaces transforman los patrones de rendimiento complejos en representaciones visuales fáciles de entender que resaltan las tendencias, las anomalías y las oportunidades de optimización.
Nuestro marco incluye funciones de visualización especializadas que proporcionan múltiples perspectivas sobre los datos de rendimiento:
La función plot_all_metrics crea un panel de control consolidado con múltiples visualizaciones:
def plot_all_metrics(df, n_runs, metrics=None):
“””
Creates one figure with 8 subplots using a subplot_mosaic layout “ABC;DEF;GGI”:
– 6 histograms/kde for the given metrics (A-F).
– 1 histogram/kde for tokens_per_second specifically (G).
– 1 boxplot for tokens_per_second (I).
A suptitle at the top includes model/run details, read from the df:
– df[‘model_id’]
– df[‘max_tokens’]
– df[‘temperature’]
– df[‘performance’]
– df[‘num_concurrent_calls’]
– Number of samples (rows in df).
“””Esta función genera un informe visual completo que incluye:
Las visualizaciones están dispuestas en un diseño de cuadrícula cuidadosamente diseñado que facilita la comparación entre métricas al tiempo que mantiene la claridad visual (véase la Figura 1).
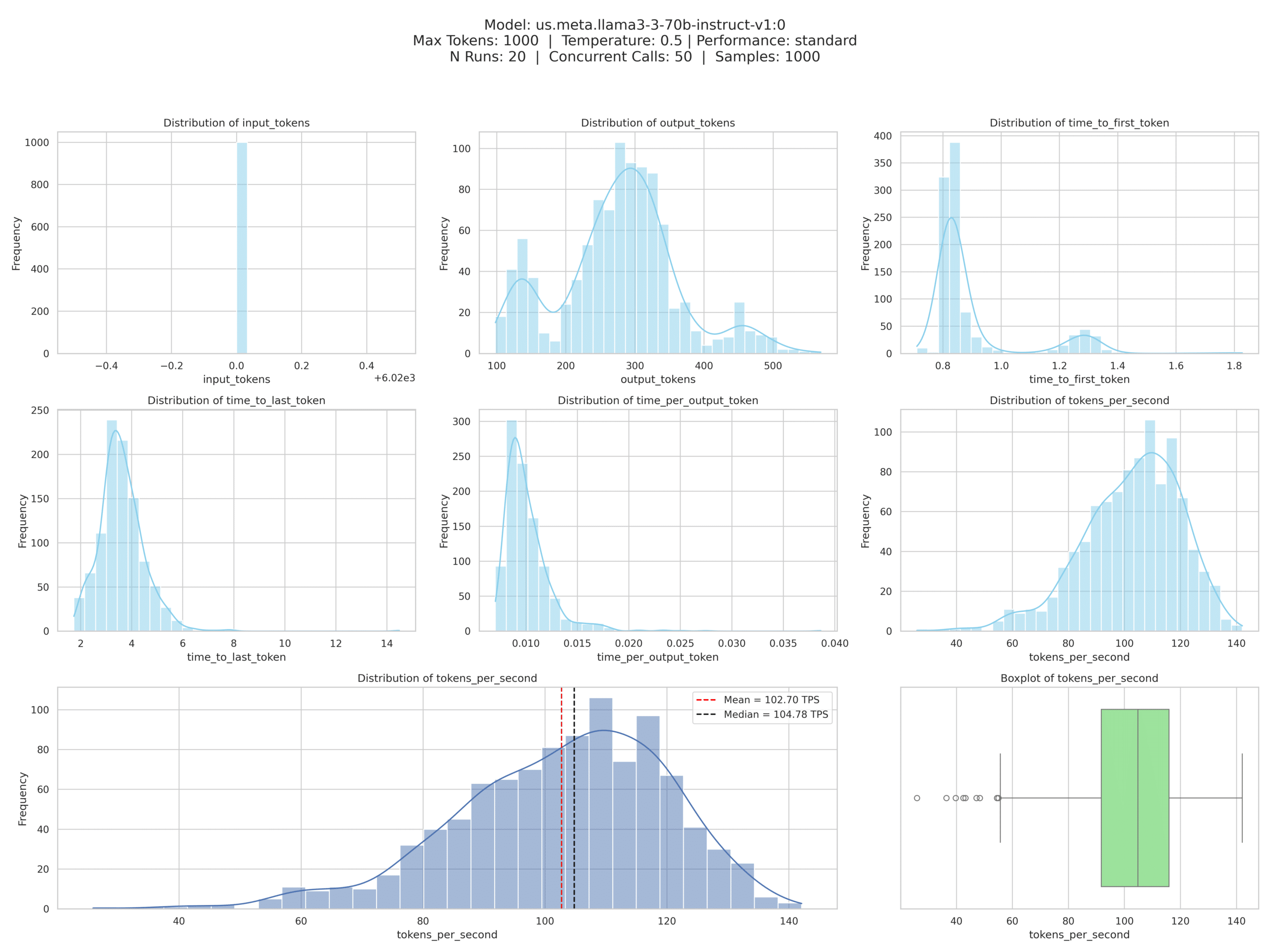
La función plot_tokens_and_calls proporciona dos perspectivas críticas:
def plot_tokens_and_calls(df, df_calls, xlim_tps=None):
# Creates a figure with two subplots
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(25, 6))
# First subplot: Histogram of tokens_per_second
# …
# Second subplot: Concurrency over time
# …
Esta visualización proporciona dos perspectivas críticas:
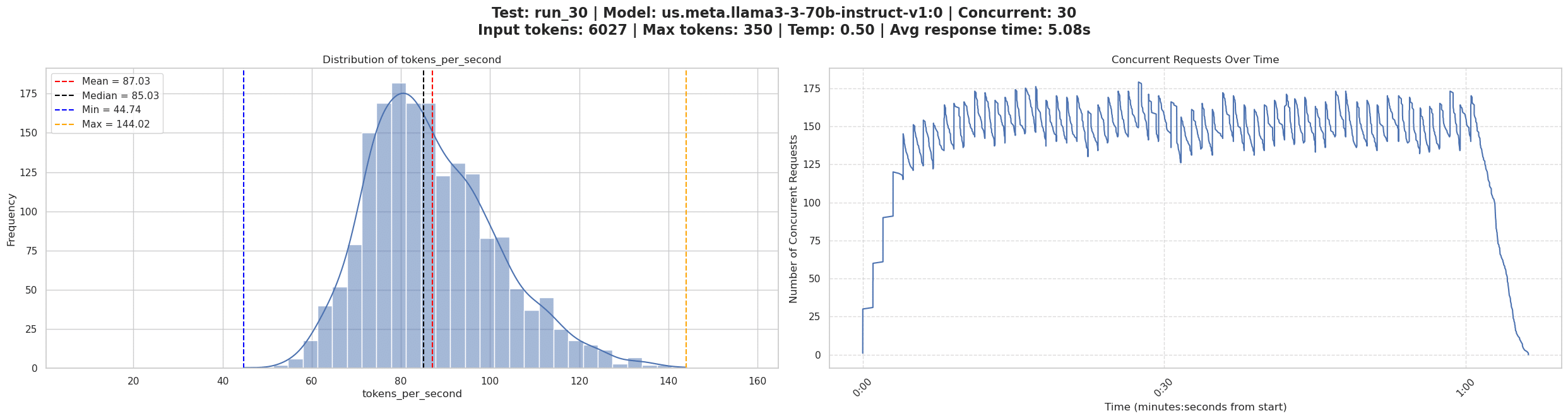
El subgráfico izquierdo de la Figura 2 revela el patrón de distribución del rendimiento. Un pico estrecho y alto indica un rendimiento constante, mientras que una distribución amplia y más plana sugiere un rendimiento variable. Las líneas de referencia verticales ayudan a identificar rápidamente las estadísticas clave:
El subgráfico derecho realiza un seguimiento de la concurrencia a lo largo del tiempo, revelando cómo el sistema gestionó el patrón de carga. Esto ayuda a identificar si la prueba alcanzó los niveles de concurrencia previstos y los mantuvo durante toda la duración de la prueba.
Para un análisis exhaustivo en múltiples ejecuciones de prueba, utilizamos una función mejorada que genera informes consolidados:
def create_all_plots_and_summary(df_dict, calls_dict, time_freq=’30S’):
# Calculate global min/max for consistent plotting
global_min, global_max = get_min_max_tokens_per_second(*df_dict.values())
# Generate visualizations and compile summary statistics
summary_stats = {}
for run_name in df_dict.keys():
# Extract metrics and create visualizations
# …
# Calculate concurrency metrics from events
# …
# Collect summary statistics
summary_stats[run_name] = {
‘Model’: model_id,
‘Concurrent Calls’: int(num_concurrent),
‘Input Tokens’: input_tokens,
‘Average output Tokens’: df[‘output_tokens’].mean(),
‘Temperature’: temperature,
‘Average TPS’: df[‘tokens_per_second’].mean(),
‘Median TPS’: df[‘tokens_per_second’].median(),
‘Min TPS’: df[‘tokens_per_second’].min(),
‘Max TPS’: df[‘tokens_per_second’].max(),
‘Avg Response Time (s)’: avg_ttlt,
‘Average Concurrent Requests’: avg_concurrency,
‘Max Concurrent Requests’: max_concurrency
}
# Create summary dataframe
summary_df = pd.DataFrame.from_dict(summary_stats, orient=’index’)
return figures, summary_df
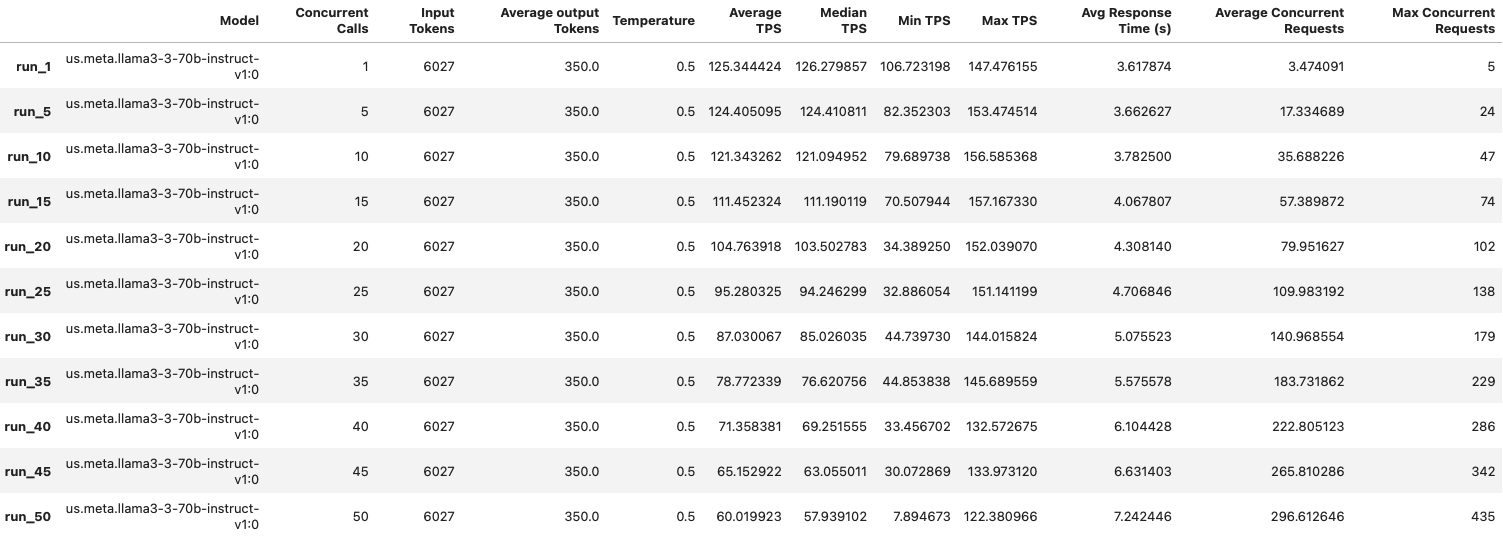
Esta función genera visualizaciones individuales para cada ejecución de prueba y una tabla resumen que permite una fácil comparación entre diferentes niveles de concurrencia. La tabla resumen se vuelve particularmente valiosa al optimizar para métricas específicas como tokens por segundo promedio o tiempo de respuesta (véase la Figura 3).
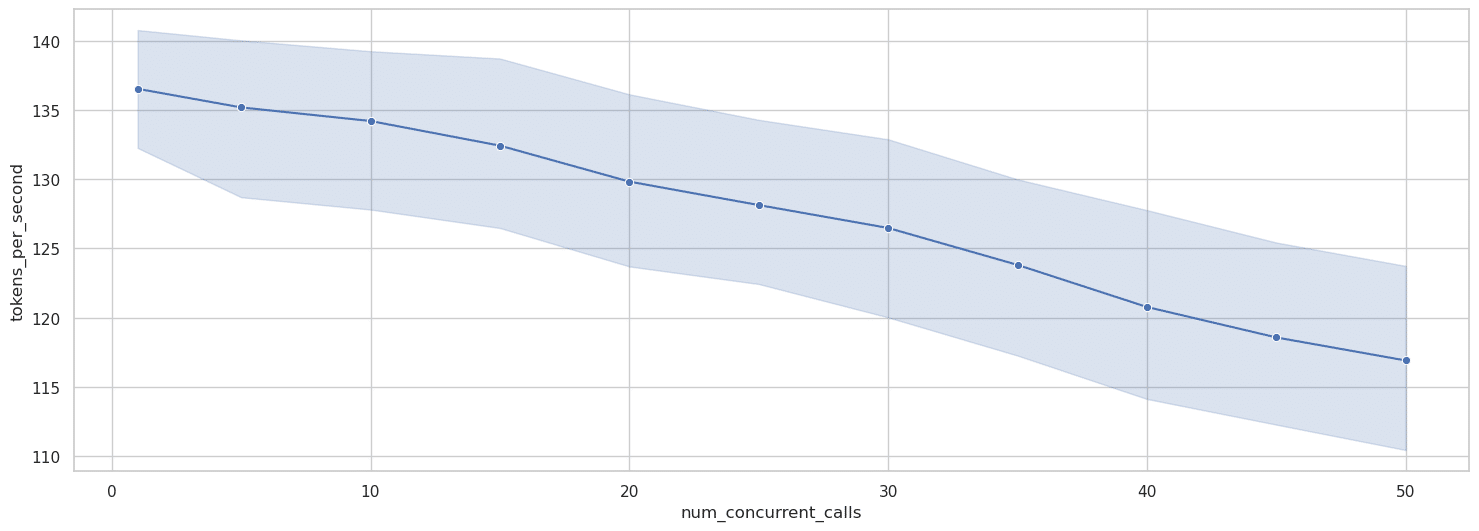
Para visualizar la relación entre los niveles de concurrencia y las métricas de rendimiento, creamos gráficos de líneas estadísticas con intervalos de confianza. Estos gráficos revelan tanto la tendencia central como la variabilidad del rendimiento a medida que aumenta la concurrencia (véase la Figura 4).
# Set a nice style
sns.set(style=”whitegrid”)
# Create statistical plots with advanced features
sns.lineplot(data=df,
x=”num_concurrent_calls”,
y=”tokens_per_second”,
marker=”o”,
estimator=”median”,
errorbar=(“pi”, 50))
Con nuestra metodología y métricas establecidas, ahora podemos examinar los datos de rendimiento reales de los modelos AWS Bedrock. Esta sección presenta hallazgos detallados de nuestras pruebas utilizando el modelo LLaMA 3.3 70B Instruct, revelando patrones importantes en cómo el modelo escala con solicitudes concurrentes. Estos conocimientos van más allá de los números brutos para identificar puntos operativos óptimos y posibles cuellos de botella.
Para nuestras pruebas con Llama 3 en AWS Bedrock, utilizamos la siguiente configuración:
model_id=”us.meta.llama3-3-70b-instruct-v1:0″
max_tokens=350
temperature=0.5
performance=”standard”
max_pool_connections = 20000
region_name = “us-west-2”
Utilizamos un mensaje filosófico simple para nuestras pruebas: “¿Cuál es el significado de la vida?”
Examinemos primero el rendimiento de una sola solicitud para establecer nuestra línea de base:
{‘response_text’: “The question of the meaning of life…”,
‘input_tokens’: 43,
‘output_tokens’: 350,
‘time_to_first_token’: 0.38360680200275965,
‘time_to_last_token’: 2.9637207640043925,
‘time_per_output_token’: 0.007392876681953103,
‘model_id’: ‘us.meta.llama3-3-70b-instruct-v1:0’,
‘provider’: ‘Bedrock:us-west-2’}
A partir de esta única invocación, podemos extraer varias métricas clave de rendimiento:
Estas métricas de línea de base representan el rendimiento óptimo sin carga concurrente y sirven como nuestro punto de referencia para evaluar cómo cambia el rendimiento bajo una concurrencia creciente.
Para evaluar exhaustivamente cómo escala el rendimiento con la concurrencia, probamos una amplia gama de niveles de concurrencia de 1 a 50 solicitudes concurrentes. Para cada nivel, ejecutamos 60 iteraciones de prueba para garantizar la significación estadística de nuestros resultados:
calls = [1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
# Run tests for num_calls
for num_calls in calls:
# Run 60 requests at each concurrency level
df_run, df_calls = await run_all_tests(
chat=my_chat,
prompt=my_prompt,
n_runs=60,
num_calls=num_calls,
use_logger=False,
schedule_mode=”interval”,
batch_interval=1.0
)
Después de recopilar datos en todos los niveles de concurrencia, observamos una amplia gama de rendimiento:
Minimum tokens_per_second: 9.23
Maximum tokens_per_second: 187.30
Este rango significativo de ~9 a ~187 tokens por segundo demuestra cómo puede variar drásticamente el rendimiento bajo diferentes condiciones de carga.
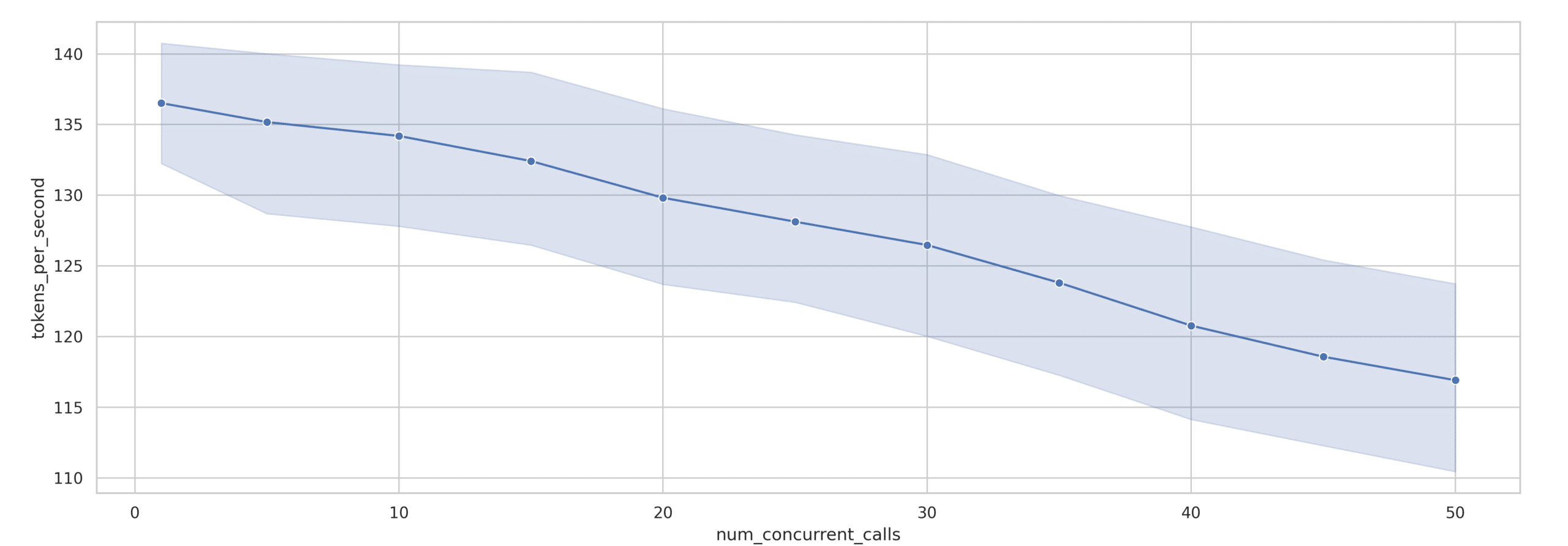
El gráfico de la Figura 5 muestra la relación entre el nivel de concurrencia (eje x) y los tokens por segundo (eje y), con la línea azul representando el rendimiento medio y el área sombreada mostrando el intervalo de confianza del 50%. Esta visualización revela varios patrones clave:
Cuando combinamos estos datos de rendimiento por solicitud con el hecho de que el rendimiento total es igual al rendimiento por solicitud multiplicado por la concurrencia, podemos derivar el rendimiento total del sistema:
Este análisis revela que, si bien el rendimiento de la solicitud individual disminuye con la concurrencia, el rendimiento total del sistema continúa aumentando, aunque con rendimientos decrecientes en los niveles de concurrencia más altos.
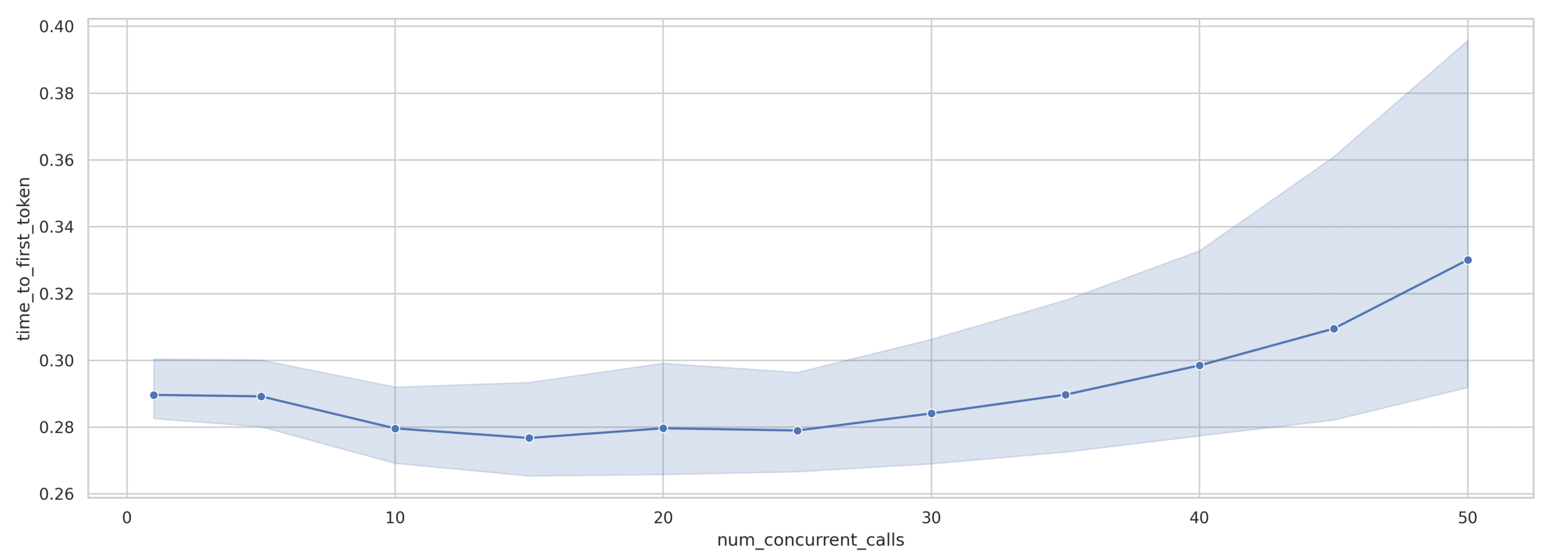
Para las consideraciones de la experiencia del usuario, el patrón TTFT (capacidad de respuesta) es particularmente interesante. El gráfico de la Figura 6 muestra que el TTFT en realidad permanece notablemente estable en la mayoría de los niveles de concurrencia, contrariamente a lo que podría esperarse:
Esto representa solo un aumento de aproximadamente el 17% en el tiempo de respuesta inicial desde el nivel de concurrencia 1 al 50, lo cual es sorprendentemente eficiente. La ampliación del intervalo de confianza en los niveles de concurrencia más altos indica una mayor variabilidad en el TTFT, lo que sugiere que, si bien el rendimiento medio sigue siendo relativamente bueno, algunas solicitudes pueden experimentar retrasos más significativos.
Para comprender mejor cómo el tamaño de la entrada afecta las características de rendimiento, realizamos un segundo conjunto de experimentos utilizando un mensaje significativamente más grande: un marco de escritura creativa detallado para generar una narrativa épica de fantasía. Este mensaje pesó 6.027 tokens, en comparación con solo 43 tokens en nuestro mensaje inicial.
Aquí está el rendimiento de referencia para una sola solicitud con este mensaje grande:
{‘response_text’: ‘This prompt is a comprehensive and detailed guide for generating an epic narrative titled “The Chronicles of Eldrath: A Saga of Light and Shadow.”…’,
‘input_tokens’: 6027,
‘output_tokens’: 350,
‘time_to_first_token’: 0.9201213920023292,
‘time_to_last_token’: 3.2595945539942477,
‘time_per_output_token’: 0.006703361495678849,
‘model_id’: ‘us.meta.llama3-3-70b-instruct-v1:0’,
‘provider’: ‘Bedrock:us-west-2’}
Observaciones clave de la solicitud única de mensaje grande:
Esta ligera mejora en la velocidad de generación de tokens con mensajes más grandes en niveles de concurrencia bajos es interesante, pero probablemente podría atribuirse a la variabilidad natural del servicio en lugar de representar una ventaja de rendimiento consistente. Lo que es más significativo es cómo cambian estas características de rendimiento bajo una concurrencia creciente, donde vemos una divergencia clara y sustancial entre mensajes pequeños y grandes.
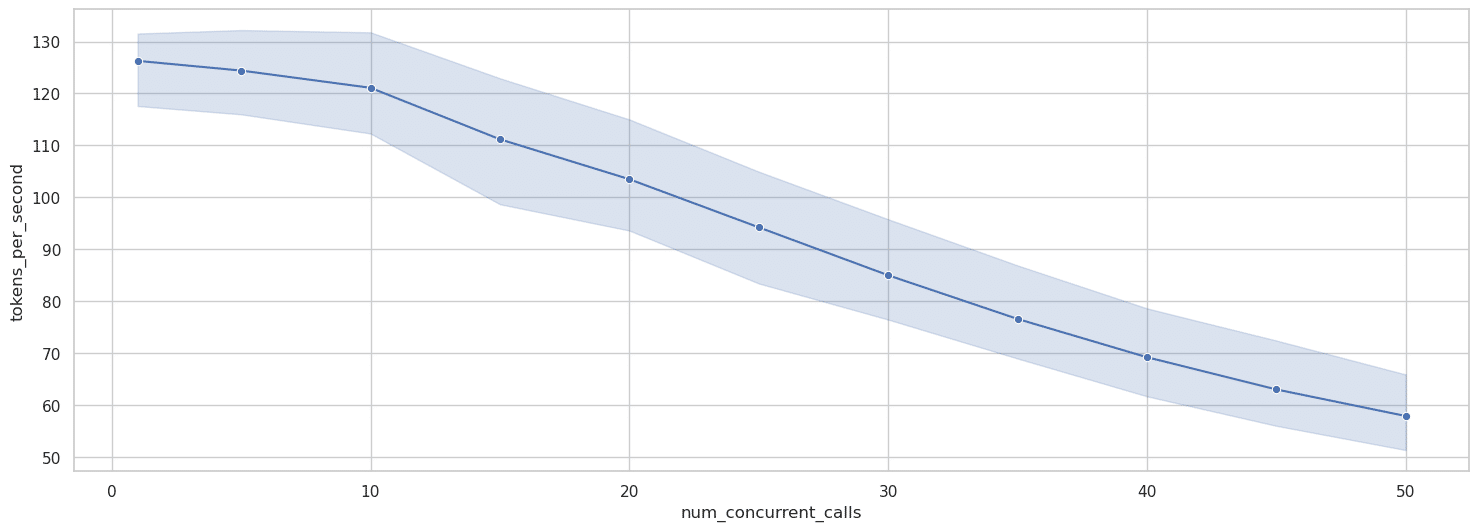
Al escalar la concurrencia con el mensaje grande, el patrón cambia significativamente, como se muestra en la Figura 7:
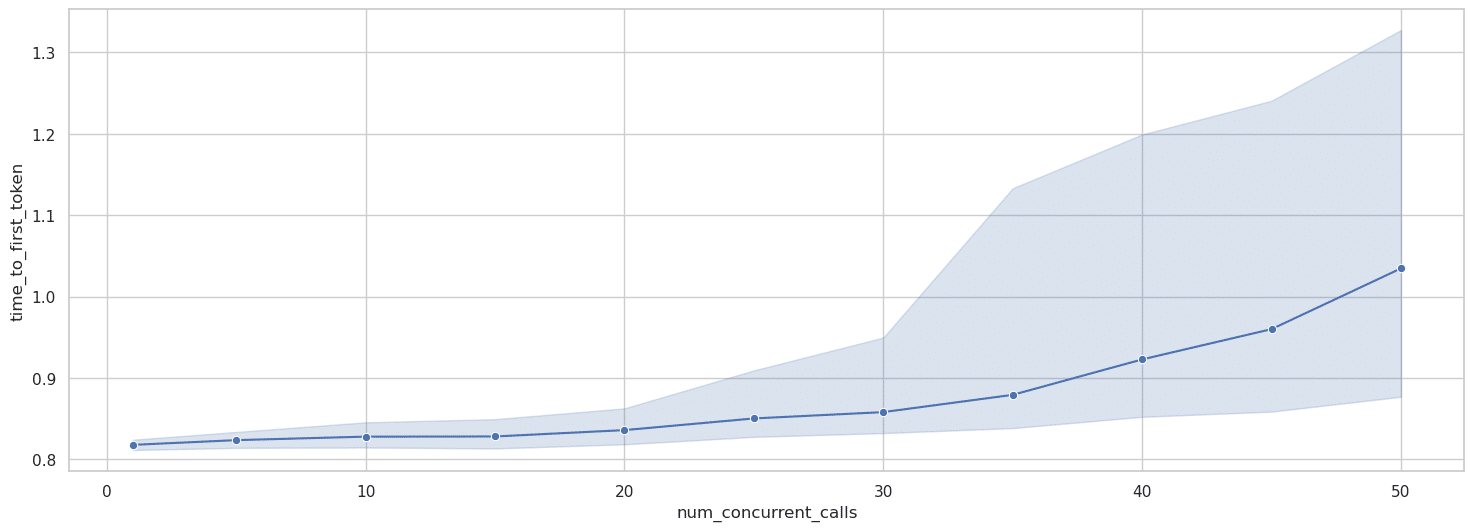
Mirando específicamente el comportamiento del TTFT con el mensaje grande, el gráfico recién proporcionado (Figura 8) revela un patrón de degradación mucho más pronunciado en comparación con el mensaje pequeño:
Lo más notable es que el intervalo de confianza se amplía significativamente en los niveles de concurrencia más altos, con el límite superior superando los 1,3 segundos en el nivel de concurrencia 50. Esto indica que, si bien el TTFT medio aumenta en aproximadamente un 25% desde los niveles 1 a 50, algunos usuarios pueden experimentar retrasos en la respuesta inicial que son más del 50% más largos que la línea de base.
Este perfil de degradación para TTFT con mensajes grandes es sustancialmente diferente de lo que observamos con mensajes pequeños, donde el TTFT permaneció relativamente estable hasta niveles de concurrencia mucho más altos. La degradación más temprana y pronunciada sugiere que AWS Bedrock prioriza diferentes aspectos del rendimiento al tratar con contextos de entrada grandes bajo carga.
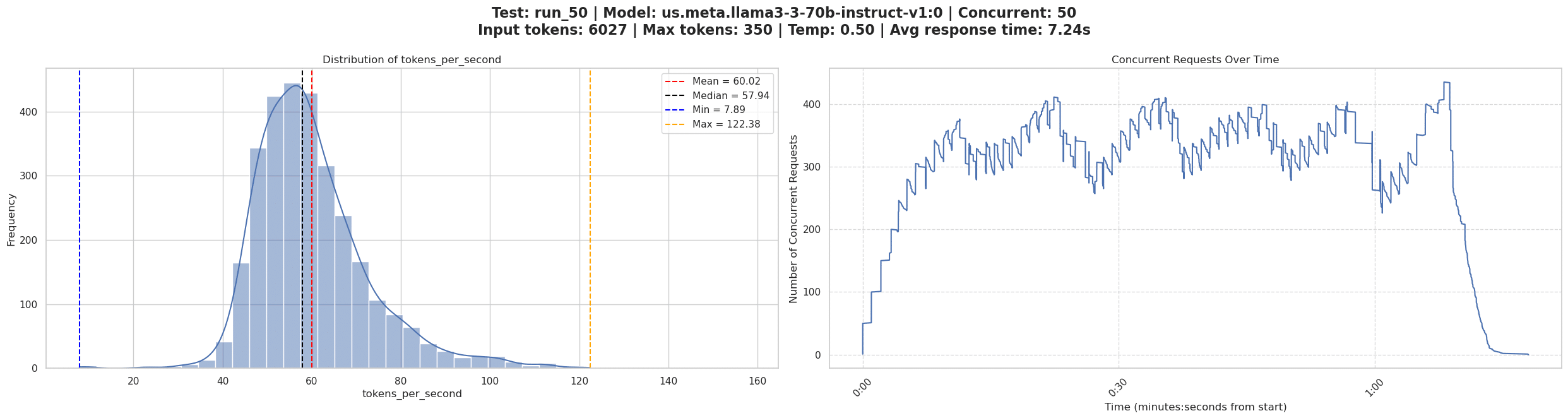
Al analizar el nivel de concurrencia de 50 con más detalle (Figura 8), el histograma de tokens por segundo muestra:
Esto representa un impacto en el rendimiento mucho más significativo que el observado con el mensaje pequeño, lo que demuestra que los contextos de entrada grandes no solo aumentan la latencia inicial, sino que también reducen la capacidad del sistema para gestionar eficientemente las solicitudes concurrentes.
Al calcular el rendimiento total del sistema con el mensaje grande:
Esto muestra que los rendimientos decrecientes se establecen mucho antes: el sistema logra solo ganancias de rendimiento mínimas más allá del nivel de concurrencia 30. El lado derecho de la Figura 8 ilustra la concurrencia real lograda durante la prueba, mostrando fluctuaciones entre 250-400 solicitudes concurrentes a medida que el sistema procesa la carga de trabajo.
Al comparar el rendimiento total del sistema entre mensajes pequeños y grandes en diferentes niveles de concurrencia, observamos diferencias sorprendentes en los patrones de escalado:
| Nivel de concurrencia | Rendimiento con prompt pequeño | Rendimiento con prompt grande | Diferencia (%) |
| 1 | ~136 tokens/seg | ~126 tokens/seg | -7.4% |
| 10 | ~1,340 tokens/seg | ~1,210 tokens/seg | -9.7% |
| 30 | ~3,780 tokens/seg | ~2,550 tokens/seg | -32.5% |
| 50 | ~5,850 tokens/seg | ~2,900 tokens/seg | -50.4% |
En niveles de concurrencia bajos (1-10), la diferencia en el rendimiento total del sistema es relativamente pequeña, solo alrededor del 7-10% más bajo con mensajes grandes. Sin embargo, esta brecha se amplía drásticamente a medida que aumenta la concurrencia. En el nivel de concurrencia 30, el sistema de mensajes grandes logra solo alrededor de dos tercios del rendimiento del sistema de mensajes pequeños. En el nivel de concurrencia 50, la diferencia se vuelve aún más pronunciada, con el sistema de mensajes grandes entregando solo la mitad del rendimiento del sistema de mensajes pequeños.
Esta comparación revela varios conocimientos clave:
El enfoque de prueba de rendimiento descrito en este blog proporciona información valiosa sobre cómo se comportan los modelos fundacionales de AWS Bedrock bajo diversas condiciones de carga. Al medir sistemáticamente métricas clave como tokens por segundo, tiempos de respuesta e impactos de concurrencia, hemos establecido una comprensión integral que puede informar directamente las implementaciones de producción.
Las cuotas predeterminadas de AWS Bedrock (800 RPM y 600.000 TPM) restringirían significativamente la escalabilidad demostrada en nuestras pruebas. Nuestras pruebas utilizaron cuotas elevadas especialmente otorgadas de 6.000 RPM y 36 millones de TPM, lo que requirió una justificación formal y no está disponible automáticamente para los clientes de AWS. Sin estas asignaciones especiales, la concurrencia máxima alcanzable sería considerablemente menor. Esto destaca por qué la gestión de cuotas no es simplemente una preocupación operativa, sino una consideración arquitectónica fundamental que debe abordarse al principio de su proceso de diseño de aplicaciones.
Al planificar los aumentos de cuota, es esencial comprender que la relación entre los límites de cuota y el rendimiento real no siempre es sencilla. Asumiendo una correspondencia lineal entre las solicitudes concurrentes y el rendimiento de tokens (que, como se ve en el blog, no siempre es cierto dependiendo del tamaño del mensaje), las cuotas más altas teóricamente deberían permitir proporcionalmente más solicitudes concurrentes. Sin embargo, nuestras pruebas revelaron que el rendimiento comienza a degradarse de forma no lineal con mensajes grandes más allá de ciertos umbrales de concurrencia, lo que significa que simplemente aumentar estas cuotas puede no generar mejoras de rendimiento proporcionales en todos los escenarios.
⚠️ Este último punto se basa en patrones observados y sigue siendo algo especulativo, ya que no tenemos visibilidad exacta de cómo la infraestructura de AWS Bedrock gestiona estos escenarios entre bastidores o cómo se asignan los recursos a través de diferentes patrones de solicitud a escala.
Al realizar pruebas de rendimiento similares con sus mensajes y patrones de respuesta reales, puede:
Las pruebas de rendimiento conectan los valores de cuota abstractos con la planificación de la capacidad en el mundo real. A través de la medición y el análisis sistemáticos del rendimiento del modelo en diversas condiciones, obtendrá información que puede servir de base para las decisiones, la planificación de la capacidad y la gestión de cuotas, lo que en última instancia conducirá a implementaciones de LLM más eficientes y eficaces.
La implementación completa del marco de pruebas que se analiza en este blog está disponible en GitHub:
El repositorio contiene la base de código completa de Python, las utilidades de visualización y los cuadernos de ejemplo para guiarle en la realización de sus propias pruebas de rendimiento utilizando los modelos básicos de AWS Bedrock.