
TL;DR
|
Una previsión de Gartner predice que, para 2027, el 60% de las organizaciones no logrará obtener todo el valor de sus iniciativas de IA, no por falta de herramientas avanzadas, sino debido a marcos de gobernanza de datos fragmentados o ineficaces.
Esta idea se aplica mucho más allá de la IA. Las mismas deficiencias de gobernanza son una razón importante por la que muchas estrategias de protección de datos, incluido el enmascaramiento de datos, no cumplen con las expectativas.
El enmascaramiento de datos a menudo se trata como una tarea de marcar una casilla: enmascarar los campos confidenciales, compartir el conjunto de datos y seguir adelante. Pero, en la práctica, el proceso es mucho más complejo.
Identificar los datos confidenciales, preservar la integridad referencial, admitir arquitecturas multi-nube y mantener el rendimiento del enmascaramiento requieren algo más que herramientas. Exigen estructura, estrategia y supervisión continua.
En este blog, analizamos más de cerca los 15 principales desafíos de enmascaramiento de datos a los que se enfrentan las organizaciones en la actualidad. Tanto si es responsable del cumplimiento, el desarrollo o la arquitectura de datos, este desglose le ayudará a detectar los errores comunes y a comprender cómo implementar un enmascaramiento de datos que sea seguro, escalable y realmente eficaz.
Los fundamentos del enmascaramiento de datos: cómo funciona y dónde se aplica

El enmascaramiento de datos es el proceso de sustituir los datos reales y confidenciales por valores modificados que conservan el mismo formato y estructura, pero que ya no son identificables. Esta técnica ayuda a proteger la información confidencial, como la información de identificación personal (PII), la información sanitaria protegida (PHI), los datos de pago y los datos empresariales de propiedad exclusiva, del acceso no autorizado.
El objetivo principal del enmascaramiento de datos es proteger los datos confidenciales, manteniéndolos utilizables para fines como las pruebas de software, la formación de usuarios, el análisis o la externalización, donde el acceso a los datos de producción reales plantea un riesgo de seguridad o cumplimiento.
Función en la protección de datos
El enmascaramiento de datos garantiza que los datos confidenciales no se expongan en entornos que no son de producción o durante el intercambio de datos. Apoya el cumplimiento normativo (por ejemplo, RGPD, HIPAA, PCI DSS), la mitigación de riesgos minimizando la exposición de los datos y el intercambio seguro de datos dentro y fuera de la organización. A diferencia del cifrado, los datos enmascarados no requieren una clave para invertir la transformación, lo que los hace inherentemente más seguros para su uso fuera de entornos seguros.
Tipos de enmascaramiento de datos
1. Enmascaramiento de datos estáticos (SDM)
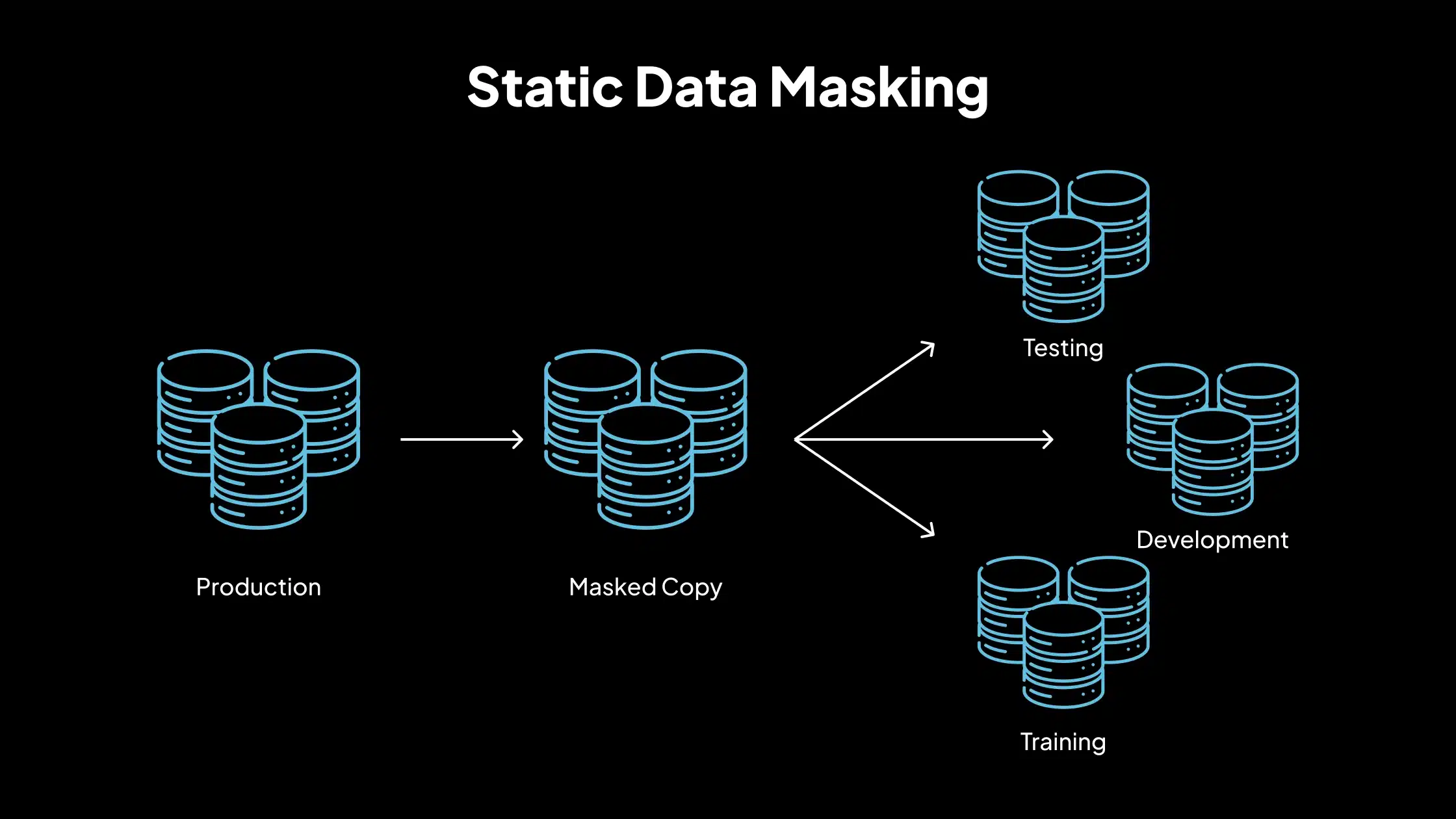
El enmascaramiento estático de datos implica la creación de una versión saneada del conjunto de datos original. Los datos se enmascaran en reposo y se almacenan como una copia separada. Este método se utiliza para entornos de desarrollo y pruebas, escenarios de formación e intercambio de datos con proveedores externos. Una vez enmascarados, los datos no cambian y no pueden volver a su forma original.
2. Enmascaramiento de datos dinámicos (DDM)
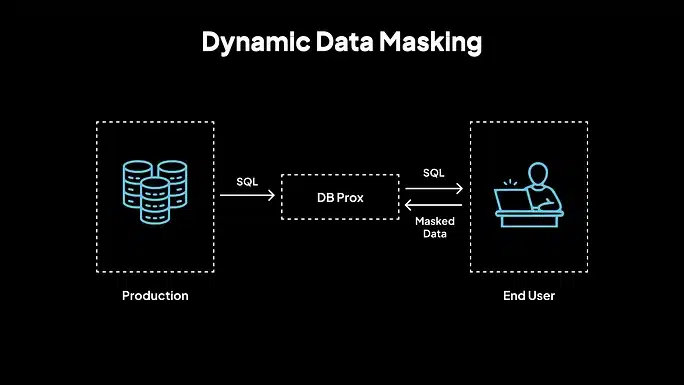
El enmascaramiento dinámico se produce en tiempo de ejecución. Los datos reales permanecen inalterados en la base de datos, pero los usuarios con acceso limitado solo ven los valores enmascarados al consultar los datos. Este método es adecuado para el control de acceso basado en roles, las plataformas de atención al cliente y los paneles de control en vivo donde no se requiere acceso completo. El DDM se basa en políticas y se aplica en tiempo real en función de los privilegios del usuario.
3. Enmascaramiento de datos determinista
El enmascaramiento determinista garantiza que la misma entrada siempre dé como resultado la misma salida enmascarada. Por ejemplo, “Amanda Smith” siempre se convertirá en “David Jones” en todos los registros y bases de datos. Este tipo es adecuado cuando se mantiene la integridad referencial entre las tablas y se admiten análisis que se basan en patrones de datos coherentes. Permite que los conjuntos de datos enmascarados conserven las relaciones lógicas al tiempo que garantiza la privacidad.
4. Enmascaramiento de datos sobre la marcha
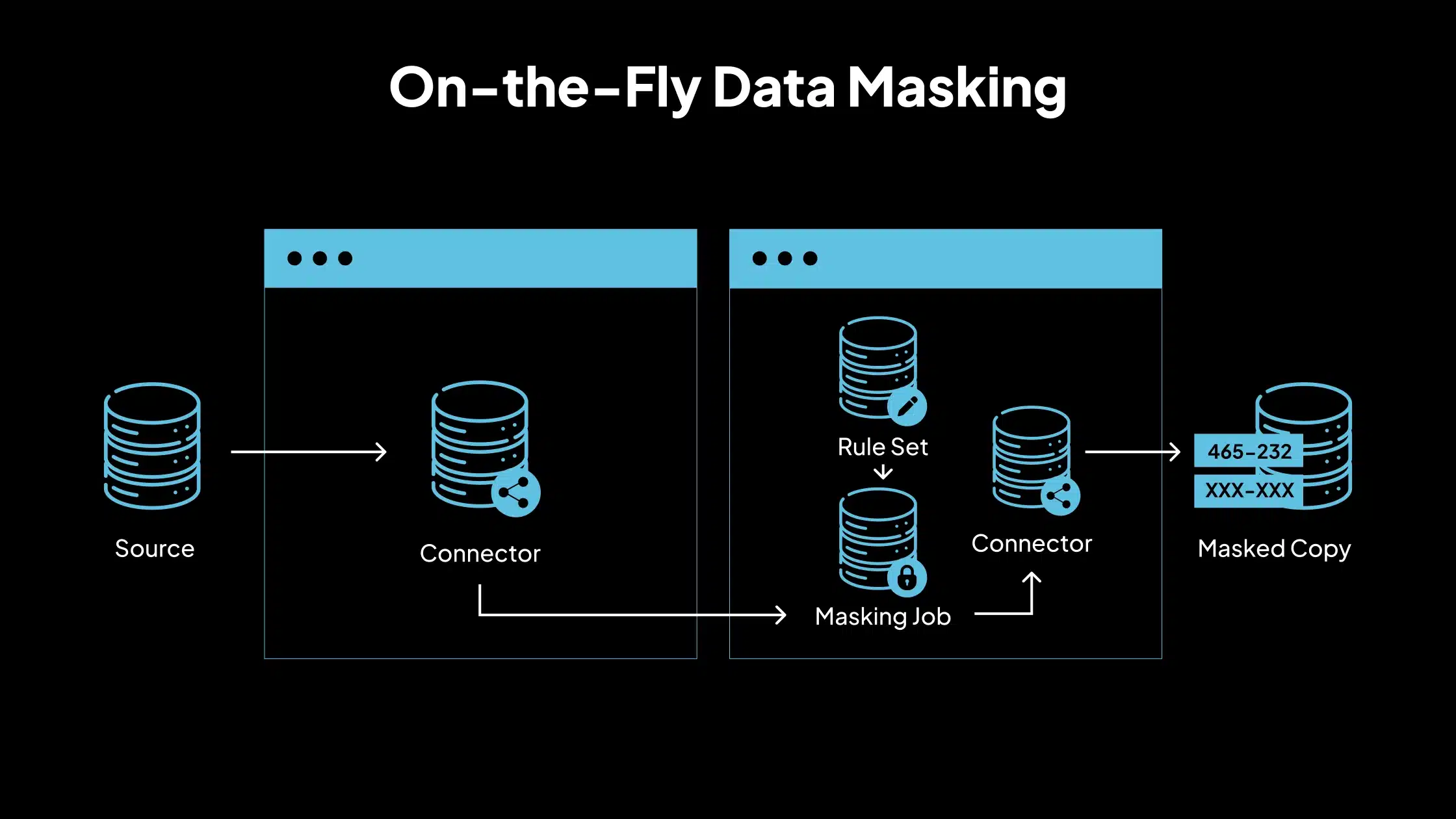
El enmascaramiento sobre la marcha transforma los datos en tránsito, antes de que lleguen al entorno de destino. No almacena los datos enmascarados de forma permanente, sino que los procesa a medida que se mueven. Este enfoque es el mejor para las canalizaciones de integración continua/entrega continua (CI/CD), la replicación de datos en tiempo real y la migración de datos a entornos menos seguros. Ofrece flexibilidad sin dejar atrás los datos enmascarados.
Los 15 principales desafíos de enmascaramiento de datos que toda organización debe comprender
A continuación, se muestra la lista de los 15 principales desafíos de enmascaramiento de datos a los que se enfrentan comúnmente las organizaciones al implementar estrategias de protección de datos seguras y escalables.
1. Identificación y clasificación de datos confidenciales
Uno de los desafíos más fundamentales en el enmascaramiento de datos es identificar y clasificar con precisión los datos confidenciales en diversos sistemas. Las organizaciones a menudo gestionan datos almacenados en una variedad de formatos, estructurados (por ejemplo, bases de datos relacionales), semiestructurados (por ejemplo, JSON, XML) y no estructurados (por ejemplo, documentos, correos electrónicos, registros). La información confidencial, como nombres, números de la seguridad social, datos de tarjetas de crédito y registros médicos, puede existir en todos estos formatos, a veces en lugares inesperados.
En los sistemas grandes o heredados, los silos de datos, los esquemas incoherentes y los campos no documentados complican aún más el proceso. Sin una clasificación precisa, existe el riesgo de no enmascarar los datos confidenciales (lo que conlleva riesgos de cumplimiento y violaciones de datos) o de enmascarar los datos no confidenciales (lo que afecta innecesariamente a las aplicaciones posteriores).
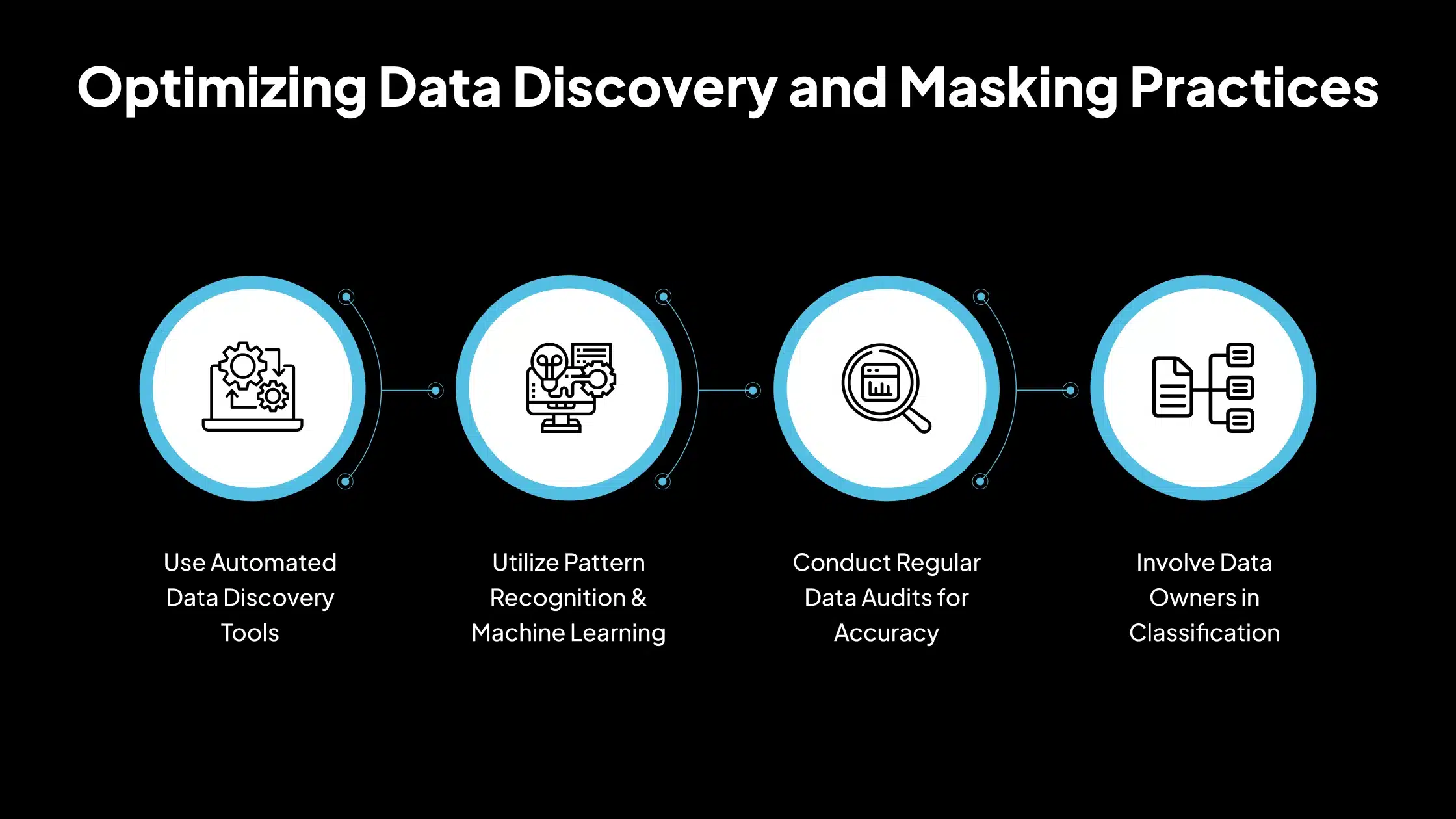
Las organizaciones pueden mitigar este desafío mediante el uso de herramientas automatizadas de descubrimiento de datos que utilizan el reconocimiento de patrones, el aprendizaje automático o la clasificación basada en reglas para escanear y etiquetar los datos confidenciales. Las auditorías de datos periódicas, el análisis de metadatos y la participación de los propietarios de los datos en el proceso de clasificación también mejoran la precisión. El establecimiento de un inventario de datos centralizado o un catálogo de datos garantiza la visibilidad en todos los entornos.
2. Encontrar el equilibrio adecuado: privacidad frente a utilidad
Otro desafío fundamental es equilibrar la protección de la privacidad con la usabilidad de los datos enmascarados. Si los datos están sobreenmascarados, pierden los atributos esenciales necesarios para las pruebas, el análisis o el desarrollo válidos. Por ejemplo, reemplazar todos los nombres con “X” o convertir todas las fechas a un valor fijo puede dar como resultado datos que no reflejen los patrones del mundo real. Por el contrario, el enmascaramiento insuficiente expone los datos confidenciales a usuarios no autorizados, lo que anula el propósito del enmascaramiento y aumenta el riesgo normativo y de reputación.
Este equilibrio se vuelve especialmente importante en entornos donde se necesitan datos de prueba realistas para validar el comportamiento de la aplicación, detectar problemas de rendimiento o ejecutar modelos de aprendizaje automático.
Para lograr este equilibrio, las organizaciones deben utilizar técnicas de enmascaramiento sensibles al contexto, como el enmascaramiento que preserva el formato, el determinista o el estadístico. Estos enfoques mantienen el formato y la lógica de los datos sin exponer los valores reales. Los controles de acceso basados en roles (RBAC) también se pueden implementar junto con el enmascaramiento para garantizar que solo los usuarios adecuados puedan ver o interactuar con los datos confidenciales.
3. Mantenimiento de la integridad referencial entre sistemas
Cuando se enmascaran los datos confidenciales, uno de los mayores obstáculos técnicos es mantener la integridad referencial, la relación lógica entre los datos en diferentes tablas, bases de datos o sistemas.
Por ejemplo, si un ID de cliente se enmascara en una tabla “Clientes”, pero no se enmascara de forma coherente en la tabla “Pedidos” correspondiente, se rompe la conexión entre los clientes y sus pedidos. Esta incoherencia puede provocar errores en la aplicación, análisis inexactos o fallos en las integraciones del sistema.
El mantenimiento de estas relaciones es especialmente complejo en entornos con restricciones de clave externa, bases de datos distribuidas o canalizaciones de almacenamiento de datos donde convergen datos de múltiples fuentes.
El uso de técnicas de enmascaramiento determinista puede ayudar a mantener valores enmascarados coherentes en todas las instancias de los mismos datos. Por ejemplo, garantizar que el mismo nombre o ID siempre dé como resultado la misma salida enmascarada, independientemente de dónde aparezca, y preserve la integridad relacional. Las organizaciones también deben establecer políticas de enmascaramiento que se apliquen de forma coherente en todas las fuentes de datos y realizar pruebas para verificar que las relaciones permanezcan intactas después del enmascaramiento.
4. Gestión de diversos tipos y formatos de datos
Las organizaciones modernas trabajan con una amplia variedad de formatos de datos, que van desde bases de datos relacionales altamente estructuradas hasta datos semiestructurados como archivos JSON, y formatos no estructurados como archivos PDF, correos electrónicos, registros de chat y metadatos de imágenes. Cada formato requiere un enfoque diferente para identificar y enmascarar la información confidencial. Si bien los datos estructurados pueden permitir el enmascaramiento a nivel de columna, los datos semiestructurados y no estructurados a menudo implican el análisis de campos anidados o el uso del procesamiento del lenguaje natural para detectar contenido confidencial.
5. Escalado del enmascaramiento en entornos de alto volumen o Big Data
Cuando se trabaja con grandes conjuntos de datos, un problema común en las plataformas de big data y análisis, el escalado de los procesos de enmascaramiento de datos se convierte en un desafío importante. Los volúmenes masivos de datos, a menudo almacenados en sistemas distribuidos como Hadoop, Spark o lagos de datos en la nube, exigen un enmascaramiento de alto rendimiento que no retrase los flujos de trabajo ni afecte al rendimiento del sistema.
Es posible que las herramientas de enmascaramiento convencionales no estén optimizadas para tales entornos, lo que provoca un procesamiento lento, una sobrecarga de memoria o un enmascaramiento incompleto. Además, el proceso de enmascaramiento debe adaptarse a la ingesta constante de datos y a las actualizaciones en tiempo real sin crear cuellos de botella.
Las organizaciones pueden superar esto mediante el uso de motores de enmascaramiento paralelos o en memoria diseñados para un rendimiento de alta velocidad en todos los sistemas de datos distribuidos. Las soluciones de enmascaramiento nativas de la nube que se integran con plataformas de datos como AWS, Azure, o GCP también ofrecen una mejor escalabilidad. La incorporación del enmascaramiento al principio de la canalización ETL/ELT y el uso del enmascaramiento incremental para los datos modificados pueden mejorar aún más el rendimiento en escenarios de alto volumen.
6. Operación en entornos híbridos o de múltiples bases de datos
En muchas empresas, los datos se distribuyen a través de una combinación de sistemas locales, servicios en la nube y múltiples plataformas de bases de datos como PostgreSQL, MySQL, Oracle, SQL Server, o Snowflake. Cada sistema puede tener su esquema, controles de acceso y capacidades de enmascaramiento, o carecer de ellos por completo. La coordinación de un enmascaramiento de datos coherente en este panorama heterogéneo es compleja.
La falta de aplicación de políticas centralizadas puede conducir a resultados de enmascaramiento incoherentes, un mayor riesgo de exposición y una sobrecarga administrativa en el mantenimiento de múltiples conjuntos de herramientas y reglas.
Para abordar esto, las organizaciones deben adoptar plataformas de enmascaramiento de datos centralizadas que admitan la integración con varias fuentes de datos y permitan la gestión unificada de políticas. Estas plataformas pueden automatizar el enmascaramiento en todos los sistemas utilizando un único conjunto de reglas y proporcionar registros y controles centralizados para facilitar la supervisión del cumplimiento.
7. Impacto en el rendimiento y cuellos de botella del sistema
La aplicación del enmascaramiento de datos, especialmente en conjuntos de datos grandes o complejos, puede afectar al rendimiento de las bases de datos y las aplicaciones. Si las operaciones de enmascaramiento consumen muchos recursos o están mal optimizadas, pueden causar retrasos, aumentar los tiempos de procesamiento o degradar el rendimiento del entorno donde se ejecutan. Esto es particularmente problemático en los sistemas en vivo o en los procesos sensibles al tiempo, como las canalizaciones de análisis o las implementaciones de CI/CD.
En algunos casos, los trabajos de enmascaramiento de datos pueden bloquear tablas, agotar la memoria del sistema o interferir con otras tareas críticas, lo que provoca ralentizaciones operativas o interrupciones del servicio.
Para minimizar el impacto en el rendimiento, las organizaciones deben utilizar herramientas de enmascaramiento optimizadas para su entorno específico, como el enmascaramiento a nivel de columna o en el lugar para las bases de datos estructuradas, y el procesamiento por lotes para grandes volúmenes. También es aconsejable ejecutar trabajos de enmascaramiento durante las horas de menor actividad o en entornos de ensayo aislados.
8. Evolución de los datos y las reglas de enmascaramiento a lo largo del tiempo
A medida que los sistemas empresariales crecen y las regulaciones evolucionan, los modelos de datos a menudo cambian, se añaden nuevas tablas, se modifican las existentes y se introducen nuevos tipos de datos. Al mismo tiempo, los requisitos de cumplimiento y las políticas de seguridad internas pueden exigir actualizaciones sobre cómo se enmascaran los datos. Mantener las reglas de enmascaramiento actualizadas y aplicadas de forma coherente en todos los sistemas se vuelve cada vez más complejo con el tiempo.
Sin un control de versiones o una gobernanza de políticas adecuados, las organizaciones corren el riesgo de dejar sin enmascarar los datos confidenciales recién introducidos o de aplicar reglas obsoletas que ya no cumplen con las necesidades de cumplimiento.
Para gestionar esto, es esencial implementar un marco de gobernanza para el enmascaramiento de datos que incluya revisiones periódicas de políticas, el control de versiones de las reglas de enmascaramiento y la documentación de los cambios. Las herramientas de descubrimiento automatizadas pueden ayudar a detectar los cambios de esquema y alertar a los equipos de datos sobre posibles lagunas.
9. Requisitos de cumplimiento y auditoría
El enmascaramiento de datos a menudo se implementa para cumplir con las regulaciones de protección de datos como GDPR, HIPAA, CCPA y PCI DSS. Estas regulaciones exigen que las organizaciones no solo protejan los datos confidenciales, sino también que demuestren que se han tomado las medidas apropiadas. El no producir pistas de auditoría, registros o evidencia de un enmascaramiento coherente puede resultar en sanciones, incluso si los datos estaban técnicamente protegidos.
Muchas implementaciones de enmascaramiento se centran en la capa técnica, pero pasan por alto la documentación y la trazabilidad necesarias para las auditorías. Sin registros claros de qué datos se enmascararon, cómo se enmascararon y quién tuvo acceso, pueden surgir lagunas de cumplimiento.

10. Identidad del usuario y enmascaramiento basado en roles
No todos los usuarios requieren el mismo nivel de acceso a los datos. Por ejemplo, un desarrollador solo puede necesitar valores enmascarados, mientras que un responsable de cumplimiento puede necesitar ver información más detallada. La implementación del enmascaramiento de datos basado en roles garantiza que los datos confidenciales se enmascaren selectivamente en función de la identidad, el rol o los privilegios de acceso del usuario. Sin embargo, la configuración y el mantenimiento de estas reglas dinámicas en todos los sistemas y grupos de usuarios pueden ser complejos y propensos a errores.
Sin un control de acceso preciso, los datos confidenciales pueden exponerse a usuarios que no deberían tener acceso, o un enmascaramiento demasiado restrictivo puede obstaculizar a los usuarios que necesitan un contexto de datos real.
Para gestionar este desafío, las organizaciones deben integrar el enmascaramiento de datos con los sistemas de gestión de identidades y accesos (IAM). Esto permite que las políticas de enmascaramiento se ajusten dinámicamente en función de los roles y permisos del usuario. Se deben definir políticas centralizadas basadas en roles y revisarlas periódicamente para garantizar la alineación con las necesidades empresariales. La supervisión de los registros de acceso y la implementación de principios de acceso con privilegios mínimos ayudan aún más a reducir la exposición innecesaria al tiempo que se mantiene la usabilidad.
11. Calidad del enmascaramiento en los modelos de detección de PII / NLP
En muchas organizaciones, los datos confidenciales no se limitan a los campos estructurados, sino que también existen en formatos no estructurados como correos electrónicos, comentarios de clientes, registros de chat o documentos. La detección y el enmascaramiento de información de identificación personal (PII) en estas fuentes a menudo se basa en el procesamiento del lenguaje natural (NLP) o en modelos de reconocimiento de entidades con nombre (NER). Sin embargo, estos modelos no siempre son precisos. Pueden clasificar erróneamente o pasar por alto ciertas entidades, especialmente cuando se trata de jerga, abreviaturas, contenido multilingüe o formato irregular.
Como resultado, la PII crítica puede pasar desapercibida y permanecer sin enmascarar, lo que aumenta el riesgo de fuga de datos o incumplimiento. Alternativamente, los falsos positivos pueden hacer que los datos no confidenciales se enmascaren innecesariamente, lo que reduce la calidad de los datos.
Para mejorar la precisión, las organizaciones deben utilizar modelos NLP sensibles al contexto y específicos del dominio entrenados en conjuntos de datos relevantes. La combinación de enfoques basados en reglas (por ejemplo, regex para números de teléfono, patrones de correo electrónico) con modelos de aprendizaje automático aumenta la fiabilidad de la detección. También es esencial validar el rendimiento del modelo con regularidad y ajustarlo en función de los comentarios. Un enfoque en capas que aplica múltiples métodos de detección puede ayudar a reducir tanto los falsos positivos como los falsos negativos en la identificación de datos confidenciales.
12. Sesgo y equidad en los modelos de enmascaramiento
Se utilizan modelos de IA y aprendizaje automático para el enmascaramiento de datos. Particularmente para el reconocimiento o la clasificación de entidades, puede exhibir sesgos.
Por ejemplo, los nombres, las etnias o los patrones demográficos específicos pueden estar subrepresentados en los datos de entrenamiento, lo que lleva a un enmascaramiento incoherente en diferentes grupos de población. Esto crea una capa de protección desigual, donde los datos de algunos usuarios pueden enmascararse correctamente, mientras que los de otros se pasan por alto. Tales disparidades se reflejan mal en la ética de manejo de datos y los estándares de equidad de la organización.
Para abordar esto, las organizaciones deben evaluar la equidad y representatividad de sus modelos de enmascaramiento. Esto incluye revisar los datos de entrenamiento en busca de diversidad, medir el rendimiento en diferentes segmentos demográficos y reentrenar los modelos según sea necesario. La transparencia en el diseño del modelo y la incorporación de procesos de validación con intervención humana también pueden mejorar la equidad en la protección de datos.
13. Asegurando la tokenización, el cifrado y el enmascaramiento determinista
Muchas organizaciones utilizan técnicas avanzadas de enmascaramiento como la tokenización, el cifrado o el enmascaramiento determinista para proteger datos sensibles. Si bien estos métodos ofrecen una seguridad sólida, también introducen desafíos operativos. La tokenización y el cifrado requieren una gestión cuidadosa de las claves; si se pierden las claves, se bloquea permanentemente el acceso a datos críticos; si se manejan mal las claves, los datos podrían quedar expuestos.
Con el enmascaramiento determinista, la misma entrada siempre debe producir la misma salida enmascarada para preservar la consistencia entre sistemas. Sin embargo, garantizar esto sin hacer que los datos sean reversibles puede ser difícil. Si se implementa incorrectamente, el enmascaramiento determinista puede revelar patrones involuntariamente o permitir la reidentificación.
14. Garantizar el realismo y la validez de los datos
Uno de los objetivos del enmascaramiento de datos es preservar la usabilidad de los datos, particularmente para desarrollo, pruebas o análisis. Si los datos enmascarados carecen de realismo (por ejemplo, fechas de nacimiento poco realistas, números de teléfono inválidos o categorías incompatibles), las aplicaciones pueden fallar en su funcionamiento correcto. Además, algunos sistemas tienen validaciones incorporadas (como requisitos de suma de comprobación para IDs) que los datos enmascarados aún deben cumplir.
Para garantizar el realismo, el enmascaramiento debe incluir transformaciones que preserven el formato y mantengan los tipos de datos, rangos de valores y patrones referenciales. Por ejemplo, las fechas enmascaradas deben caer dentro de marcos temporales realistas, y los nombres enmascarados deben parecerse a entradas válidas. En sistemas que requieren validación (como números de tarjetas de crédito), las herramientas de enmascaramiento deben generar sustitutos sintácticamente correctos.
Ejecutar pruebas de validación automatizadas después del enmascaramiento ayuda a confirmar que los datos enmascarados siguen siendo funcionalmente válidos y alineados con las reglas de negocio esperadas.
15. Registro, monitoreo y seguimiento de cambios
Un desafío frecuentemente pasado por alto en el enmascaramiento de datos es la falta de mecanismos robustos de registro y monitoreo. Sin registros detallados, se vuelve difícil rastrear quién aplicó el enmascaramiento, cuándo se aplicó, qué datos se vieron afectados y si el proceso de enmascaramiento se completó con éxito. Esto puede llevar a problemas durante auditorías, resolución de problemas o gestión de cambios.
Además, a medida que los entornos de datos evolucionan, las políticas y configuraciones de enmascaramiento también necesitan actualizarse. Sin seguimiento de cambios, las organizaciones corren el riesgo de aplicar reglas de enmascaramiento obsoletas o introducir inconsistencias entre entornos.
Estrategias efectivas para superar los desafíos del enmascaramiento de datos
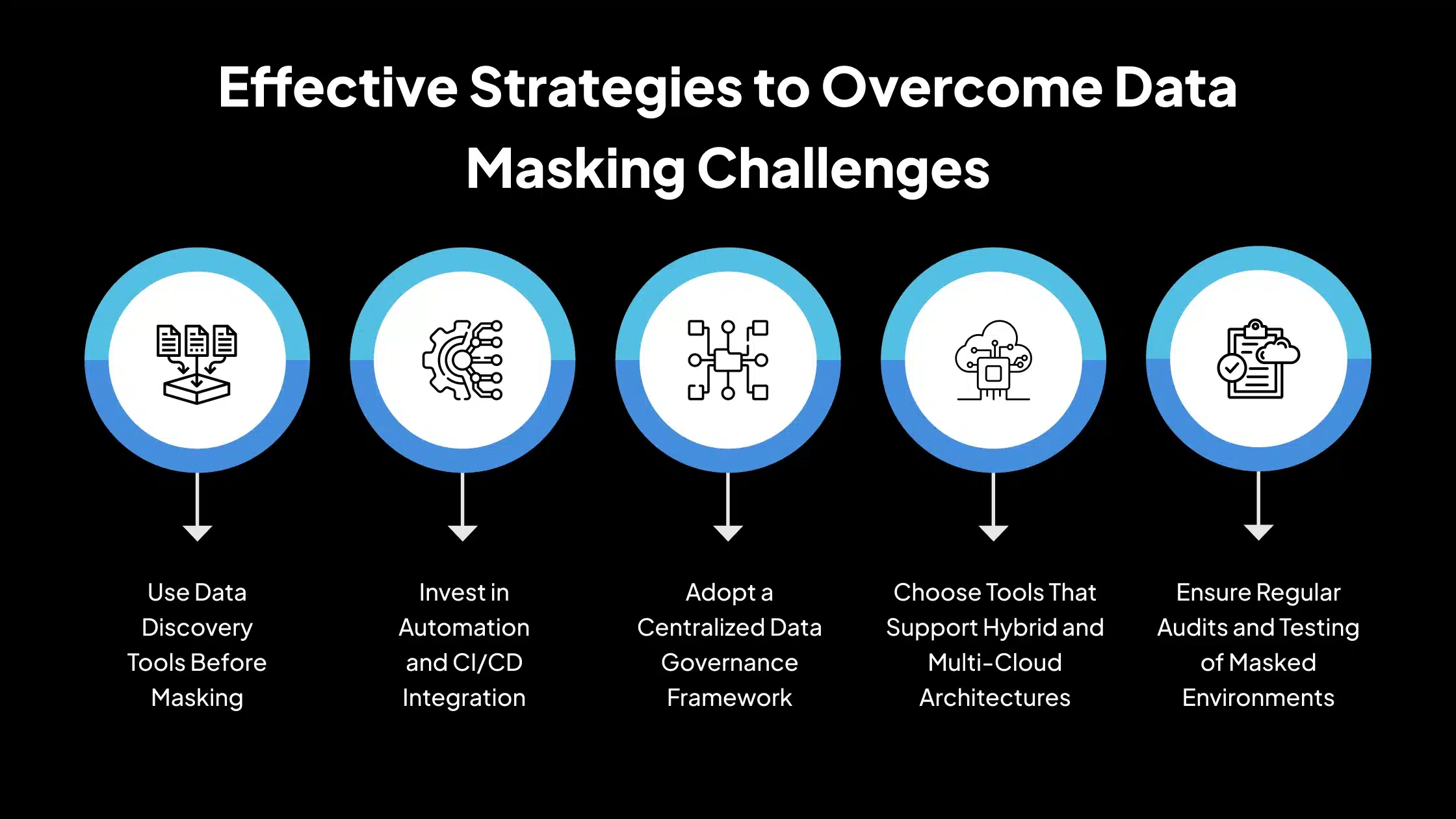
Para implementar efectivamente el enmascaramiento de datos y abordar los desafíos discutidos anteriormente, las organizaciones deben seguir un enfoque estructurado y proactivo. Las siguientes estrategias pueden mejorar la precisión, escalabilidad y cumplimiento en los esfuerzos de enmascaramiento:
1. Utilizar herramientas de descubrimiento de datos antes del enmascaramiento
Antes de aplicar técnicas de enmascaramiento, es esencial identificar con precisión dónde residen los datos sensibles. Las herramientas de descubrimiento de datos pueden escanear fuentes estructuradas, semiestructuradas y no estructuradas para localizar PII, PHI y otros elementos sensibles. Estas herramientas reducen el riesgo de pasar por alto datos críticos y ayudan a las organizaciones a construir un inventario confiable de lo que necesita ser protegido.
2. Invertir en automatización e integración de CI/CD
El enmascaramiento manual es propenso a errores y difícil de escalar. Integrar el enmascaramiento de datos en los pipelines de CI/CD asegura que los datos se saneen automáticamente durante el desarrollo, las pruebas o el despliegue. La automatización mejora la consistencia, reduce el error humano y acelera los flujos de trabajo, particularmente en entornos que manejan actualizaciones frecuentes de datos.
3. Adoptar un marco de gobernanza de datos centralizado
Un marco de gobernanza define cómo se crean, aplican, revisan y actualizan las políticas de enmascaramiento de datos. Centralizar este proceso permite una aplicación uniforme en todos los departamentos y sistemas. También apoya una mejor preparación para auditorías y seguimiento de políticas al consolidar responsabilidades y documentación en un solo lugar.
4. Elegir herramientas que soporten arquitecturas híbridas y multi-nube
Las organizaciones modernas a menudo utilizan una combinación de sistemas locales, servicios en la nube y múltiples bases de datos. Elegir herramientas de enmascaramiento de datos que soporten entornos híbridos y multi-nube asegura una aplicación consistente de las reglas de enmascaramiento en todas las plataformas. También simplifica la administración y reduce la necesidad de herramientas separadas para cada sistema.
5. Asegurar auditorías regulares y pruebas de entornos enmascarados
Después de aplicar el enmascaramiento, es importante verificar que los datos sigan siendo funcionales, realistas y conformes. Las auditorías regulares ayudan a detectar brechas en la cobertura del enmascaramiento, mientras que las pruebas confirman que las aplicaciones continúan funcionando correctamente. Estas verificaciones deben ser parte de la gestión rutinaria del ciclo de vida de los datos para garantizar la eficacia continua.
Proteja la información confidencial con la herramienta inteligente de enmascaramiento de datos de Avahi
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi proporciona herramientas que permiten a las organizaciones gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es Data Masker, diseñado para proteger los datos financieros y de identificación personal, a la vez que respalda la eficiencia operativa.
Descripción general del Data Masker de Avahi
El Data Masker de Avahi es una herramienta versátil de protección de datos diseñada para ayudar a las organizaciones a gestionar de forma segura la información confidencial en diversas industrias, incluyendo la atención sanitaria, las finanzas, el comercio minorista y los seguros.
La herramienta permite a los equipos enmascarar datos confidenciales como números de cuenta, registros de pacientes, identificadores personales y detalles de transacciones sin interrumpir los flujos de trabajo operativos.
El Data Masker de Avahi garantiza que solo los usuarios autorizados puedan ver o interactuar con datos confidenciales aplicando técnicas avanzadas de enmascaramiento y aplicando el control de acceso basado en roles. Esto es especialmente importante cuando varios departamentos o proveedores externos acceden a los datos.
Ya sea protegiendo la información de salud del paciente en cumplimiento con HIPAA, anonimizando los registros financieros para PCI DSS o asegurando los datos del cliente para GDPR, la herramienta ayuda a las organizaciones a minimizar el riesgo de acceso no autorizado al tiempo que preserva la usabilidad de los datos para fines de desarrollo, análisis y supervisión del fraude.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, reconocemos la importancia crucial de proteger la información confidencial, a la vez que mantenemos flujos de trabajo operativos perfectos.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programar una llamada de demostración
Preguntas frecuentes
1. ¿Cuál es la principal diferencia entre el enmascaramiento de datos y el cifrado de datos?
El enmascaramiento de datos reemplaza valores sensibles con datos ficticios pero de apariencia realista para protegerlos en entornos no productivos. A diferencia del cifrado, los datos enmascarados no están destinados a ser revertidos. El cifrado protege los datos en producción o tránsito y puede descifrarse con una clave, mientras que el enmascaramiento es típicamente irreversible y se usa para pruebas, análisis o entrenamiento. .
2. ¿Por qué las organizaciones luchan para implementar el enmascaramiento de datos de manera efectiva?
Los problemas comunes incluyen un descubrimiento de datos deficiente, falta de políticas de enmascaramiento centralizadas, dificultad para mantener la integridad referencial e impactos en el rendimiento en grandes conjuntos de datos. Muchos también fallan en integrar el enmascaramiento en los pipelines de CI/CD o pasan por alto el enmascaramiento de fuentes de datos no estructurados como registros y documentos.
3. ¿Cómo podemos asegurar que los datos enmascarados sigan siendo útiles para el desarrollo y las pruebas?
Usar enmascaramiento determinista o que preserve el formato ayuda a mantener la consistencia y el realismo de los datos. Esto permite que las aplicaciones funcionen adecuadamente mientras se garantiza la privacidad. Las rutinas de validación y las pruebas automatizadas también pueden confirmar que los datos enmascarados mantienen la integridad funcional y lógica.
4. ¿Es el enmascaramiento dinámico de datos adecuado para todos los entornos?
No siempre. El enmascaramiento dinámico de datos es ideal para el control de acceso de usuarios en tiempo real en producción, pero puede no ser suficiente para una desidentificación completa. Se utiliza mejor cuando se necesita acceso basado en roles, mientras que el enmascaramiento estático o en tiempo real es más apropiado para desarrollo, pruebas o compartir datos.
5. ¿Qué herramientas o prácticas ayudan a mitigar los desafíos del enmascaramiento de datos?
Las estrategias efectivas incluyen el uso de herramientas automatizadas de descubrimiento de datos, la integración del enmascaramiento en los pipelines de DevOps, la adopción de una gobernanza centralizada y la elección de herramientas que soporten entornos híbridos/multi-nube. Las auditorías y pruebas regulares también son clave para garantizar el cumplimiento y la eficacia.



