

TL;DR
|
Un estudio reciente de Gartner predice que para 2026, el 75% de la población mundial tendrá sus datos protegidos por las regulaciones de privacidad. Al mismo tiempo, un informe reciente de Delphix revela que el 54% de las organizaciones han sufrido violaciones de datos en entornos que no son de producción, y el 86% permite excepciones de cumplimiento de datos en contextos de prueba y control de calidad.
Esta combinación crea un escenario de alto riesgo: los datos de producción confidenciales se están copiando, compartiendo y utilizando en lugares donde nunca se pretendió que estuvieran.
El enmascaramiento de datos aborda este riesgo directamente reemplazando los valores confidenciales, como nombres, correos electrónicos o detalles financieros, con datos realistas pero no identificables. Permite a los desarrolladores, analistas y científicos de datos trabajar de manera productiva, sin tener que manejar datos reales que puedan desencadenar violaciones de cumplimiento o incidentes de seguridad.
Aquí es donde DataMasque entra en juego. Creado para entornos de nube como AWS, DataMasque automatiza el descubrimiento y el enmascaramiento de datos confidenciales en fuentes estructuradas y semiestructuradas, lo que garantiza el cumplimiento sin interrumpir los flujos de trabajo operativos.
En este blog, exploraremos por qué el enmascaramiento de datos de AWS es esencial para las operaciones seguras y conformes de AWS y cómo DataMasque encaja en las canalizaciones de datos modernas y los entornos de desarrollo/prueba.
Tanto si está preparando datos para los equipos de control de calidad, los modelos de aprendizaje automático o la migración de cargas de trabajo a la nube, esta guía le mostrará cómo proteger sus datos sin ralentizar la innovación.
Comprensión de DataMasque: una solución creada específicamente para el enmascaramiento de datos de AWS
DataMasque es una solución especializada de enmascaramiento de datos diseñada para proteger la información confidencial, incluida la información de identificación personal (PII), la información protegida de la salud (PHI) y los datos de pago. Se utiliza principalmente para generar conjuntos de datos realistas y desidentificados para el desarrollo, las pruebas, el análisis y el entrenamiento de la IA, sin exponer los datos de producción en vivo.
El objetivo principal de DataMasque es asegurar los datos confidenciales transformándolos en datos sintéticos enmascarados que no pueden ser objeto de ingeniería inversa. Esto garantiza que las empresas puedan utilizar de forma segura las réplicas de datos en entornos que no son de producción, manteniendo al mismo tiempo la utilidad de los datos para las tareas funcionales. Aquí está la lista de algunas de las capacidades clave de DataMasque:
1. Descubrimiento de datos confidenciales
DataMasque incluye reglas de detección integradas para identificar datos confidenciales en una amplia gama de sistemas de origen. También se puede configurar con reglas de descubrimiento personalizadas para que se ajusten a las necesidades de la organización o a los requisitos de cumplimiento.
Incluye patrones predefinidos para nombres, correos electrónicos, números de tarjetas de crédito, fechas y otros identificadores estándar, y el descubrimiento funciona en varias bases de datos y tipos de archivos, lo que reduce el esfuerzo manual.
2. Enmascaramiento de datos flexible
Una vez que se identifican los datos confidenciales, DataMasque aplica técnicas de enmascaramiento irreversibles para garantizar la privacidad. Los métodos incluyen el hash, la aleatorización, el enmascaramiento que preserva el formato y las reglas de sustitución personalizadas. Los datos enmascarados conservan una estructura realista y la integridad referencial, lo que significa que las relaciones entre las columnas de datos (por ejemplo, el ID de usuario y el correo electrónico) siguen siendo lógicamente coherentes.
3. Soporte para datos estructurados y semiestructurados
DataMasque soporta formatos tanto estructurados (por ejemplo, bases de datos relacionales) como semiestructurados (por ejemplo, JSON, XML, CSV). Compatible con plataformas como PostgreSQL, MySQL, Oracle, SQL Server, y Amazon RDS. El enmascaramiento basado en archivos permite el procesamiento de archivos planos, registros o conjuntos de datos exportados de aplicaciones empresariales.
4. Despliegue en AWS
DataMasque está disponible en AWS Marketplace como una Amazon Machine Image (AMI) preconfigurada que se ejecuta en Amazon EC2. Esto facilita su despliegue dentro de los entornos de AWS con una configuración mínima.
Se integra con los servicios de AWS como Secrets Manager, Step Functions, y CloudFormation para la automatización. Adecuado para tareas de enmascaramiento bajo demanda o programadas en entornos nativos de la nube e híbridos.
Por qué el enmascaramiento de datos de AWS es esencial para la seguridad y el cumplimiento
El enmascaramiento de datos es un componente crucial de las estrategias modernas de seguridad y cumplimiento de datos, particularmente en entornos de nube como Amazon Web Services (AWS). A medida que las empresas migran su infraestructura y cargas de trabajo a AWS, deben asegurarse de que los datos confidenciales estén protegidos en cada etapa de almacenamiento, procesamiento y pruebas. Aquí está el por qué el enmascaramiento de datos es esencial en AWS:
1. Cumplimiento normativo
Las organizaciones que manejan datos confidenciales deben cumplir con las regulaciones regionales y específicas de la industria. Estas regulaciones requieren que los datos personales y confidenciales no se expongan de manera que puedan conducir a un acceso o uso indebido no autorizado.
El RGPD (Reglamento General de Protección de Datos) exige la protección de los datos personales de los ciudadanos de la UE. La HIPAA (Ley de Portabilidad y Responsabilidad del Seguro Médico) establece directrices estrictas sobre la protección de la información protegida de la salud (PHI) en el sector sanitario.
La CCPA (Ley de Privacidad del Consumidor de California) proporciona derechos de privacidad y protecciones para los residentes de California. PCI-DSS (Estándar de Seguridad de Datos de la Industria de Tarjetas de Pago) garantiza el manejo seguro de los datos de tarjetas de crédito y de pago.
El uso de soluciones de enmascaramiento de datos como DataMasque ayuda a las organizaciones en AWS a cumplir con estos requisitos normativos al convertir los datos confidenciales en formatos desidentificados que conservan la utilidad pero eliminan los riesgos de exposición.
2. Riesgos de no producción
Muchos equipos de desarrollo, pruebas y análisis requieren acceso a datos que reflejen las condiciones de producción. Sin embargo, el uso de datos de producción reales en entornos que no son de producción introduce serios riesgos, como la exposición de datos personales o financieros a usuarios internos, proveedores o contratistas externos.
Mayor superficie de ataque, ya que los entornos de desarrollo y prueba son a menudo menos seguros que los sistemas de producción, y fugas de datos accidentales a través de copias de seguridad, registros o controles de acceso mal configurados.
El enmascaramiento de los datos de producción antes de utilizarlos en entornos de prueba, desarrollo o formación reduce significativamente el riesgo de violaciones de datos y divulgaciones accidentales, al tiempo que proporciona datos utilizables y representativos.
3. Datos sintéticos realistas
Una de las ventajas clave del enmascaramiento de datos con herramientas como DataMasque es la generación de datos sintéticamente precisos. Estos datos enmascarados reflejan la estructura y la lógica del original, sin contener valores confidenciales reales.
Los desarrolladores e ingenieros de control de calidad pueden trabajar con conjuntos de datos que se asemejan a los datos de producción, lo que les permite validar el rendimiento, la usabilidad y el manejo de errores con precisión. Los modelos de aprendizaje automático entrenados con datos realistas pero anonimizados conservan la calidad del rendimiento al tiempo que reducen los problemas de cumplimiento.
Las herramientas de inteligencia empresarial pueden procesar conjuntos de datos enmascarados para obtener información, tendencias y previsiones, sin violar las normas de privacidad de los datos. Esto permite a los equipos mantener la productividad y la precisión en los flujos de trabajo nativos de la nube en AWS sin comprometer la privacidad o la seguridad de los datos.
Cómo opera DataMasque dentro del ecosistema de AWS
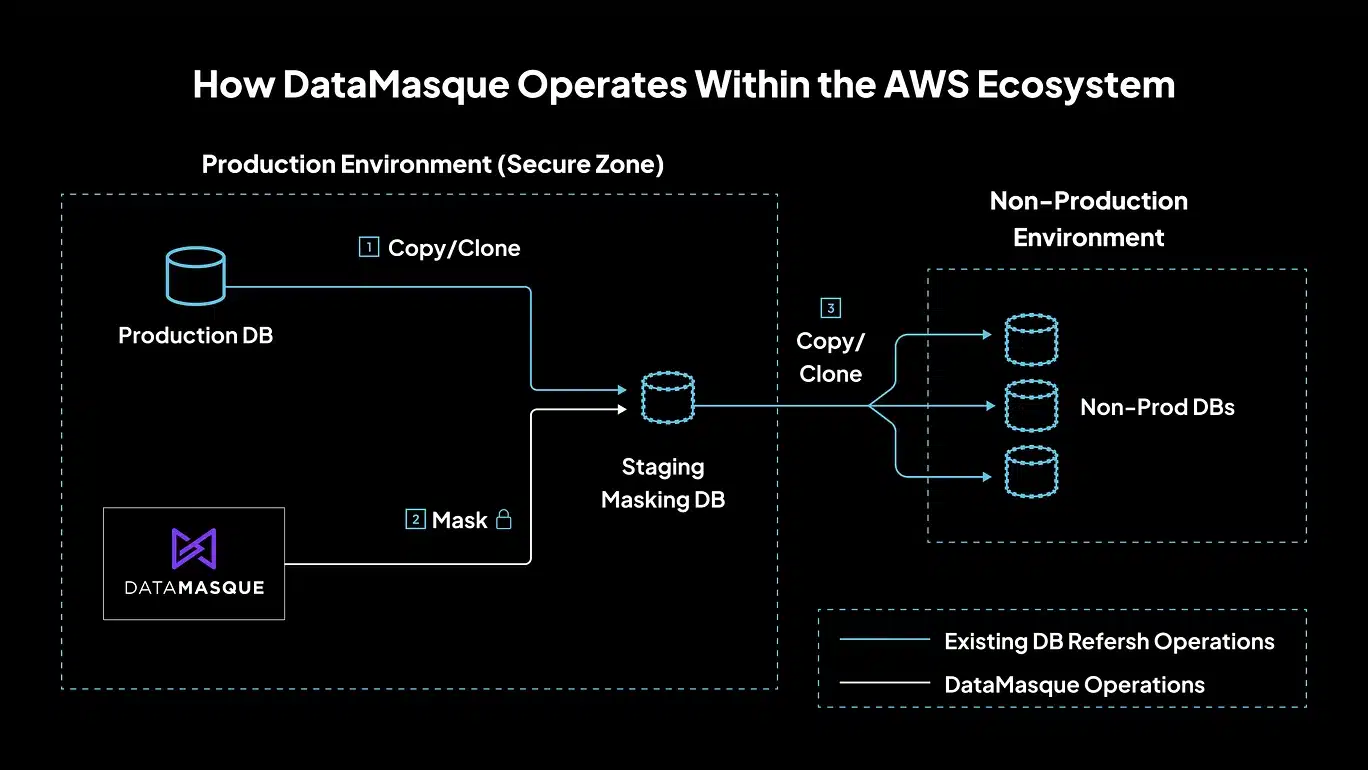
DataMasque se integra perfectamente con la infraestructura de AWS para proporcionar un enmascaramiento de datos automatizado y seguro. Está diseñado para ser fácil de implementar, escalable en todos los entornos y adaptable a diferentes requisitos de cumplimiento. A continuación, se presenta un desglose de cómo funciona en varias áreas:
1. Opciones de implementación
AMI de AWS Marketplace (imagen de máquina de Amazon)
DataMasque está disponible como una AMI preconstruida en AWS Marketplace. Los usuarios pueden lanzar rápidamente la solución en una instancia de EC2 utilizando una prueba gratuita, opciones de Bring-Your-Own-License (BYOL) u opciones de precios flexibles por hora/mes. Esto lo hace accesible tanto para la evaluación a corto plazo como para la implementación a largo plazo dentro de los flujos de trabajo en la nube.
Integración con el constructor de imágenes de EC2
Para las organizaciones que crean y actualizan regularmente instancias de EC2, DataMasque puede integrarse en la canalización del constructor de imágenes de EC2. Esto permite el enmascaramiento automatizado de datos como parte de la creación de imágenes, lo que ayuda a estandarizar los entornos seguros en las implementaciones de desarrollo o prueba.
2. Descubrimiento de datos y conjuntos de reglas
Descubrimiento de datos confidenciales
DataMasque escanea automáticamente las bases de datos y los archivos conectados para identificar los datos confidenciales. Viene con reglas de detección integradas para los tipos de datos comunes, incluyendo nombres, correos electrónicos, identificaciones gubernamentales, números de teléfono, números de tarjetas de crédito e información de salud. Además, los usuarios pueden definir patrones personalizados para cumplir con los requisitos regulatorios o empresariales específicos.
Creación y uso de conjuntos de reglas
Una vez que se identifican los campos confidenciales, las reglas de enmascaramiento se configuran utilizando conjuntos de reglas basados en YAML. Estos conjuntos de reglas especifican qué columnas o campos deben enmascararse y qué métodos de enmascaramiento deben aplicarse. Los conjuntos de reglas son reutilizables, tienen control de versiones y pueden utilizarse en múltiples entornos para una protección coherente en todos los entornos.
Motor de enmascaramiento y tipos de enmascaramiento
DataMasque soporta una variedad de técnicas de enmascaramiento irreversibles para asegurar la privacidad de los datos manteniendo la usabilidad. SHA‑512 Salted Hash convierte los valores originales en hashes fijos y no reversibles. La aleatorización y el enmascaramiento basado en la frecuencia generan nuevos valores que imitan la distribución estadística de los datos originales.
Las reglas de retención de fechas compensan o aleatorizan las fechas preservando los intervalos o las secuencias.
Las máscaras basadas en la elección reemplazan los valores con entradas de una lista o patrón predefinido, útil para campos como nombres de departamento o regiones.
Cada técnica se selecciona en función del tipo de datos y el caso de uso, lo que garantiza el cumplimiento sin interrumpir los flujos de trabajo empresariales.
3. Mantenimiento de la integridad
Para asegurar que los datos enmascarados sigan siendo funcionalmente válidos, DataMasque preserva la integridad referencial y las relaciones de datos. DataMasque puede enmascarar identificadores como los ID de los clientes manteniendo la singularidad.
Asegura que las relaciones de clave externa (por ejemplo, los ID de usuario vinculados a través de múltiples tablas) permanezcan intactas, permitiendo que las aplicaciones y las consultas continúen funcionando correctamente con los datos enmascarados. Esta característica es crítica para los equipos de desarrollo, pruebas y análisis que dependen de conjuntos de datos consistentes e interconectados.
Casos de uso prácticos y valor empresarial de DataMasque en AWS
DataMasque ofrece una solución práctica para gestionar de forma segura los datos confidenciales en varios entornos de nube. A continuación, se presentan los casos de uso esenciales que demuestran cómo las organizaciones se benefician de sus capacidades de enmascaramiento, especialmente dentro del ecosistema de AWS.
1. Entornos seguros de desarrollo/prueba
Una de las aplicaciones más comunes de DataMasque es permitir a los equipos de desarrollo y pruebas trabajar con datos que reflejen las condiciones reales de producción, sin exponer la información confidencial real.
Los desarrolladores y los equipos de control de calidad a menudo requieren acceso completo a las estructuras de la base de datos y a las relaciones de los datos para depurar o validar las características. El uso de datos de producción sin enmascarar en estos entornos crea un riesgo de seguridad y viola las normas de cumplimiento.
Con DataMasque, las organizaciones pueden generar conjuntos de datos enmascarados y funcionalmente precisos que preservan el formato y la estructura, lo que permite a los equipos realizar pruebas realistas sin comprometer la privacidad de los datos. Esto mejora la eficiencia del desarrollo al tiempo que reduce los riesgos legales y de seguridad.
2. Flujos de trabajo de análisis e IA/ML
Las organizaciones utilizan cada vez más datos confidenciales para impulsar los paneles de control, las canalizaciones de análisis y los modelos de aprendizaje automático. DataMasque les permite hacerlo sin exponer los datos personales en bruto.
Los científicos de datos y los analistas pueden trabajar con datos enmascarados sintéticamente idénticos que reflejan patrones y distribuciones reales. Esto asegura que los modelos predictivos y los análisis estadísticos sigan siendo válidos mientras cumplen con las leyes de protección de datos, como el RGPD o la HIPAA.
Los equipos de inteligencia empresarial pueden generar informes y paneles de control precisos basados en conjuntos de datos enmascarados, incluso sin acceso a la PII en bruto. Esto permite la extracción segura de información y la formación de modelos de forma consciente con la privacidad.
3. Migración acelerada a la nube
Durante la migración a la nube, la transferencia de datos de producción en bruto a servicios en la nube como Amazon RDS o Amazon S3 introduce desafíos de cumplimiento y seguridad.
DataMasque puede ser desplegado para enmascarar los datos confidenciales antes o durante el proceso de migración.
Esto asegura que los conjuntos de datos enmascarados sean migrados, reduciendo el riesgo de exposición accidental o violaciones durante la transición.
Las organizaciones pueden moverse más rápido mientras cumplen simultáneamente con los estándares internos de gobierno de datos. Esto es beneficioso para las organizaciones sujetas a auditorías o leyes internacionales de residencia de datos.
Hoteles y resorts Best Western® implementó DataMasque para mejorar la seguridad de los datos y la agilidad en todas sus operaciones de TI. Antes de DataMasque, sus entornos de desarrollo y prueba a menudo se enfrentaban a retrasos debido a los largos procesos manuales de saneamiento de datos.
Después de adoptar DataMasque en AWS, fueron capaces de reducir significativamente el tiempo de enmascaramiento.
Los conjuntos de datos enmascarados conservaron la lógica de negocio y la integridad referencial, lo que permitió a sus desarrolladores probar nuevas características con mayor confianza. Esto condujo a ciclos de innovación más rápidos al tiempo que se aseguraba el cumplimiento de las regulaciones de privacidad.
Mejores prácticas para el despliegue y la operación de DataMasque en AWS
Antes de desplegar DataMasque en AWS, los siguientes componentes deben estar en su lugar:
|
Para asegurar el uso seguro y eficiente de DataMasque en AWS, es esencial seguir los requisitos previos específicos y las directrices operativas. Estas prácticas ayudan a mantener la privacidad de los datos, la estabilidad del sistema y el rendimiento a largo plazo en los flujos de trabajo de enmascaramiento.
1. Utilice subredes privadas
Despliegue las instancias de EC2 que alojan DataMasque dentro de subredes privadas en su nube privada virtual (VPC). Esto limita la exposición de la instancia a la Internet pública y reduce la superficie de ataque, asegurando que sólo los servicios internos o los puntos finales de confianza puedan acceder al entorno.
2. Restrinja el acceso SSH y HTTPS
Restrinja el acceso a SSH (puerto 22) y HTTPS (puerto 443) configurando las reglas del grupo de seguridad de AWS. Limite el acceso a direcciones IP o rangos específicos, como sólo su red interna o un host bastión designado. Esto minimiza el potencial de acceso externo no autorizado.
3. Habilite el cifrado del sistema de archivos
Habilite el cifrado del volumen de Amazon EBS en la instancia de EC2 utilizada por DataMasque. Esto protege todos los datos almacenados en el disco, incluyendo los datos temporales y enmascarados en reposo, utilizando claves gestionadas por AWS o claves gestionadas por el cliente a través de AWS Key Management Service (KMS).
4. Aplique parches del sistema operativo y actualizaciones de seguridad
Actualice regularmente el sistema operativo de la instancia de EC2 para aplicar los últimos parches y correcciones de seguridad. Esto asegura la protección contra las vulnerabilidades conocidas y mantiene el cumplimiento de las políticas de seguridad de TI. Utilice herramientas de automatización como AWS Systems Manager Patch Manager para la eficiencia.
5. Supervise el estado del contenedor
Supervise continuamente el contenedor Docker que ejecuta DataMasque para asegurar que funciona correctamente. Herramientas como Amazon CloudWatch pueden ayudar a detectar problemas de rendimiento, fallos de servicio o agotamiento de recursos, lo que permite la resolución de problemas y la resolución proactiva.
6. Haga copias de seguridad de los conjuntos de reglas y los registros
Mantenga copias de seguridad regulares de los conjuntos de reglas YAML y los registros de enmascaramiento en una ubicación segura y centralizada, como un bucket de Amazon S3 cifrado o un repositorio con control de versiones. Esta práctica apoya los rastros de auditoría, la recuperación de desastres y la reutilización de las configuraciones en todos los entornos.
7. Gestione las actualizaciones de software
Mantenga actualizado el software DataMasque comprobando si hay nuevas versiones y aplicando las actualizaciones según sea necesario. Las actualizaciones periódicas garantizan el acceso a las últimas funciones, correcciones de errores y mejoras de seguridad, lo que reduce el riesgo de vulnerabilidades relacionadas con el software.
Enmascaramiento de datos estructurados frente a enmascaramiento de datos a nivel de documento en AWS: ¿cuál es la opción adecuada para usted?
A medida que más organizaciones migran cargas de trabajo a AWS, la gestión de datos confidenciales en los servicios en la nube se ha convertido en una prioridad máxima. Sin embargo, no todos los datos son iguales; las bases de datos estructuradas, los documentos no estructurados y las salidas generadas por IA requieren diferentes enfoques para la protección de datos.
Si bien las herramientas de enmascaramiento de datos estructurados como DataMasque están diseñadas para proteger las bases de datos relacionales y preservar la integridad de los datos para las pruebas y el análisis, no están diseñadas para manejar el creciente volumen de contenido no estructurado, incluidos archivos, correos electrónicos, archivos PDF o salidas de modelos de IA en tiempo real. Ahí es donde soluciones como Data Masker de Avahi proporcionan una alternativa más inteligente y adaptable.
1. Enmascaramiento de datos estructurados con DataMasque
DataMasque está diseñado específicamente para datos estructurados y semiestructurados, como bases de datos relacionales, archivos JSON y exportaciones CSV. Destaca en:
- Descubrir datos confidenciales utilizando reglas de detección integradas y personalizadas
- Aplicar técnicas de enmascaramiento irreversibles preservando las relaciones de los datos
- Mantener la integridad referencial en tablas y entornos interconectados
- Apoyar los flujos de trabajo de desarrollo y pruebas con datos enmascarados sintéticamente precisos
Esto convierte a DataMasque en una opción sólida para las organizaciones que buscan proteger los registros de la base de datos durante el desarrollo/prueba, el control de calidad o la migración de datos.
Sin embargo, sus capacidades se centran principalmente en entornos de datos estructurados. No admite de forma nativa el enmascaramiento de documentos, archivos de imagen, correos electrónicos o lagunas de contenido generadas por IA que son cada vez más relevantes en los ecosistemas de datos actuales.
2. Enmascaramiento no estructurado y a nivel de documento con Avahi
Data Masker de Avahi aborda de frente el desafío de los datos no estructurados. Integrado en la plataforma de IA de Avahi, está diseñado para proteger la información confidencial que no reside en bases de datos, sino que fluye a través de documentos, canales de comunicación y salidas de GenAI.
Las capacidades esenciales incluyen:
- Enmascaramiento y redacción en tiempo real de PII, PHI y datos financieros en archivos de Word, PDF e imagen
- Integración perfecta con herramientas de Microsoft Office, CRM y repositorios de datos compartidos
- Detección impulsada por GenAI para depurar contenido confidencial en documentos generados por IA, registros de chat y resúmenes
- Controles de acceso basados en roles, que garantizan que solo los usuarios autorizados accedan a datos reales o enmascarados
- Soporte de cumplimiento para GDPR, HIPAA y PCI DSS sin interrumpir los flujos de trabajo internos
Donde otras herramientas de enmascaramiento se detienen en conjuntos de datos estructurados, Avahi continúa el recorrido de protección a través de documentos, correos electrónicos y contenido dinámico, lo que la convierte en la solución ideal para la privacidad en la era de la IA y la colaboración en la nube.
Al seleccionar una solución de enmascaramiento de datos, es importante tener en cuenta dónde residen sus datos confidenciales y cómo interactúan sus equipos con ellos. Si está trabajando con grandes volúmenes de registros estructurados, como ID de clientes, transacciones o conjuntos de datos de prueba, DataMasque puede ser una buena opción.
Pero suponga que sus datos residen en documentos, formularios, archivos o salidas de GenAI, o fluyen a través de plataformas de comunicación y colaboración. En ese caso, Data Masker de Avahi ofrece la precisión, la flexibilidad y la protección en tiempo real que necesitan las organizaciones modernas.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, reconocemos la importancia crucial de proteger la información confidencial, a la vez que mantenemos flujos de trabajo operativos perfectos.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programar una llamada de demostración
Preguntas frecuentes
1. ¿Qué es el enmascaramiento de datos de AWS y por qué es importante?
El enmascaramiento de datos de AWS es el proceso de ofuscar datos confidenciales (como PII o PHI) almacenados en entornos de AWS para evitar el acceso no autorizado. Es esencial para mantener la privacidad de los datos, permitir pruebas y análisis seguros y garantizar el cumplimiento de regulaciones como GDPR, HIPAA y PCI DSS.
2. ¿Cómo realiza DataMasque el enmascaramiento de datos en AWS?
DataMasque funciona escaneando fuentes de datos estructurados alojadas en AWS, como Amazon RDS, archivos S3 o bases de datos EC2, y aplicando técnicas de enmascaramiento irreversibles preservando la integridad referencial. Utiliza conjuntos de reglas basados en YAML y admite la implementación a través de AWS Marketplace AMI.
3. ¿Puede DataMasque manejar datos o documentos no estructurados en AWS?
No, DataMasque está diseñado principalmente para formatos de datos estructurados y semiestructurados (por ejemplo, SQL, JSON, CSV). No admite el enmascaramiento de archivos PDF, documentos de Word, correos electrónicos o contenido generado por IA.
4. ¿Qué herramienta es mejor para el enmascaramiento de datos a nivel de documento en AWS?
Para el enmascaramiento de datos no estructurados, como la redacción de información confidencial en archivos PDF, DOCX, correos electrónicos o salidas de GenAI, Data Masker de Avahi es una mejor opción. Utiliza la detección impulsada por GenAI y la redacción con un solo clic para proteger los datos en documentos y flujos de archivos dentro de AWS.
5. ¿Se requiere el enmascaramiento de datos de AWS para el cumplimiento de GDPR o HIPAA?
Sí. Tanto GDPR como HIPAA requieren que las organizaciones limiten la exposición de datos personales. El enmascaramiento de datos ayuda a cumplir esas obligaciones al garantizar que los datos confidenciales se anonimicen en entornos que no son de producción o durante el intercambio de datos externo.



