
TL;DR
|
Una base de datos expuesta es suficiente para desencadenar una infracción del cumplimiento, dañar su reputación y comprometer la confianza del cliente.
A medida que las organizaciones manejan volúmenes cada vez mayores de datos confidenciales, que van desde identificadores personales y registros financieros hasta lógica empresarial patentada, la protección de esos datos se ha convertido en una responsabilidad no negociable.
68% de las organizaciones admiten que almacenan datos confidenciales en múltiples entornos de nube, a menudo sin una visibilidad o control completos. Más del 60% de las filtraciones involucran datos que no estaban correctamente enmascarados, cifrados o anonimizados (Verizon DBIR 2024).
En este entorno, simplemente restringir el acceso ya no es suficiente. Las organizaciones deben implementar estrategias en capas que protejan los datos a lo largo de su ciclo de vida, desde el desarrollo y las pruebas hasta la transmisión y el procesamiento en tiempo real. Aquí es donde entran en juego el enmascaramiento de datos y la ofuscación de datos.
Si bien ambos tienen como objetivo proteger la información confidencial del acceso no autorizado, lo hacen utilizando diferentes enfoques adaptados a otros entornos. Elegir el incorrecto puede provocar lagunas en la seguridad, fricción operativa o incluso exposición legal.
Este blog explorará las diferencias entre el enmascaramiento y la ofuscación de datos al analizar las técnicas subyacentes y los casos de uso prácticos, lo que le ayudará a determinar qué método se alinea mejor con sus objetivos de protección de datos.
Los fundamentos del enmascaramiento de datos: proteja sus datos sin perder su valor
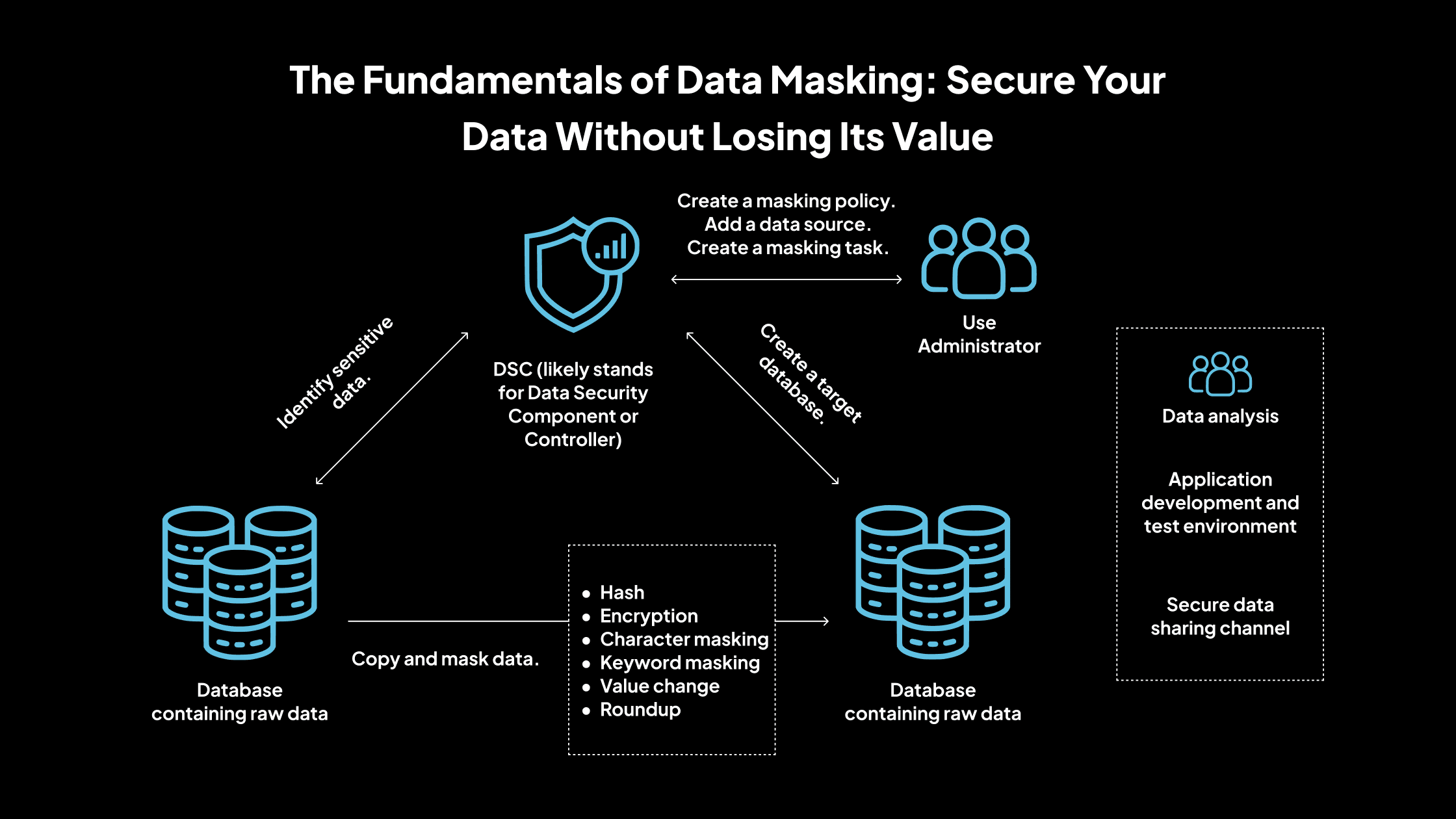
El enmascaramiento de datos es una técnica de seguridad de datos que implica transformar la información confidencial en una versión no confidencial, haciéndola inutilizable para usuarios no autorizados, al tiempo que mantiene su usabilidad para fines autorizados. El objetivo principal es proteger los datos confidenciales, como la información de identificación personal (PII), los registros financieros y la información de salud, del acceso no autorizado, particularmente en entornos que no son de producción, como las pruebas y el desarrollo.
Técnicas comunes de enmascaramiento de datos
1. Sustitución
Esta técnica reemplaza los datos confidenciales con valores ficticios pero realistas. Por ejemplo, los nombres reales se pueden reemplazar con nombres seleccionados al azar de una lista predefinida. Este método mantiene el formato y la apariencia de los datos, lo que lo hace adecuado para fines de prueba y capacitación.
2. Aleatorización
La aleatorización implica reorganizar los datos dentro de un conjunto de datos para interrumpir la asociación entre los elementos de datos. Por ejemplo, los nombres de los empleados se pueden mezclar entre diferentes registros, preservando la estructura de los datos pero oscureciendo las relaciones originales.
3. Anulación
Este método reemplaza los campos de datos confidenciales con valores nulos o en blanco. Si bien elimina eficazmente la información confidencial, puede afectar la usabilidad de los datos para ciertas aplicaciones, ya que la ausencia de datos puede afectar el procesamiento y el análisis.
4. Cifrado
El cifrado transforma los datos en un formato ilegible mediante algoritmos y claves. Solo los usuarios autorizados con la clave de descifrado correcta pueden acceder a los datos originales. Si bien el cifrado proporciona una gran seguridad, requiere una gestión cuidadosa de las claves y puede introducir una sobrecarga de rendimiento.
5. Tokenización
La tokenización reemplaza los datos confidenciales con marcadores de posición no confidenciales, o tokens, que no tienen valor explotable. Los datos originales se almacenan de forma segura y solo los sistemas autorizados pueden asignar tokens a los datos originales. Esta técnica se utiliza comúnmente en los sistemas de procesamiento de pagos.
Tipos de enmascaramiento de datos
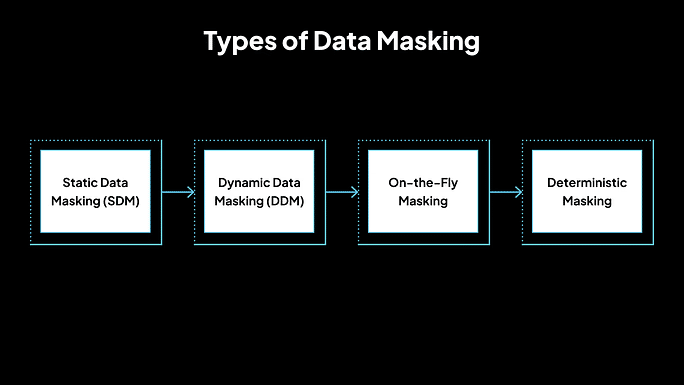
1. Enmascaramiento de datos estáticos (SDM)
SDM implica crear una copia enmascarada de una base de datos, donde los datos confidenciales se reemplazan con datos ficticios. Este conjunto de datos enmascarado se utiliza luego en entornos que no son de producción. Dado que el enmascaramiento se realiza en una copia, los datos de producción originales permanecen intactos. SDM es adecuado para escenarios en los que los datos no necesitan actualizarse con frecuencia.
2. Enmascaramiento de datos dinámicos (DDM)
DDM aplica reglas de enmascaramiento en tiempo real a medida que los usuarios acceden a los datos. Los datos originales en la base de datos permanecen sin cambios, pero los usuarios no autorizados ven valores enmascarados según sus privilegios de acceso. DDM es útil para proteger datos confidenciales en entornos de producción en vivo sin alterar los datos subyacentes.
3. Enmascaramiento sobre la marcha
Este enfoque enmascara los datos en tránsito, generalmente durante la transferencia de datos entre sistemas o entornos. Garantiza que los datos confidenciales estén protegidos durante el proceso de transferencia sin requerir el almacenamiento de los datos enmascarados. El enmascaramiento sobre la marcha es beneficioso en las canalizaciones de integración y despliegue continuos.
4. Enmascaramiento determinista
El enmascaramiento determinista garantiza que un valor de entrada específico siempre se reemplace con el mismo valor enmascarado.
Por ejemplo, el nombre «Alice» siempre se enmascararía como «Eve» en todos los conjuntos de datos. Esta coherencia es crucial para mantener la integridad referencial en diferentes sistemas y conjuntos de datos.
Lo esencial de la ofuscación de datos: cómo protege la información confidencial
La ofuscación de datos es una técnica de seguridad de datos que implica transformar deliberadamente los datos para que sean ininteligibles o difíciles de interpretar para personas no autorizadas.
El objetivo principal es proteger la información confidencial manteniendo su usabilidad para fines autorizados. Esto se logra alterando los valores, las estructuras o las representaciones de los datos sin cambiar la funcionalidad o el formato general de los datos.
Técnicas comunes de ofuscación de datos
1. Cifrado
El cifrado convierte los datos de texto sin formato en texto cifrado utilizando algoritmos y claves criptográficas. Solo los usuarios autorizados con la clave de descifrado correcta pueden revertir los datos a su forma original. El cifrado se utiliza ampliamente para proteger los datos en reposo y en tránsito.
2. Tokenización
La tokenización reemplaza los elementos de datos confidenciales con equivalentes no confidenciales, conocidos como tokens. Estos tokens no tienen ningún significado o valor explotable y se asignan de nuevo a los datos originales a través de un sistema de tokenización seguro. Este método se utiliza comúnmente en el procesamiento de pagos para proteger la información de tarjetas de crédito.
3. Anonimización
La anonimización implica eliminar o modificar los identificadores personales de los conjuntos de datos, lo que hace imposible vincular los datos a un individuo. Esta técnica es crucial para cumplir con las regulaciones de privacidad al compartir datos con fines de investigación o análisis.
4. Codificación
La codificación reorganiza los caracteres o dígitos dentro de los campos de datos para oscurecer la información original. Por ejemplo, codificar un número de teléfono implicaría mezclar sus dígitos, haciéndolo sin sentido para los espectadores no autorizados.
5. Intercambio de datos
El intercambio de datos implica intercambiar elementos de datos dentro de un conjunto de datos para interrumpir la asociación entre los datos y las personas. Por ejemplo, intercambiar direcciones entre registros garantiza que, si bien los datos siguen siendo realistas, ya no corresponden a las personas originales.
Tipos de ofuscación de datos
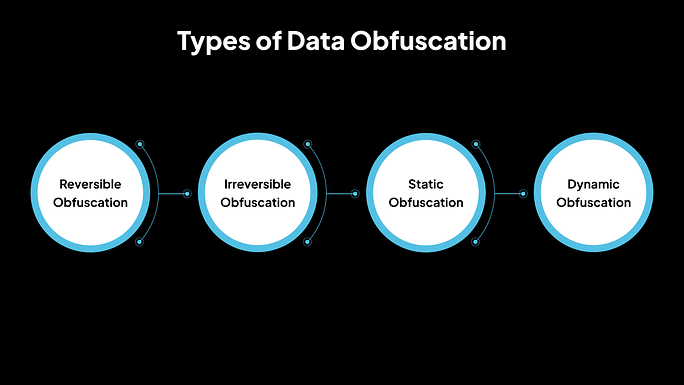
1. Ofuscación reversible
Las técnicas de ofuscación reversible permiten recuperar los datos originales cuando sea necesario. El cifrado y la tokenización entran en esta categoría, ya que permiten a los usuarios autorizados acceder a los datos originales utilizando claves de descifrado o sistemas de asignación de tokens.
2. Ofuscación irreversible
La ofuscación irreversible altera permanentemente los datos, asegurando que no se puedan revertir a su forma original. La anonimización es un excelente ejemplo, donde se eliminan los identificadores personales para proteger la privacidad individual, y los datos originales no se pueden reconstruir.
Por ejemplo, una universidad comparte un conjunto de datos de registros de salud de estudiantes para investigación de salud pública. Todos los nombres, identificaciones y detalles de contacto se eliminan o se alteran irreversiblemente para que los datos no se puedan vincular a ningún individuo.
3. Ofuscación estática
La ofuscación estática se aplica a los datos en reposo, como en bases de datos o archivos, para evitar el acceso no autorizado. Los datos se transforman antes del almacenamiento, asegurando que cualquier acceso no autorizado al medio de almacenamiento produzca solo datos ofuscados.
Por ejemplo, una empresa exporta datos de clientes de un sistema en vivo a un entorno de ensayo para pruebas. Antes de la exportación, todos los nombres, correos electrónicos y números de teléfono se codifican o se reemplazan con marcadores de posición.
4. Ofuscación dinámica
La ofuscación dinámica ocurre en tiempo real, transformando los datos a medida que se acceden o se transmiten. Este enfoque es útil para proteger los datos en aplicaciones donde los datos deben permanecer seguros durante el procesamiento o la comunicación.
Por ejemplo, una empresa exporta datos de clientes de un sistema en vivo a un entorno de ensayo para pruebas. Antes de la exportación, todos los nombres, correos electrónicos y números de teléfono se codifican o se reemplazan con marcadores de posición.
Máscara de datos frente a ofuscación: comparación detallada de características para una toma de decisiones informada
| Característica | Máscara de datos | Ofuscación de datos |
| Propósito | Se utiliza en entornos que no son de producción (pruebas, desarrollo, capacitación). | Se utiliza en producción; oculta los datos durante el uso/transmisión. |
| Reversibilidad | Irreversible. | Puede ser reversible (por ejemplo, cifrado) o irreversible (por ejemplo, anonimización). |
| Utilidad de datos | Mantiene el formato y la usabilidad. | Puede reducir la usabilidad debido a la alteración de los datos. |
| Complejidad | Más complejo, requiere planificación y una comprensión de los datos. | Más simple de implementar; puede sacrificar la precisión o la estructura. |
| Tiempo de implementación | Requiere mucho tiempo; necesita coordinación entre sistemas. | Más rápido con herramientas; varía según los datos y la técnica. |
| Nivel de seguridad | Fuerte para entornos que no son de producción. | Fuerte para la producción; protege contra los riesgos de acceso en vivo. |
| Impacto en el rendimiento | Impacto mínimo en el uso que no es de producción. | Puede afectar el rendimiento en el procesamiento en tiempo real (por ejemplo, sobrecarga de cifrado). |
Esta sección proporciona una comparación detallada entre el enmascaramiento y la ofuscación de datos en varias características críticas. Comprender estas diferencias ayudará a seleccionar la estrategia de protección de datos más adecuada para las necesidades específicas de una organización.
1. Propósito
Enmascaramiento de datos
Se utiliza principalmente para proteger datos confidenciales en entornos que no son de producción, como pruebas, desarrollo y capacitación. Garantiza que, si bien los datos son ficticios, sigan siendo realistas y utilizables para estos fines.
Ofuscación de datos
Su objetivo es ocultar los datos para evitar el acceso no autorizado, a menudo en entornos de producción. Transforma los datos en un formato que es ininteligible o menos útil para los usuarios no autorizados, protegiendo así la información confidencial durante el procesamiento o la transmisión.
2. Reversibilidad
Enmascaramiento de datos
Generalmente es irreversible; una vez que los datos están enmascarados, no se pueden revertir a su forma original. Esto garantiza que la información confidencial permanezca protegida incluso si los datos enmascarados están expuestos.
Ofuscación de datos
Puede ser reversible o irreversible, dependiendo de la técnica utilizada. Por ejemplo, el cifrado es reversible con la clave correcta, mientras que los métodos de anonimización específicos están diseñados para ser irreversibles.
3. Utilidad de datos
Enmascaramiento de datos
Mantiene la usabilidad de los datos para fines específicos, como pruebas y capacitación, al tiempo que preserva la confidencialidad. Los datos enmascarados conservan el formato y las características de los datos originales, lo que permite un uso significativo sin exponer información confidencial.
Ofuscación de datos
Esto puede reducir la usabilidad de los datos, especialmente si el proceso de ofuscación altera significativamente la estructura o el contenido de los datos. Esto puede limitar la aplicabilidad de los datos para operaciones o análisis específicos.
4. Complejidad
Enmascaramiento de datos
A menudo implica procesos complejos para garantizar que los datos enmascarados sigan siendo realistas y mantengan la integridad referencial. Requiere una comprensión profunda de los datos y sus interrelaciones.
Ofuscación de datos
Generalmente es menos complejo y se puede implementar más rápidamente. Sin embargo, la simplicidad puede tener el costo de una menor utilidad o eficacia de los datos en escenarios específicos.
5. Tiempo de implementación
Enmascaramiento de datos
La implementación puede llevar mucho tiempo debido a la necesidad de una planificación cuidadosa para mantener la integridad y la usabilidad de los datos. A menudo requiere la coordinación entre varios sistemas y equipos.
Ofuscación de datos
Generalmente es más rápido de implementar, especialmente cuando se utilizan herramientas o scripts automatizados. Sin embargo, la velocidad de implementación puede variar según la complejidad de los datos y las técnicas de ofuscación utilizadas.
6. Nivel de seguridad
Enmascaramiento de datos
Proporciona un alto nivel de seguridad para entornos que no son de producción al garantizar que los datos confidenciales no se expongan durante las actividades de prueba o desarrollo.
Ofuscación de datos
Ofrece una seguridad sólida en entornos de producción al hacer que los datos sean ininteligibles para los usuarios no autorizados, protegiendo así contra las filtraciones de datos y el acceso no autorizado.
7. Impacto en el rendimiento
Enmascaramiento de datos
Generalmente tiene un impacto mínimo en el rendimiento del sistema, especialmente cuando se aplica a entornos que no son de producción.
Ofuscación de datos
Esto puede afectar el rendimiento, particularmente si se utilizan técnicas de ofuscación complejas, como el cifrado, en escenarios de procesamiento o transmisión de datos en tiempo real.
Máscara de datos frente a ofuscación: ¿qué técnica se adapta a su caso de uso?
Comprender el contexto apropiado para cada técnica es crucial para mantener tanto la seguridad de los datos como la eficacia operativa. A continuación, se muestra una explicación clara de cuándo usar el enmascaramiento y la ofuscación de datos:
Cuándo usar el enmascaramiento de datos
Utilice el enmascaramiento de datos cuando los datos confidenciales deban utilizarse en entornos donde no deban exponerse, como entornos de desarrollo, pruebas, análisis o capacitación.
Los datos enmascarados conservan su estructura y formato. Los datos originales se reemplazan o transforman permanentemente. Es un proceso unidireccional; los datos reales no se pueden recuperar de la versión enmascarada. Los datos enmascarados deben ser lo suficientemente realistas como para permitir pruebas o capacitación válidas sin comprometer la seguridad.
Situaciones ideales
- Cuando los desarrolladores o evaluadores necesitan trabajar con datos realistas pero tienen acceso restringido a información confidencial real.
- Al compartir conjuntos de datos con proveedores externos o equipos internos que no necesitan acceso a datos reales.
Por ejemplo, un proveedor de atención médica necesita proporcionar acceso a bases de datos de pacientes para pruebas de software. Para cumplir con HIPAA y proteger la privacidad del paciente, utilizan el enmascaramiento de datos para reemplazar los nombres, las fechas de nacimiento y los registros médicos con valores ficticios pero realistas. Los desarrolladores aún pueden realizar pruebas funcionales sin acceder a los datos reales del paciente.
Casos de uso prácticos del enmascaramiento de datos
1. Entornos de prueba y desarrollo de software
En el desarrollo de software, los datos realistas son cruciales para las pruebas y la depuración eficaces. Sin embargo, el uso de datos de producción reales plantea importantes riesgos de seguridad. El enmascaramiento de datos permite a los desarrolladores trabajar con datos que reflejan fielmente los escenarios del mundo real sin exponer información confidencial, lo que garantiza el cumplimiento de las regulaciones de protección de datos.
2. Análisis e informes de datos
Los analistas necesitan acceder a los datos para obtener información y tomar decisiones fundamentadas. El enmascaramiento de datos permite el uso de conjuntos de datos significativos para el análisis, a la vez que protege la información confidencial, equilibrando así la utilidad de los datos con las preocupaciones sobre la privacidad.
3. Formación y demostraciones a usuarios
Las sesiones de formación y las demostraciones de productos a menudo requieren el uso de datos para simular escenarios de la vida real. El empleo de datos enmascarados garantiza que la información confidencial no se divulgue inadvertidamente durante estas actividades.
Cuándo usar la ofuscación de datos
Utilice la ofuscación de datos para ocultar o alterar la información, dificultando su interpretación o ingeniería inversa. Esto es especialmente útil para proteger la propiedad intelectual o los datos transitorios durante la comunicación o la ejecución.
La transformación puede ser reversible (por ejemplo, mediante cifrado) o parcialmente reversible, dependiendo del método utilizado. A menudo implica código, scripts, claves de API o archivos de configuración, en lugar de datos estructurados como registros de bases de datos. El objetivo es hacer que los datos o la lógica sean ilegibles o inutilizables para usuarios no autorizados.
Situaciones ideales
- Al distribuir aplicaciones compiladas, el código fuente debe estar protegido.
- Al enviar datos confidenciales a través de API o almacenar credenciales en archivos de configuración.
- Al implementar la seguridad en aplicaciones front-end (por ejemplo, ofuscación de JavaScript para ocultar la lógica empresarial).
Por ejemplo, una empresa SaaS ofrece una herramienta de escritorio descargable. Para proteger los algoritmos propietarios y evitar la ingeniería inversa, la empresa utiliza la ofuscación de código en el software compilado. Además, ofuscan las claves de API utilizadas en sus aplicaciones web para evitar el acceso no autorizado.
Casos prácticos de uso de la ofuscación de datos
 1. Protección de datos en entornos de producción
1. Protección de datos en entornos de producción
En los sistemas de producción en vivo, es fundamental proteger los datos confidenciales, como la información de identificación personal (PII), los registros financieros y la información comercial patentada.
Las técnicas de ofuscación de datos garantizan que, incluso si se produce un acceso no autorizado, los datos expuestos sigan siendo ininteligibles, lo que mitiga los riesgos potenciales.
2. Protección de datos durante la transmisión
Cuando los datos se transmiten a través de redes, especialmente a través de Internet, se vuelven vulnerables a la interceptación. La ofuscación de los datos antes de la transmisión garantiza que, incluso si se interceptan, la información siga siendo ilegible para las partes no autorizadas.
3. Prevención de la ingeniería inversa del código de software
En el desarrollo de software, se emplean técnicas de ofuscación para dificultar la comprensión del código fuente o de los archivos binarios. Esto protege la propiedad intelectual al evitar que los competidores o los actores maliciosos realicen ingeniería inversa de algoritmos o lógica empresarial patentados.
De la planificación a la ejecución: Mejores prácticas para aplicar el enmascaramiento y la ofuscación de datos
Para proteger eficazmente los datos confidenciales mediante el enmascaramiento o la ofuscación, las organizaciones deben seguir prácticas de implementación estructuradas y probadas. A continuación, se indican los pasos esenciales que ayudan a garantizar la seguridad, el cumplimiento y la eficiencia operativa:
-
Mantener un inventario de datos
Mantener un inventario exhaustivo de los datos confidenciales es el primer paso fundamental. Las organizaciones deben identificar:
- ¿Qué datos se consideran confidenciales (por ejemplo, nombres, números de tarjetas de crédito, registros sanitarios)?
- ¿Dónde residen los datos (por ejemplo, bases de datos, sistemas de archivos, entornos en la nube)?
- ¿Cómo se accede a ellos y quién?
Un inventario de datos exhaustivo permite una mejor planificación de las estrategias de enmascaramiento u ofuscación, lo que garantiza que no se pasen por alto datos confidenciales durante la implementación.
-
Controles de acceso
El acceso a los datos confidenciales debe limitarse estrictamente solo a aquellas personas que lo necesiten para realizar su trabajo. Esto implica asignar permisos de acceso basados en roles, utilizar la autenticación multifactor para los sistemas confidenciales y registrar y supervisar todas las actividades de acceso a los datos.
La implementación de controles de acceso sólidos reduce el riesgo de exposición no autorizada de los datos y respalda el cumplimiento de las normas de seguridad.
-
Realizar auditorías periódicas
Las auditorías ayudan a garantizar que los métodos de protección de datos implementados sigan siendo eficaces con el tiempo. Las organizaciones deben programar revisiones periódicas de los procesos de enmascaramiento y ofuscación para garantizar el cumplimiento. Evaluar si todos los datos confidenciales siguen estando protegidos según lo previsto.
Verificar el cumplimiento de las políticas de protección de datos y las normativas externas. Las auditorías también ayudan a identificar cualquier laguna en la implementación y permiten tomar medidas correctivas oportunas.
-
Centrarse en la formación de los empleados
Incluso con controles técnicos sólidos, el error humano puede provocar la exposición de los datos. Es esencial formar a todos los empleados sobre la importancia de la privacidad y la seguridad de los datos. Educar al personal sobre cómo funcionan el enmascaramiento y la ofuscación de datos. Proporcionar directrices específicas sobre el manejo de datos en entornos que no son de producción.
Los programas de formación continua garantizan que los empleados sigan siendo conscientes de sus responsabilidades y comprendan cómo evitar las filtraciones de datos involuntarias.
-
Selección de herramientas
Elegir las herramientas adecuadas es fundamental para una estrategia eficaz de protección de datos. Al seleccionar herramientas de enmascaramiento u ofuscación de datos, tenga en cuenta su compatibilidad con las plataformas y los sistemas de datos existentes, así como la compatibilidad con diversos tipos y formatos de datos.
Funciones de cumplimiento integradas para el RGPD, HIPAA y otras normativas, facilidad de uso y capacidades de automatización. Las herramientas seleccionadas deben alinearse con los objetivos de seguridad de datos de la organización y ampliarse a medida que crece el negocio.
Proteja la información confidencial con la herramienta inteligente de enmascaramiento de datos de Avahi
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi proporciona herramientas que permiten a las organizaciones gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es Data Masker, diseñado para proteger los datos financieros y de identificación personal, a la vez que respalda la eficiencia operativa.
Descripción general del Data Masker de Avahi
El Data Masker de Avahi es una herramienta versátil de protección de datos diseñada para ayudar a las organizaciones a gestionar de forma segura la información confidencial en diversas industrias, incluyendo la atención sanitaria, las finanzas, el comercio minorista y los seguros.
La herramienta permite a los equipos enmascarar datos confidenciales como números de cuenta, registros de pacientes, identificadores personales y detalles de transacciones sin interrumpir los flujos de trabajo operativos.
El Data Masker de Avahi garantiza que solo los usuarios autorizados puedan ver o interactuar con datos confidenciales aplicando técnicas avanzadas de enmascaramiento y aplicando el control de acceso basado en roles. Esto es especialmente importante cuando varios departamentos o proveedores externos acceden a los datos.
Ya sea protegiendo la información de salud del paciente en cumplimiento con HIPAA, anonimizando los registros financieros para PCI DSS o asegurando los datos del cliente para GDPR, la herramienta ayuda a las organizaciones a minimizar el riesgo de acceso no autorizado al tiempo que preserva la usabilidad de los datos para fines de desarrollo, análisis y supervisión del fraude.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, reconocemos la importancia crucial de proteger la información confidencial, a la vez que mantenemos flujos de trabajo operativos perfectos.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programar una llamada de demostración
Preguntas frecuentes (FAQ)
1. ¿Cuál es la principal diferencia entre el enmascaramiento de datos y la ofuscación de datos?
El enmascaramiento de datos reemplaza los datos confidenciales con valores realistas pero ficticios para su uso fuera de producción, mientras que la ofuscación de datos transforma los datos para que sean ininteligibles o difíciles de interpretar, y se utiliza a menudo tanto en entornos de producción como de tránsito.
2. ¿Cuándo debo utilizar el enmascaramiento de datos en lugar de la ofuscación de datos?
El enmascaramiento de datos es más adecuado para entornos de desarrollo, pruebas y formación en los que no son necesarios datos reales. Utilice la ofuscación cuando necesite proteger los datos en vivo durante el procesamiento o la transmisión sin comprometer el flujo operativo.
3. ¿Es el enmascaramiento de datos reversible como el cifrado?
No, la mayoría de las técnicas de enmascaramiento de datos son irreversibles. A diferencia del cifrado o la tokenización, los datos enmascarados no se pueden restaurar a su forma original, lo que mejora la seguridad en los casos de uso que no son de producción.
4. ¿Se considera la tokenización como enmascaramiento de datos u ofuscación de datos?
La tokenización es una forma de ofuscación de datos porque reemplaza los datos confidenciales con marcadores de posición no confidenciales y permite la recuperación a través de un sistema de mapeo seguro.
5. ¿Cumple el enmascaramiento de datos con el RGPD y la HIPAA?
Sí, cuando se implementa correctamente, el enmascaramiento de datos puede ayudar a cumplir con las normativas de privacidad de datos como el RGPD, la HIPAA y la PCI DSS al evitar el acceso no autorizado a la información de identificación personal (PII).



