
TL;DR
|
Un error en el manejo de datos confidenciales puede costar millones o incluso destruir la confianza que llevó años construir.
A medida que las empresas recopilan más datos personales, las preocupaciones sobre la privacidad aumentan considerablemente. Según una encuesta reciente, 70% de los líderes empresariales informan que sus empresas han aumentado la recopilación de datos personales de los consumidores durante el último año. Al mismo tiempo, el 86% de las personas dice que la privacidad de los datos es una preocupación creciente, y el 68% está preocupado por el nivel de recopilación de datos por parte de las empresas.
Estas preocupaciones están impulsando a las organizaciones a reevaluar sus prácticas de recopilación, almacenamiento e intercambio de datos. A medida que las empresas dependen cada vez más de los datos para las operaciones, el análisis y la innovación, los riesgos de un manejo inadecuado de la información confidencial nunca han sido tan altos.
El enmascaramiento de datos y la anonimización de datos desempeñan un papel crucial en la protección de los datos confidenciales contra el acceso no autorizado, garantizando la privacidad y cumpliendo con las estrictas regulaciones como el RGPD, HIPAA, y PCI DSS.
Sin embargo, tienen diferentes propósitos y se adaptan a varios escenarios. Elegir el enfoque incorrecto puede resultar en una exposición innecesaria o la pérdida de la utilidad de los datos. En este blog, analizamos las diferencias entre Enmascaramiento de datos y la anonimización de datos para ayudarlo a comprender cuándo usar cada uno y cómo tomar la decisión correcta para su organización. Exploremos cómo puede proteger los datos de manera efectiva al tiempo que permite un uso de datos seguro y responsable.
Cómo el enmascaramiento de datos protege los datos confidenciales: características, técnicas y casos de uso

El enmascaramiento de datos es una técnica utilizada para ocultar o modificar datos confidenciales, evitando que personas no autorizadas accedan a ellos o los utilicen indebidamente. Aunque los datos están enmascarados, todavía parecen realistas y conservan su formato original. Esto permite que los sistemas de software funcionen correctamente durante las pruebas, el desarrollo o la capacitación sin exponer información confidencial real.
Características esenciales del enmascaramiento de datos
1. Reversible bajo condiciones controladas
En algunos casos, los datos enmascarados se pueden convertir de nuevo a su forma original, pero solo por usuarios autorizados que tengan las herramientas o claves adecuadas. Esto generalmente se hace bajo estrictos controles de seguridad.
2. Conserva el formato y la estructura de los datos
El enmascaramiento de datos mantiene la estructura original de los datos. Por ejemplo, si los datos originales son un número de teléfono de 10 dígitos, los datos enmascarados también se verán como un número de teléfono de 10 dígitos. Esto ayuda a que los sistemas funcionen como deberían sin errores.
3. Se utiliza principalmente en entornos que no son de producción
El enmascaramiento de datos se utiliza principalmente en entornos como pruebas, desarrollo y capacitación. Estas son áreas donde los datos reales no son necesarios, pero los datos de aspecto realista ayudan a verificar o demostrar cómo funciona un sistema.
Técnicas comunes de enmascaramiento de datos
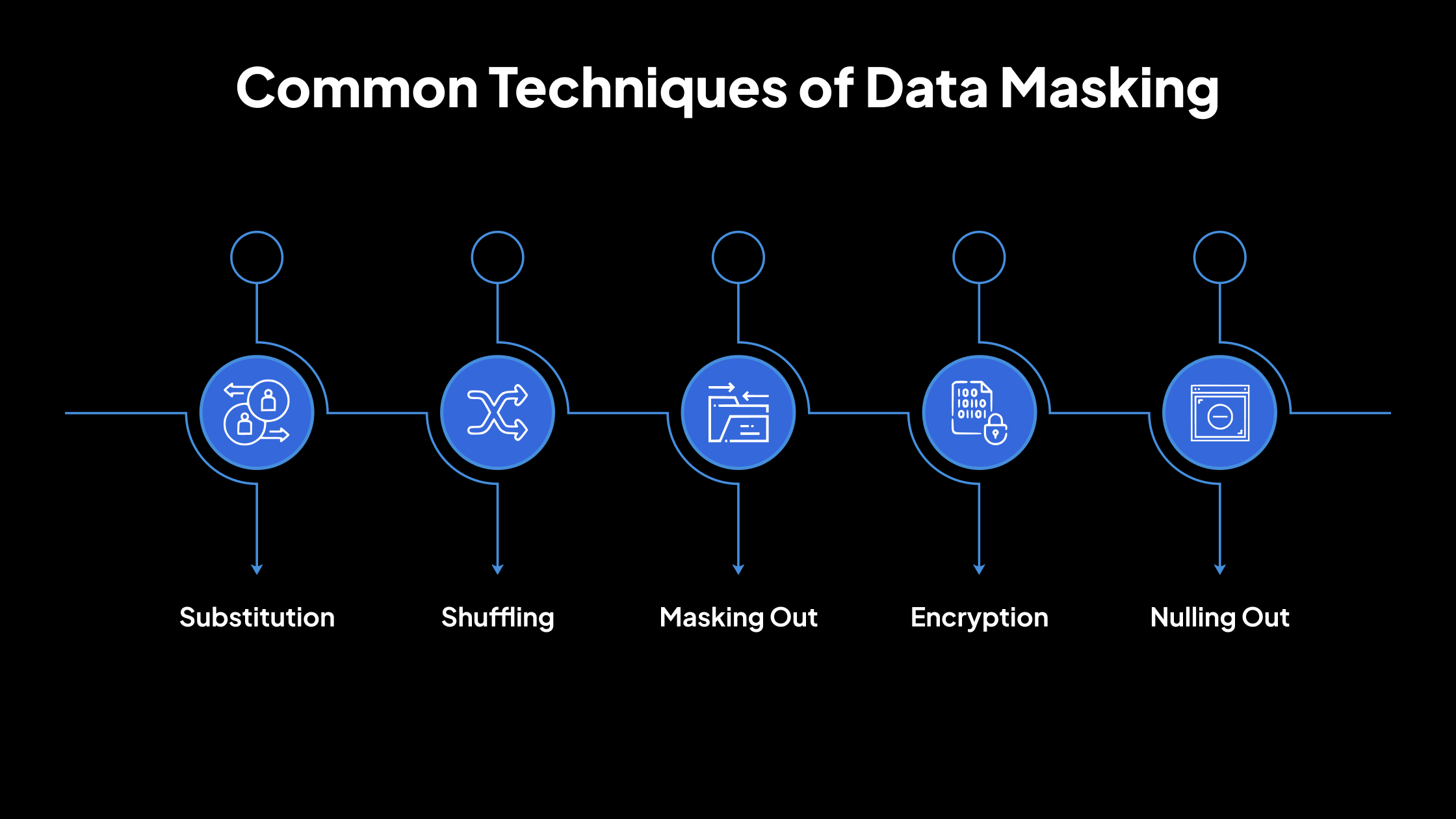
1. Sustitución
La sustitución reemplaza los datos reales con datos falsos pero de aspecto realista. Los valores sustituidos siguen el mismo formato y tipo que los datos originales, lo que garantiza que los sistemas y las aplicaciones sigan funcionando correctamente.
Por ejemplo, en una base de datos de clientes, los nombres reales como John Smith y Priya Patel podrían reemplazarse con nombres como Alex Brown y Maria Gomez extraídos de una lista de nombres comunes. Del mismo modo, una dirección real como 123 Elm Street podría cambiarse por 456 Oak Avenue.
Este método ayuda a crear datos de prueba o capacitación que parecen auténticos sin revelar ninguna información real.
2. Aleatorización
La aleatorización reorganiza o mezcla los valores de los datos dentro de la misma columna para que los registros individuales ya no coincidan con sus propietarios originales. Esto mantiene los datos válidos en términos de tipo y formato, pero los desconecta de las personas o elementos reales a los que pertenecen.
3. Enmascaramiento
El enmascaramiento oculta partes de los datos utilizando símbolos como asteriscos o X. Esto revela solo una parte de los datos mientras protege el resto.
Por ejemplo, un número de tarjeta de crédito como 1234 5678 9012 3456 podría enmascararse como XXXX XXXX XXXX 3456, mostrando solo los últimos cuatro dígitos. Del mismo modo, una dirección de correo electrónico como alex.brown@example.com podría enmascararse como a**@example.com*.
Este método es práctico cuando partes limitadas de los datos deben ser visibles para la verificación, mientras que las partes confidenciales permanecen ocultas.
4. Cifrado
El cifrado convierte los datos en código ilegible utilizando un algoritmo y una clave de cifrado. Los datos solo se pueden convertir de nuevo a su forma original (descifrados) utilizando la clave correcta. El cifrado añade una fuerte protección, pero requiere la gestión de claves y el control de acceso.
El número de cuenta o el número de la seguridad social de un cliente se pueden cifrar para que aparezcan como una cadena de letras y números aleatorios para cualquier persona sin acceso a la clave de descifrado, como GH57@9sJ2! en lugar de 123-45-6789.
Esto garantiza que, incluso si se accede a los datos sin autorización, no se puedan entender sin la clave.
5. Anulación
La anulación elimina por completo los datos confidenciales y los reemplaza con valores vacíos (nulos). La estructura de la base de datos permanece intacta, pero los datos reales ya no están ahí.
Por ejemplo, en una base de datos de prueba, campos como el número de la seguridad social, la fecha de nacimiento o la dirección de correo electrónico podrían establecerse en nulo o valores vacíos. En lugar de mostrar cualquier dato, esos campos permanecen en blanco.
Esto se utiliza a menudo cuando los datos en sí mismos no son necesarios para la prueba, pero la base de datos debe seguir siendo válida.
Beneficios del enmascaramiento de datos
Los datos enmascarados se ven y se comportan como los datos originales. Esto ayuda a los equipos a probar y validar los sistemas en condiciones que se asemejan mucho al uso en el mundo real. Los entornos que no son de producción suelen ser menos seguros que los sistemas en vivo. Al enmascarar los datos, se reduce el riesgo de que alguien acceda a información confidencial real.
El enmascaramiento de datos ayuda a las organizaciones a cumplir con las leyes y regulaciones como el RGPD, HIPAA o PCI DSS. Garantiza que los datos confidenciales no se expongan donde no deberían estar, al tiempo que permite que el trabajo esencial continúe.
Comprensión de la anonimización de datos: características clave, métodos y beneficios
La anonimización de datos es el proceso de eliminar o cambiar permanentemente la información personal en un conjunto de datos para que las personas no puedan ser identificadas. Una vez que los datos se anonimizan, es imposible rastrearlos hasta una persona específica. Esto garantiza que los datos sean seguros para usar en análisis, investigación o intercambio sin comprometer la privacidad.
Características esenciales de la anonimización de datos
Proceso irreversible
La anonimización cambia los datos para que nunca puedan vincularse a la persona original. A diferencia del enmascaramiento de datos, no hay forma de revertir los cambios y recuperar los detalles originales.
Garantiza que las personas no puedan ser reidentificadas
El objetivo de la anonimización es garantizar que nadie pueda determinar la identidad del propietario de los datos, incluso cuando se combina con otros conjuntos de datos. Elimina o altera la información que podría revelar una identidad.
Adecuado para el análisis y el intercambio de datos
Dado que los datos anonimizados ya no contienen identificadores personales, se pueden compartir de forma segura con otras organizaciones, investigadores o el público para su análisis o elaboración de informes.
Técnicas estándar de anonimización de datos
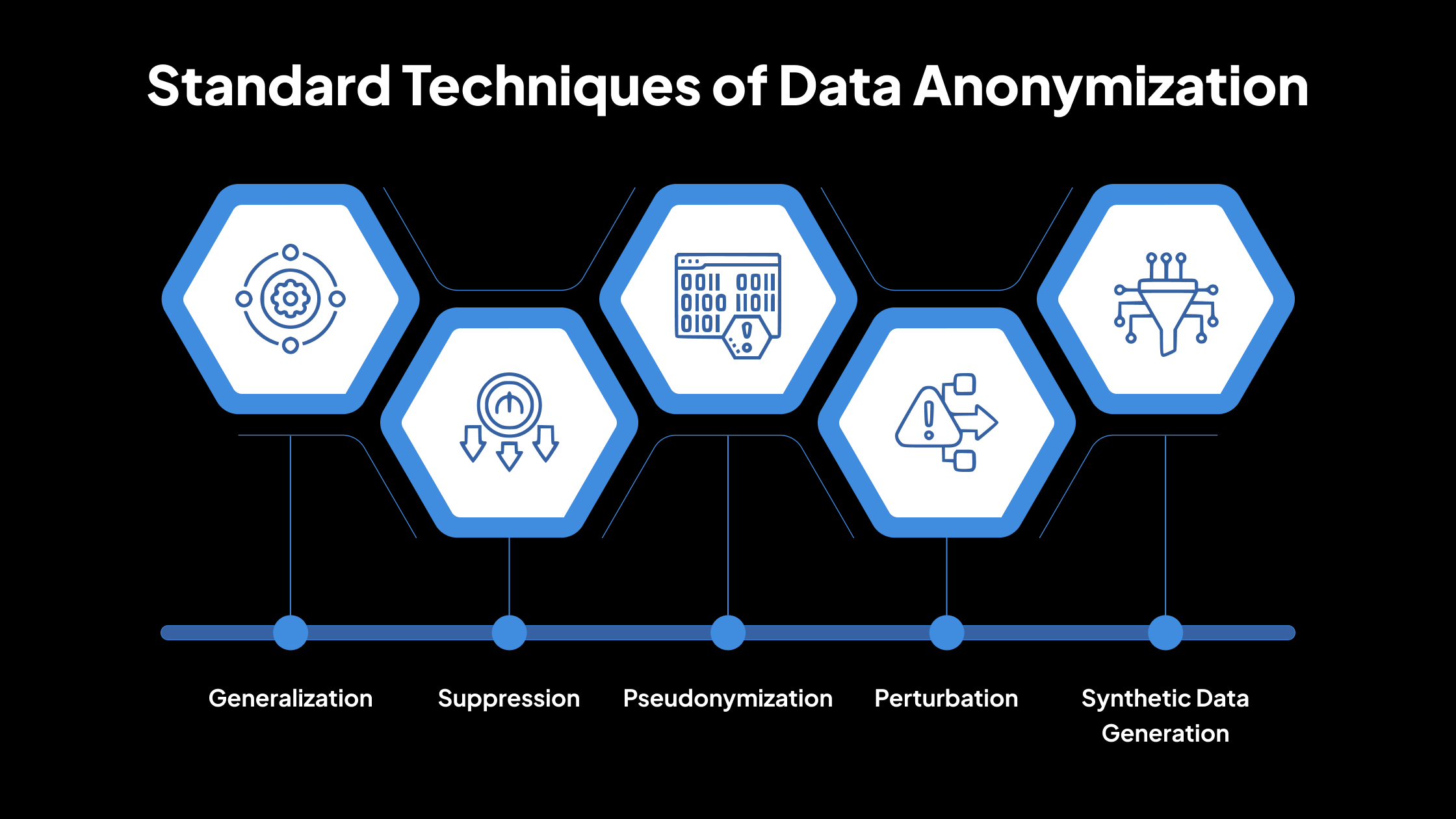
1. Generalización
La generalización reemplaza los datos precisos con categorías más amplias. Por ejemplo, en lugar de mostrar la edad exacta de alguien como 43, los datos podrían mostrar un rango de edad, como «40-50». Del mismo modo, una dirección específica podría cambiarse solo a la ciudad o región. Esto reduce el nivel de detalle para que las personas no puedan ser identificadas fácilmente.
2. Supresión
La supresión elimina ciertas partes de los datos por completo. Por ejemplo, los nombres, los números de la seguridad social o las fechas de nacimiento exactas pueden eliminarse del conjunto de datos. Esto garantiza que la información confidencial no exista en los datos compartidos en absoluto.
3. Seudonimización
La seudonimización reemplaza los identificadores personales, como nombres o identificaciones, con seudónimos (identificadores falsos o generados aleatoriamente).
Si bien esto todavía oculta la identidad real, permite que los datos relacionados con la misma persona se vinculen para su análisis. Sin embargo, los datos seudonimizados no están completamente anonimizados a menos que también se destruya el enlace a la identidad real.
4. Perturbación
La perturbación altera los datos originales añadiendo pequeños cambios o «ruido». Por ejemplo, las cifras de ingresos podrían ajustarse ligeramente para que las estadísticas generales sigan siendo las mismas, pero los valores exactos no sean absolutos. Esto hace que sea más difícil vincular los datos a las personas.
5. Generación de datos sintéticos
La generación de datos sintéticos crea datos completamente artificiales que tienen las mismas propiedades estadísticas que los datos reales.
Por ejemplo, se podría generar un conjunto de datos que refleje los patrones observados en los datos originales, pero que no contenga ninguna información personal real. Este método es útil para compartir datos de forma segura para su análisis o prueba sin arriesgar la privacidad.
Beneficios de la anonimización de datos
La anonimización permite a las organizaciones compartir datos de forma segura, ya que excluye los detalles personales que podrían comprometer la privacidad de alguien.
Al anonimizar los datos, las organizaciones pueden cumplir con las estrictas leyes de privacidad de datos que exigen la protección de la información personal. Los datos anonimizados correctamente garantizan que nadie pueda conectar los datos con personas específicas, incluso cuando se combinan con otros conjuntos de datos.
Enmascaramiento de datos vs. anonimización de datos: un análisis comparativo

Al decidir entre el enmascaramiento de datos y la anonimización de datos, es esencial comprender las diferencias clave entre estas dos técnicas. A continuación, se muestra una comparación detallada de ambas técnicas:
1. Reversibilidad
Enmascaramiento de datos
El enmascaramiento de datos puede ser reversible en condiciones controladas. Esto significa que los datos originales a veces se pueden restaurar a partir de los datos enmascarados, pero solo por usuarios autorizados que tengan acceso a las herramientas, claves o procesos necesarios.
Esta característica puede ser útil si existe una necesidad comercial específica de ver o recuperar los datos originales durante el desarrollo o las pruebas. Sin embargo, esta reversibilidad introduce un nivel de riesgo porque, si no se gestiona adecuadamente, podría exponer información confidencial.
Anonimización de datos
La anonimización de datos es irreversible. Una vez que los datos se han anonimizado, no hay ningún método para rastrearlos hasta el individuo o valor original. Todos los identificadores personales se eliminan o alteran permanentemente de una manera que impide la reidentificación.
Esto hace que la anonimización sea un método más sólido para la protección de la privacidad, especialmente cuando los datos deben compartirse con terceros externos o fuera de la organización.
2. Utilidad de los datos
Enmascaramiento de datos
El enmascaramiento de datos está diseñado para preservar el formato y la estructura de los datos originales. Por ejemplo, si un campo en una base de datos contiene un número de tarjeta de crédito de 16 dígitos, la versión enmascarada también incluirá un número de 16 dígitos que parezca realista.
Esto permite que los sistemas, las aplicaciones y los procesos que dependen de formatos de datos específicos funcionen correctamente durante el desarrollo, las pruebas o la capacitación. Los datos se comportan como datos reales sin exponer información confidencial.
Anonimización de datos
La anonimización de datos puede alterar los datos hasta tal punto que pierdan parte de su utilidad para ciertos tipos de análisis. Por ejemplo, generalizar los datos en rangos o añadir ruido podría reducir su precisión o nivel de detalle.
Si bien los datos anonimizados siguen siendo útiles para una investigación más amplia y el análisis de tendencias, es posible que no sean adecuados para tareas que requieren datos precisos a nivel individual, como el modelado detallado del comportamiento del cliente o las pruebas transaccionales.
3. Nivel de seguridad
Enmascaramiento de datos
El enmascaramiento de datos proporciona un sólido nivel de seguridad para proteger la información confidencial en entornos que no son de producción. Al enmascarar los datos en los sistemas de desarrollo, prueba o capacitación, las organizaciones reducen el riesgo de acceso no autorizado a la información real.
Sin embargo, debido a que el enmascaramiento de datos puede ser reversible en algunos casos, y debido a que los datos enmascarados todavía se almacenan junto con la estructura original, no ofrece el más alto nivel de protección de la privacidad.
Anonimización de datos
La anonimización de datos ofrece un mayor nivel de protección de la privacidad porque garantiza que ningún individuo pueda ser identificado a partir de los datos, incluso si partes no autorizadas acceden a ellos.
Dado que la anonimización es irreversible, elimina el riesgo de exponer información confidencial original a través del propio conjunto de datos. Esto lo hace ideal para situaciones en las que los datos se compartirán externamente, como con instituciones de investigación, socios o el público.
4. Cumplimiento
Enmascaramiento de datos
El enmascaramiento de datos ayuda a las organizaciones a cumplir con los requisitos de cumplimiento en entornos controlados, como los sistemas de desarrollo o prueba. A menudo, es parte de una estrategia de protección de datos más amplia para garantizar que los datos confidenciales no se expongan en áreas donde no son necesarios.
El enmascaramiento puede ayudar a cumplir con las políticas de seguridad internas y los estándares regulatorios específicos que requieren la protección de datos en entornos que no son de producción.
Anonimización de datos
La anonimización de datos es esencial para el cumplimiento cuando los datos se comparten fuera de la organización. Regulaciones como el Reglamento General de Protección de Datos (RGPD) y la Ley de Portabilidad y Responsabilidad del Seguro Médico (HIPAA) requieren o fomentan la anonimización de los datos personales antes de que se compartan externamente.
La anonimización permite a las organizaciones demostrar que están tomando las medidas adecuadas para proteger la privacidad individual y cumplir con sus obligaciones legales relacionadas con el intercambio y el procesamiento de datos.
Casos de uso de enmascaramiento de datos vs. anonimización de datos: elegir el enfoque correcto
La selección entre el enmascaramiento de datos y la anonimización de datos depende de cómo se utilizarán los datos, quién accederá a ellos y qué nivel de protección de la privacidad se requiere. A continuación, se muestra una explicación detallada para ayudarlo a determinar qué método se adapta mejor a sus necesidades específicas.
Cuándo usar el enmascaramiento de datos
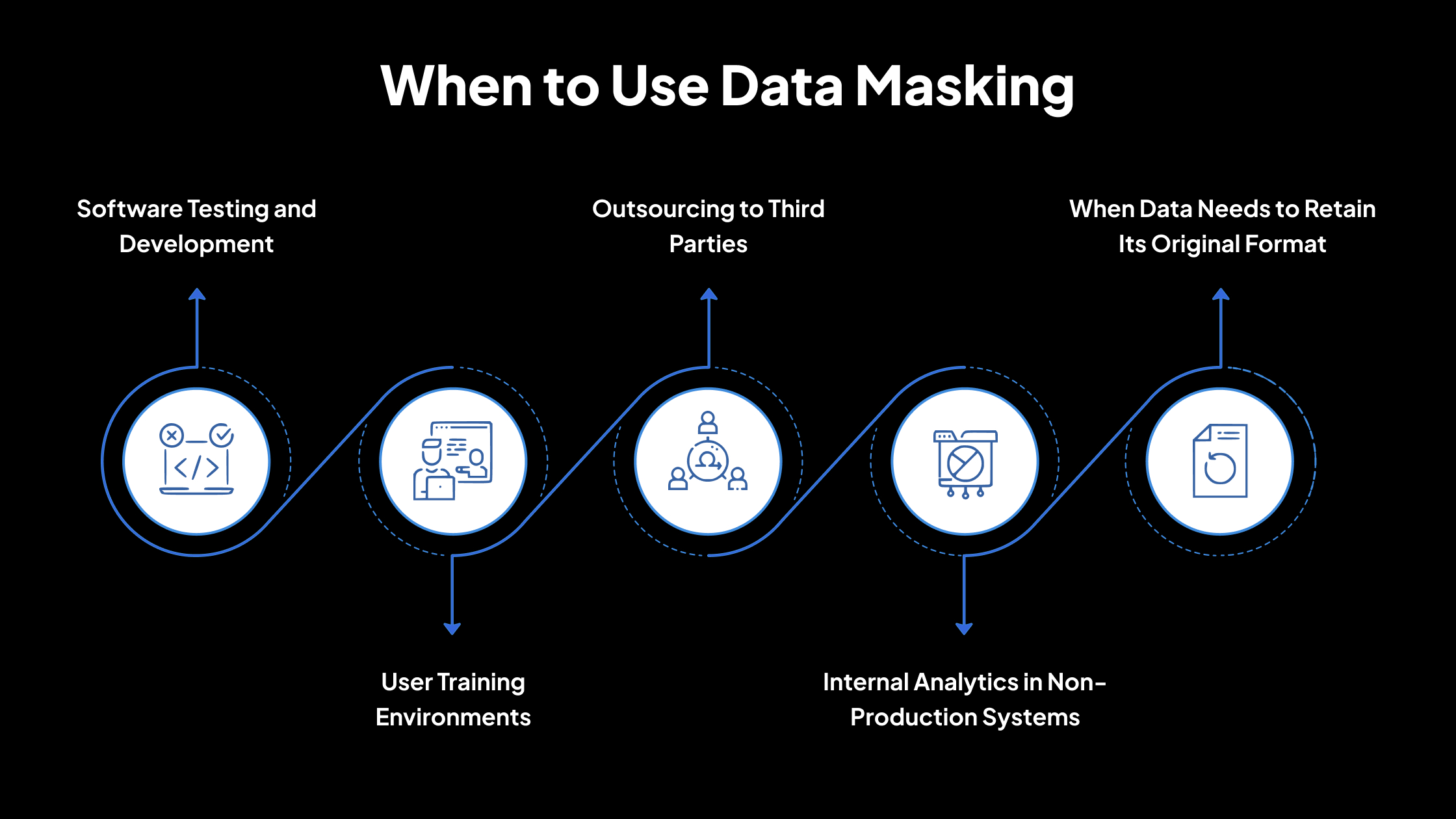
1. Pruebas y desarrollo de software
El enmascaramiento de datos se utiliza comúnmente cuando los desarrolladores o evaluadores necesitan trabajar con datos que se ven y se comportan como los reales. Esto ayuda a garantizar que los sistemas se prueben adecuadamente sin exponer datos confidenciales reales.
2. Entornos de capacitación de usuarios
Cuando los empleados o los usuarios del sistema están siendo capacitados, los datos enmascarados les permiten practicar con información realista. Esto garantiza que la capacitación refleje el uso en el mundo real sin arriesgar la privacidad.
3. Subcontratación a terceros
Cuando el trabajo se entrega a proveedores o contratistas externos que necesitan acceso a sistemas o datos, el enmascaramiento garantiza que los detalles confidenciales estén ocultos al tiempo que proporciona datos que son útiles para sus tareas.
4. Análisis interno en sistemas que no son de producción
Los datos enmascarados se pueden utilizar para informes o análisis internos en entornos que no son sistemas de producción en vivo, donde los controles de seguridad podrían no ser tan estrictos.
5. Cuándo los datos necesitan conservar su formato original
Si los sistemas o procesos dependen de que los datos tengan un formato o estructura particular, como longitudes de número específicas, formatos de fecha o patrones de texto, el enmascaramiento de datos ayuda a mantener esa estructura. Esto permite que los sistemas se ejecuten correctamente sin exponer datos reales.
Cuándo usar la anonimización de datos
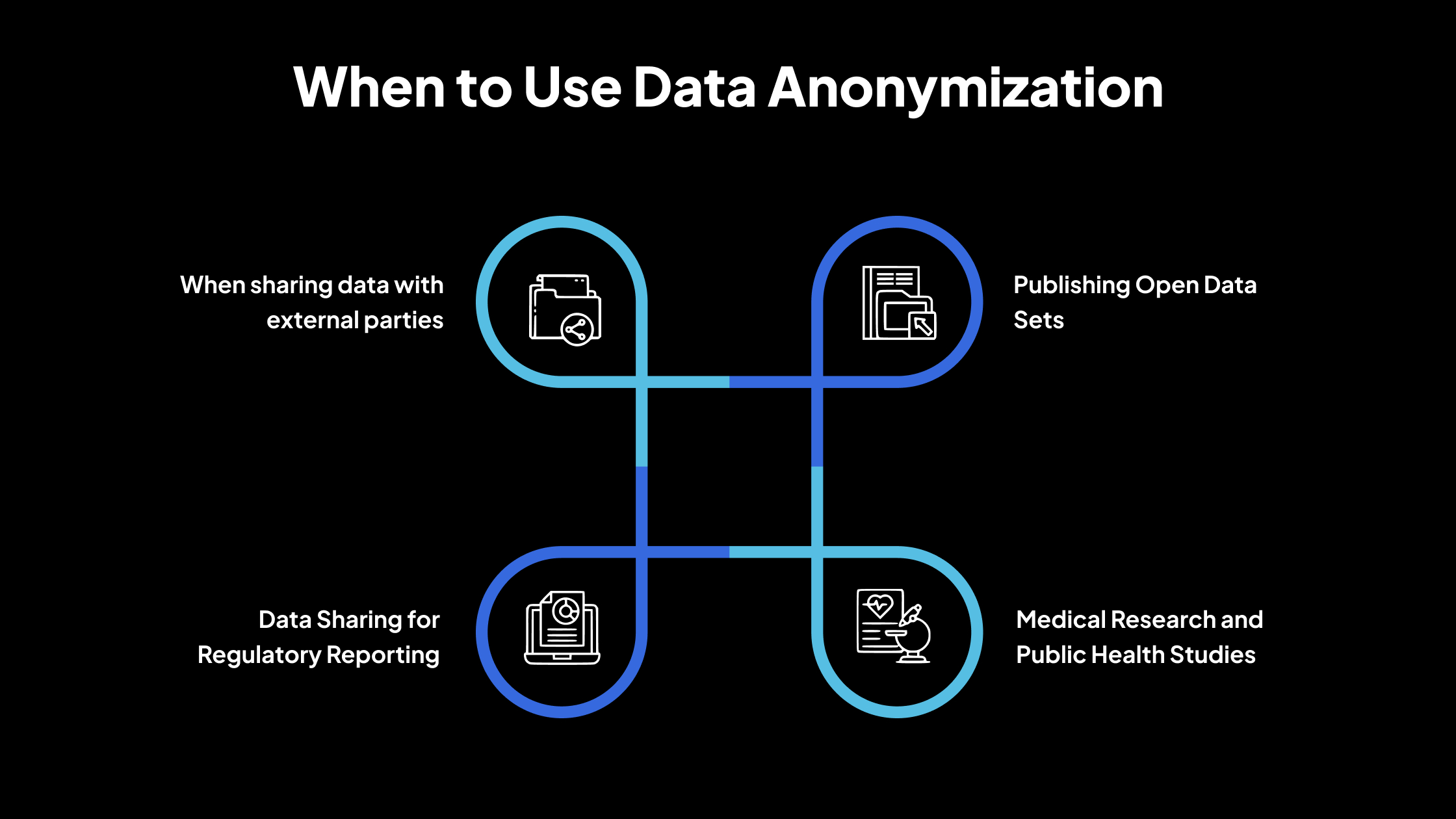
1. Publicación de conjuntos de datos abiertos
Las organizaciones utilizan la anonimización cuando publican datos, como las agencias gubernamentales que comparten datos de salud pública o las empresas que proporcionan informes de transparencia. Esto protege la privacidad individual al tiempo que hace que los datos estén disponibles para uso público.
2. Investigación médica y estudios de salud pública
En la investigación relacionada con la salud, la anonimización es crucial para cumplir con las leyes de privacidad y los estándares éticos. Permite un análisis valioso de las tendencias de salud sin revelar las identidades de las personas.
3. Intercambio de datos para informes regulatorios
Cuando las organizaciones necesitan informar a los reguladores u organismos rectores, los datos anonimizados garantizan el cumplimiento de las leyes de privacidad al tiempo que cumplen con los requisitos de presentación de informes.
4. Cuándo compartir datos con terceros
La anonimización de datos es la opción preferida cuando los datos se comparten fuera de la organización, como con socios, investigadores o proveedores. Garantiza que ninguna información personal pueda vincularse a personas, lo que reduce los riesgos de privacidad.
Aquí hay una mirada a los factores esenciales que deben guiar su decisión.
|
Mejores prácticas de privacidad de datos: formas efectivas de aplicar el enmascaramiento y la anonimización
Ya sea que se utilice el enmascaramiento de datos o la anonimización de datos, es esencial seguir las mejores prácticas para garantizar que la privacidad de los datos se mantenga de manera efectiva. A continuación, se presentan las prácticas esenciales que las organizaciones deben seguir al aplicar estas técnicas.
1. Comprender el propósito del uso de datos
Antes de aplicar cualquier método, defina claramente por qué se necesitan los datos y cómo se utilizarán. Esto ayuda a determinar el nivel adecuado de protección de datos. Por ejemplo, utilice el enmascaramiento de datos para pruebas internas y la anonimización para el intercambio externo.
2. Aplicar el principio del mínimo privilegio
Conceda acceso solo a aquellos que lo necesiten. Asegúrese de que solo el personal autorizado pueda ver o manejar datos enmascarados o anonimizados, lo que reduce el riesgo de exposición accidental.
3. Revisar y actualizar las técnicas con regularidad
Los riesgos de privacidad de los datos y los requisitos reglamentarios están sujetos a cambios con el tiempo. Revise los procesos de enmascaramiento y anonimización con regularidad para asegurarse de que estén actualizados y sigan cumpliendo con las políticas internas y las regulaciones externas.
4. Realizar evaluaciones de riesgos
Antes de compartir o utilizar datos enmascarados o anonimizados, evalúe el riesgo de reidentificación. Esto es especialmente importante cuando se combinan conjuntos de datos o se comparten datos externamente.
5. Documentar los procesos de protección de datos
Mantenga registros claros de cómo se aplicó el enmascaramiento o la anonimización de datos para garantizar la transparencia y la rendición de cuentas. Esto incluye las técnicas utilizadas, las personas que las aplicaron y las razones por las que se seleccionó el enfoque. La documentación ayuda a demostrar el cumplimiento de las leyes y los estándares.
6. Utilice herramientas y tecnologías de confianza
Elija herramientas de software confiables diseñadas para el enmascaramiento o la anonimización de datos. Asegúrese de que la herramienta cumpla con los estándares de seguridad y se ajuste a las necesidades de protección de datos de su organización.
7. Pruebe la utilidad de los datos
Después de enmascarar o anonimizar, pruebe los datos para confirmar que aún cumplen con los requisitos de su uso previsto. Por ejemplo, verifique que los datos enmascarados funcionen correctamente en los sistemas de prueba, o que los datos anonimizados sigan admitiendo un análisis significativo.
Agilización del acceso seguro con la herramienta inteligente de enmascaramiento de datos de Avahi
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi proporciona herramientas que permiten a las organizaciones gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es Data Masker, diseñado para proteger los datos financieros y de identificación personal, a la vez que respalda la eficiencia operativa.
Descripción general del Data Masker de Avahi
El Data Masker de Avahi es una herramienta versátil de protección de datos diseñada para ayudar a las organizaciones a gestionar de forma segura la información confidencial en diversas industrias, incluyendo la atención sanitaria, las finanzas, el comercio minorista y los seguros.
Cómo funciona la función de enmascaramiento de datos
El proceso de enmascaramiento de información confidencial utilizando el Data Masker de Avahi es intuitivo y está impulsado por la IA:
1. Cargar archivo
Los usuarios comienzan cargando el conjunto de datos o el archivo que contiene información confidencial a través de la plataforma Avahi.
2. Vista previa de los datos
Una vez cargada, la herramienta muestra el contenido estructurado, destacando los campos que normalmente se consideran confidenciales (por ejemplo, PAN, nombres, fechas de nacimiento).
3. Haga clic en la opción ‘Enmascarar datos’
A continuación, los usuarios inician el proceso de enmascaramiento seleccionando la opción ‘Enmascarar datos’ de la interfaz.
4. Transformación impulsada por la IA
Entre bastidores, Avahi utiliza algoritmos inteligentes y reglas predefinidas para identificar y enmascarar los valores de datos confidenciales. Esta transformación garantiza que los datos enmascarados mantengan su formato y usabilidad, pero no contengan la información original.
5. Salida segura
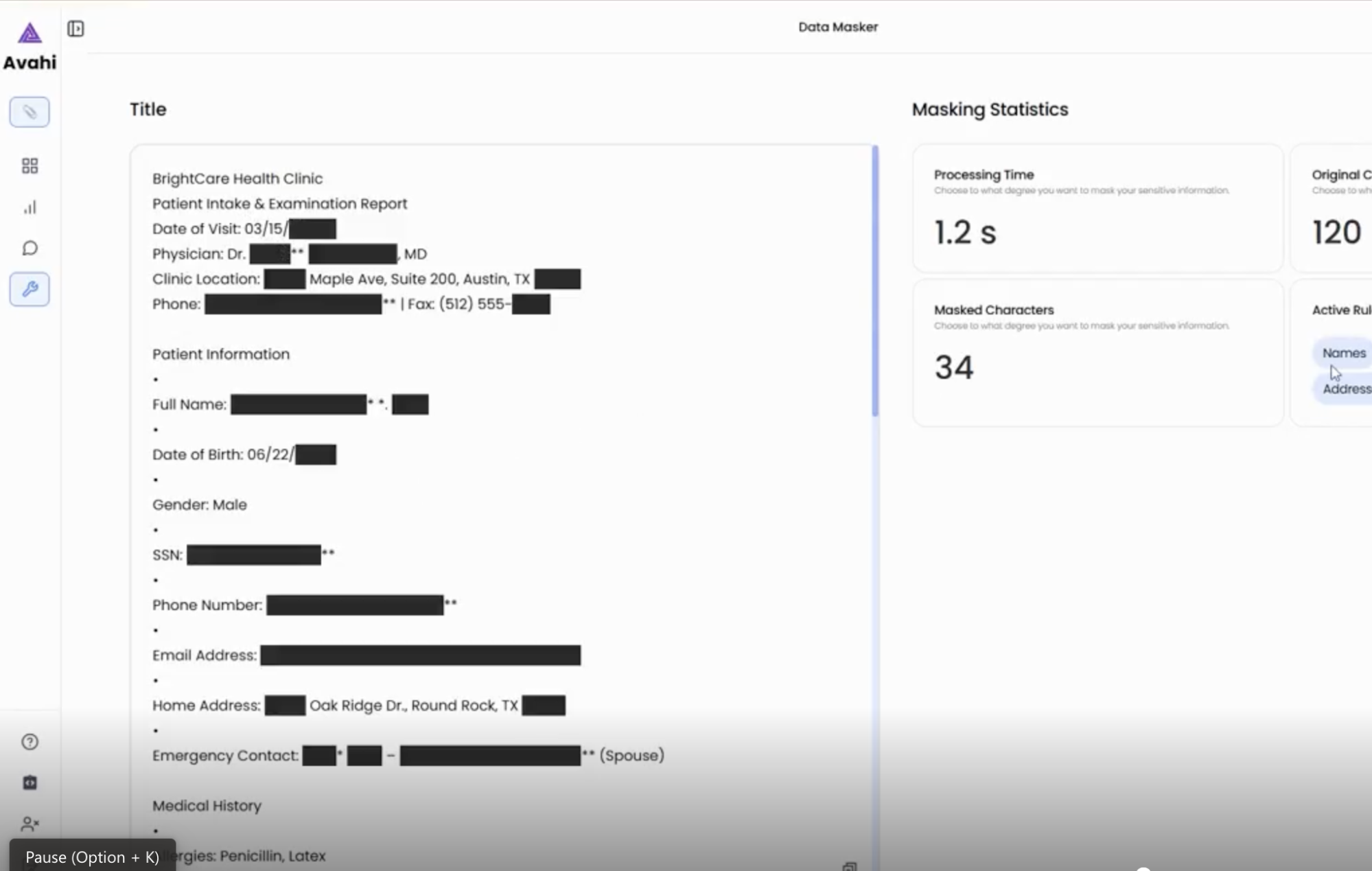
El archivo resultante muestra valores ofuscados en lugar del contenido confidencial original, que se puede utilizar de forma segura para el análisis de fraude, la elaboración de informes o la colaboración con terceros.
El Data Masker de Avahi integra la automatización, los controles fáciles de usar y el enmascaramiento seguro impulsado por la IA para garantizar el cumplimiento normativo (por ejemplo, PCI DSS) al tiempo que minimiza la fricción operativa.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, reconocemos la importancia crucial de salvaguardar la información confidencial al tiempo que mantenemos flujos de trabajo operativos fluidos.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programe una llamada de demostración.
Preguntas frecuentes
1. ¿Cuál es la diferencia entre el enmascaramiento de datos y la anonimización de datos?
El enmascaramiento de datos oculta los datos confidenciales alterándolos mientras se conserva su estructura, a menudo con fines de prueba o capacitación. La anonimización de datos elimina permanentemente los identificadores, lo que garantiza que las personas no puedan ser identificadas, normalmente con fines de intercambio externo o investigación.
2. ¿Cuándo debo usar el enmascaramiento de datos en lugar de la anonimización de datos?
El enmascaramiento de datos es más adecuado para entornos internos, como pruebas, desarrollo o capacitación de usuarios, donde se requiere un formato de datos realista, pero los detalles confidenciales deben permanecer protegidos.
3. ¿Es la anonimización de datos mejor para el cumplimiento del RGPD que el enmascaramiento de datos?
Sí, la anonimización de datos normalmente se requiere para el cumplimiento del RGPD cuando los datos se comparten externamente, ya que garantiza que las personas no puedan ser reidentificadas. El enmascaramiento puede ser suficiente para entornos internos controlados.
4. ¿Se pueden combinar el enmascaramiento de datos y la anonimización de datos?
Sí, las organizaciones pueden combinar ambos métodos, utilizando el enmascaramiento para entornos internos que no son de producción y la anonimización para el intercambio de datos externos, para cumplir con diferentes requisitos de seguridad y cumplimiento.
5. ¿Los datos anonimizados siguen funcionando para el análisis?
Sí, los datos anonimizados aún pueden admitir el análisis, especialmente para las tendencias y los patrones, aunque pueden perder algo de precisión para las perspectivas a nivel individual debido a la generalización de los datos o al ruido añadido.



