
TL;DR
|
¿Confiaría sus datos más confidenciales a alguien que está probando una función de software?
Podría estar haciéndolo si su método de protección de datos no se elige cuidadosamente.
Según un informe de IBM de 2024, casi el 60% de las filtraciones de datos en entornos que no son de producción fueron causadas por el uso de datos reales sin protección durante las pruebas y el desarrollo.
Si bien muchas empresas se centran en proteger las bases de datos de producción, los entornos de prueba a menudo se convierten en el eslabón más débil, principalmente cuando se utilizan métodos inadecuados como la aleatorización básica sin comprender completamente las consecuencias.
Aquí es donde muchos equipos fallan: confunden la aleatorización de datos con el enmascaramiento de datos.
Aunque ambos tienen como objetivo ocultar información confidencial, sus similitudes son solo superficiales. Estas técnicas difieren significativamente en propósito, nivel de protección, alineación con el cumplimiento y usabilidad práctica. Aplicar incorrectamente uno en lugar del otro podría comprometer la integridad del sistema, exponer datos confidenciales o incluso violar las regulaciones de protección de datos.
Entonces, ¿cómo sabe cuál debe usar su empresa?
En este blog, exploraremos las diferencias fundamentales entre la aleatorización y el enmascaramiento de datos, cómo funciona cada técnica, cuándo usarla y por qué tomar la decisión correcta nunca ha sido más crítico. Ya sea que esté creando software, analizando el comportamiento del cliente o trabajando en una industria regulada, este blog le ayudará a proteger sus datos correctamente.
Comprensión de la aleatorización de datos: definición, tipos y casos de uso
La aleatorización de datos es un método utilizado para proteger datos confidenciales alterando aleatoriamente sus valores originales. El objetivo principal es hacer que los datos sean irreconocibles manteniendo su formato y estructura originales (como la longitud de la cadena, el tipo de datos o el patrón de caracteres). A diferencia del cifrado o el enmascaramiento, la aleatorización no tiene como objetivo preservar la usabilidad de los datos, solo el formato.
Por ejemplo, un nombre de cliente como «Alex Smith» puede ser aleatorizado a algo como «mhtiS nhoJ». El nuevo valor no tiene sentido, pero parece estructuralmente similar al original.
Cómo funciona
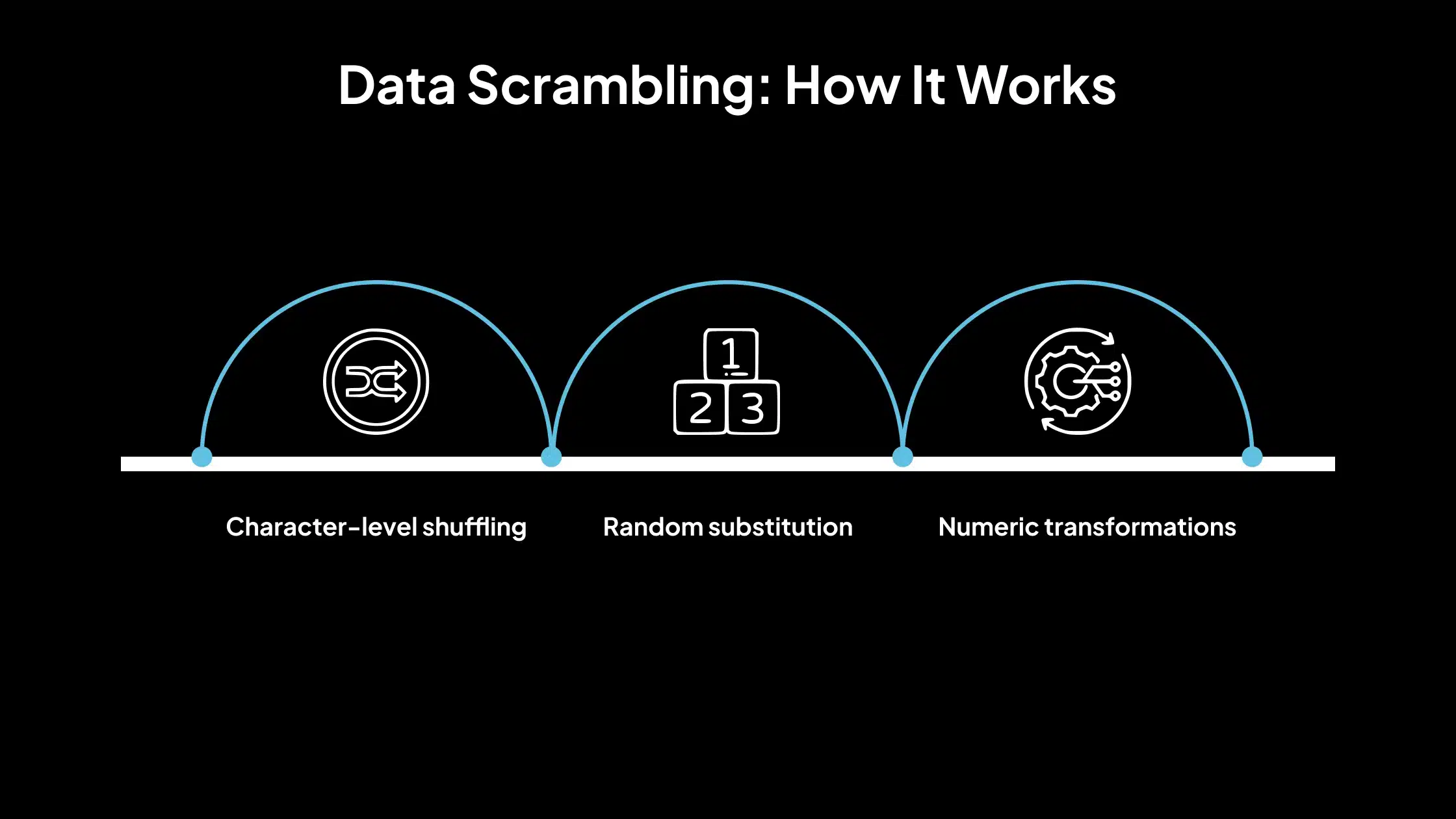
La aleatorización de datos funciona a través de técnicas de aleatorización que cambian los datos reales manteniendo los requisitos técnicos (por ejemplo, longitud, tipo de carácter). Se implementa utilizando scripts o herramientas que aplican:
- Mezcla a nivel de carácter: Reorganiza los caracteres dentro de una cadena aleatoriamente.
Ejemplo: «Tigre» → «reTgi»
- Sustitución aleatoria: Reemplaza caracteres o dígitos con otros de un conjunto predefinido. Ejemplo: «54321» → «83917»
- Transformaciones numéricas: Aplica cambios aritméticos o pseudoaleatorios a los campos numéricos.
Ejemplo: Salario = 60000 → 18429
Estos métodos garantizan que el esquema de la base de datos permanezca intacto y que no se produzcan errores cuando los datos se utilizan en un entorno de prueba.
Tipos de aleatorización de datos
- Aleatorización a nivel de carácter
Este método modifica los datos a nivel de carácter dentro de campos individuales. Los caracteres originales se conservan pero se reorganizan aleatoriamente. Por ejemplo: Original: «David» y Aleatorizado: «aDvid» o «vDaid»
El formato (por ejemplo, cadena de 5 letras) sigue siendo el mismo. No conserva ningún significado semántico.
A menudo se utiliza para nombres, direcciones de correo electrónico o campos de ID.
- Aleatorización a nivel de campo
En este tipo, el proceso de aleatorización se dirige a valores de campo completos sustituyéndolos por entradas generadas aleatoriamente o reorganizadas.
Por ejemplo: Número de teléfono original: 98176 y Número de teléfono aleatorizado: 76189
Se conserva la estructura numérica o alfanumérica. Esto es eficaz para campos como números de teléfono, fechas, códigos postales, etc. A menudo se utiliza donde la validación de formato es necesaria, pero los datos reales no lo son.
Propósito de la aleatorización de datos
El propósito principal de la aleatorización de datos es ocultar información confidencial para evitar el uso indebido o la exposición de datos durante las operaciones internas, como el desarrollo de aplicaciones, las pruebas de la interfaz de usuario, las migraciones de bases de datos y las pruebas de rendimiento/carga.
Es beneficioso cuando los valores de datos reales no son necesarios, pero el formato y la estructura de los datos deben seguir siendo válidos para que el comportamiento de la aplicación sea realista.
Pros y contras de la aleatorización de datos

Casos de uso ideales
La aleatorización de datos es más adecuada para entornos que no son de producción donde el realismo de los datos no es esencial. Los escenarios comunes incluyen:
- Pruebas de software: Garantiza que las aplicaciones funcionen como se espera sin exponer los datos reales del usuario.
- Prototipos de UI/UX: Los diseñadores y desarrolladores pueden completar las vistas front-end sin necesidad de contenido real.
- Pruebas de formato de base de datos: Verifica la integridad del esquema y la lógica de consulta utilizando datos estructurados pero falsos.
- Formación de equipos técnicos: Ayuda a los DBA y desarrolladores a practicar operaciones en conjuntos de datos seguros y aleatorizados.
La aleatorización no debe utilizarse cuando los datos necesitan conservar relaciones del mundo real o cuando se requiere el cumplimiento de las regulaciones de privacidad de datos.
¿Qué es el enmascaramiento de datos? Una solución inteligente para datos seguros y utilizables
El enmascaramiento de datos reemplaza intencionalmente los elementos de datos confidenciales, como la información de identificación personal (PII), los registros financieros o los detalles de salud, con valores realistas pero ficticios. A diferencia de la aleatorización de datos, los datos enmascarados siguen siendo utilizables y significativos para fines de prueba, formación o desarrollo, al tiempo que protegen su forma original de la exposición.
Por ejemplo, el nombre real del cliente «Peterson Smith» podría enmascararse como «Michael Davis», manteniendo la misma estructura y tipo de datos.
Cómo funciona
El enmascaramiento de datos funciona ofuscando los datos originales utilizando técnicas sistemáticas que preservan el formato y las relaciones de datos. Los métodos de enmascaramiento más comunes incluyen:
- Sustitución: Reemplaza los datos reales con valores ficticios realistas de una lista predefinida.
Ejemplo: Tarjeta de crédito = 4532 8890 1123 0009 → 4916 3456 7788 2211
- Mezcla: Reasignación aleatoria de valores de datos dentro de una columna para mantener las características estadísticas. Un ejemplo es el intercambio de códigos postales entre usuarios.
- Tokenización: Reemplaza los datos confidenciales con tokens no confidenciales que se pueden revertir a través de una bóveda de tokens segura.
- Cifrado con superposición enmascarada: Cifra los datos y presenta solo versiones enmascaradas a usuarios no autorizados.
Estos métodos se implementan utilizando enfoques estáticos o dinámicos. El enmascaramiento de datos estático aplica el enmascaramiento a una copia del conjunto de datos y se utiliza comúnmente en entornos que no son de producción. El enmascaramiento de datos dinámico se aplica en tiempo real en función de los roles de acceso del usuario sin alterar los datos originales.
Tipos de enmascaramiento de datos
1. Enmascaramiento que conserva el formato
Este método reemplaza los datos confidenciales con valores que conservan el formato original (por ejemplo, longitud de la cadena, caracteres especiales). Esto mantiene las validaciones de la aplicación funcionales sin revelar datos reales.
Por ejemplo, el correo electrónico original, alex.jones@example.com, se puede enmascarar a mark.green@demo.org
2. Enmascaramiento determinista
La misma entrada siempre produce la misma salida enmascarada, útil cuando es necesaria la coherencia entre sistemas o conjuntos de datos. Se utiliza para la integridad referencial en bases de datos enmascaradas. Por ejemplo: Entrada Alice → siempre se enmascara como EEllen en cada tabla.
3. Enmascaramiento no determinista
Cada instancia de los mismos datos puede resultar en un valor enmascarado diferente. Por ejemplo, Alice → Ellen en un registro, Maria en otro. Esto permite una mayor seguridad a costa de la coherencia.
Propósito del enmascaramiento de datos
El enmascaramiento de datos protege principalmente los datos confidenciales al tiempo que conserva su valor analítico u operativo. Permite a las organizaciones compartir datos realistas con desarrolladores, evaluadores de control de calidad, analistas o proveedores externos y cumplir con las regulaciones de privacidad (por ejemplo, GDPR, HIPAA, PCI DSS).
Minimiza el riesgo de fugas de datos de entornos que no son de producción. Al enmascarar los datos, las empresas pueden mantener los flujos de trabajo empresariales sin comprometer la seguridad.
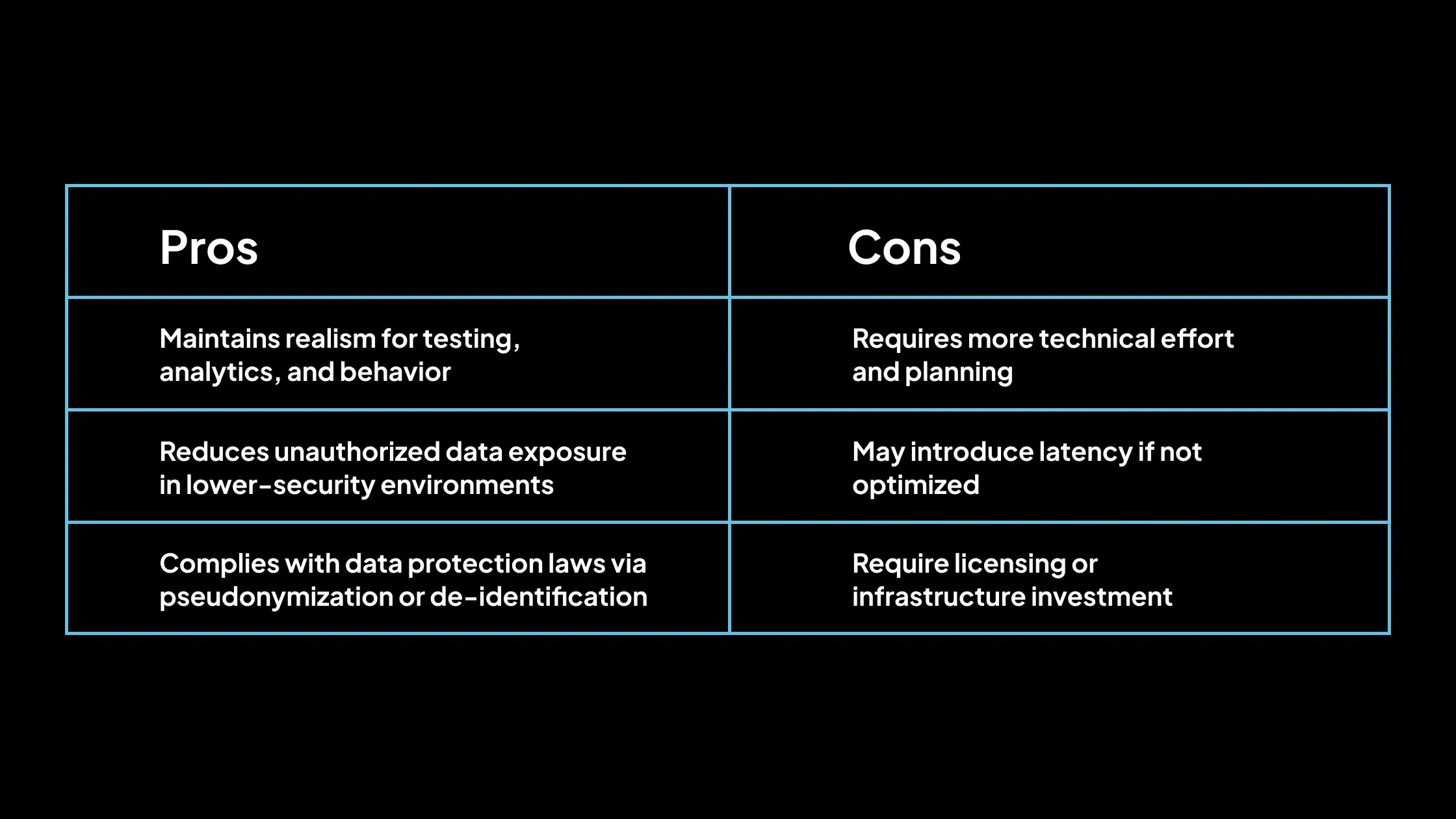
Pros y contras del enmascaramiento de datos
Casos de uso ideales
Se prefiere el enmascaramiento de datos cuando los datos deben ser realistas, analizables y cumplir con la privacidad. Los escenarios comunes incluyen:
- Pruebas de aceptación del usuario (UAT): Garantiza escenarios de prueba del mundo real con datos enmascarados realistas.
- Análisis de datos: Los analistas pueden obtener información sin acceder a las verdaderas identidades de los clientes.
- Formación y educación: Ayuda a formar equipos internos o modelos de IA/ML utilizando datos significativos pero seguros.
- Colaboración con terceros: Permite el intercambio seguro de datos con proveedores externos, auditores o consultores.
- Pruebas de migración a la nube: Protege la PII durante las transiciones de datos desde entornos locales a entornos en la nube.
El enmascaramiento de datos es significativo en industrias con estrictos requisitos de cumplimiento como las finanzas, la atención médica y los seguros.
Aleatorización vs. Enmascaramiento de datos: desglose de las diferencias técnicas y prácticas
A continuación, se presentan los puntos esenciales que explican la diferencia entre la aleatorización y el enmascaramiento de datos, lo que le ayuda a elegir el método adecuado para sus necesidades de protección de datos.
1. Realismo de los datos
Aleatorización de datos
Los datos aleatorizados no conservan ninguna semejanza significativa con los valores originales. La transformación es aleatoria, lo que elimina cualquier valor contextual o semántico. Esto limita la utilidad de los datos aleatorizados para simulaciones realistas, flujos de trabajo de prueba que se basan en patrones específicos o modelado del comportamiento del usuario.
Enmascaramiento de datos
Los datos enmascarados están diseñados para ser realistas al tiempo que protegen el contenido confidencial. Aunque los datos se reemplazan, los valores sustituidos siguen patrones lógicos y restricciones de dominio (por ejemplo, nombres realistas, formatos de correo electrónico válidos). Esto permite un análisis significativo y pruebas funcionales al tiempo que oculta detalles personales o confidenciales.
2. Reversibilidad
Aleatorización de datos
Una vez que los datos se aleatorizan, no se pueden revertir a su forma original. El proceso es irreversible por diseño, ya que no se conserva ninguna asignación entre los valores originales y los aleatorizados. Esto lo hace inadecuado para escenarios donde se requiere auditabilidad o restauración de datos.
Enmascaramiento de datos
El enmascaramiento de datos puede ser reversible o irreversible, dependiendo del método utilizado. Por ejemplo, la tokenización permite la reversibilidad controlada a través de bóvedas de tokens seguras, lo que permite la recuperación cuando es necesario. Esta flexibilidad admite casos de uso que exigen tanto la protección de datos como la trazabilidad opcional.
3. Compatibilidad con el cumplimiento
Aleatorización de datos
La aleatorización de datos no cumple con los requisitos de las regulaciones de protección de datos como GDPR, HIPAA o PCI DSS. Dado que no ofrece ningún registro de auditoría, control o verificación de las medidas de protección, no se considera un método compatible para el manejo de datos confidenciales o regulados.
Enmascaramiento de datos
El enmascaramiento de datos es ampliamente reconocido como un enfoque compatible con el cumplimiento. Admite la seudonimización y la desidentificación, alineándose con los marcos legales y regulatorios. Las técnicas de enmascaramiento implementadas correctamente ayudan a las organizaciones a cumplir con los requisitos de seguridad, privacidad y auditoría.
4. Complejidad
Aleatorización de datos
La aleatorización es relativamente sencilla de implementar. Por lo general, implica scripts ligeros o funciones básicas de base de datos que aleatorizan caracteres o valores. Requiere una configuración mínima y se utiliza a menudo cuando la seguridad de los datos no es la principal preocupación.
Enmascaramiento de datos
El enmascaramiento introduce más complejidad debido a la preservación de la integridad, la coherencia y el realismo de los datos. Puede requerir herramientas especializadas, reglas de transformación que preserven el formato e integración de control de acceso basado en roles. Esta complejidad añadida admite casos de uso más amplios y necesidades de cumplimiento.
5. Idoneidad del caso de uso
Aleatorización de datos
Es más adecuado para entornos de desarrollo o prueba en etapa inicial donde solo es necesario validar la estructura de datos. Es ideal cuando no se requiere contenido realista y el objetivo es proteger los valores originales de la exposición.
Enmascaramiento de datos
Es más adecuado para pruebas funcionales, análisis, formación de usuarios o intercambio de datos con terceros donde los datos deben verse y comportarse como datos reales. Admite escenarios complejos como pruebas de rendimiento, formación de IA o pruebas de integración en sistemas con integridad referencial.
6. Seguridad
Aleatorización de datos
Esto proporciona un nivel básico de protección de datos al eliminar la información identificable. Sin embargo, su solidez de seguridad es moderada e insuficiente para entornos de alto riesgo porque carece de reversibilidad, mecanismos de control o transformaciones conscientes del contexto.
Enmascaramiento de datos
Ofrece un nivel más sólido de seguridad de datos, particularmente cuando se implementa con métodos estructurados como el enmascaramiento dinámico, la tokenización o las políticas de enmascaramiento basadas en roles. Evita el acceso no autorizado al tiempo que permite operaciones legítimas en datos seguros y desidentificados.

Aleatorización vs. Enmascaramiento de datos: cumplimiento y consideraciones regulatorias
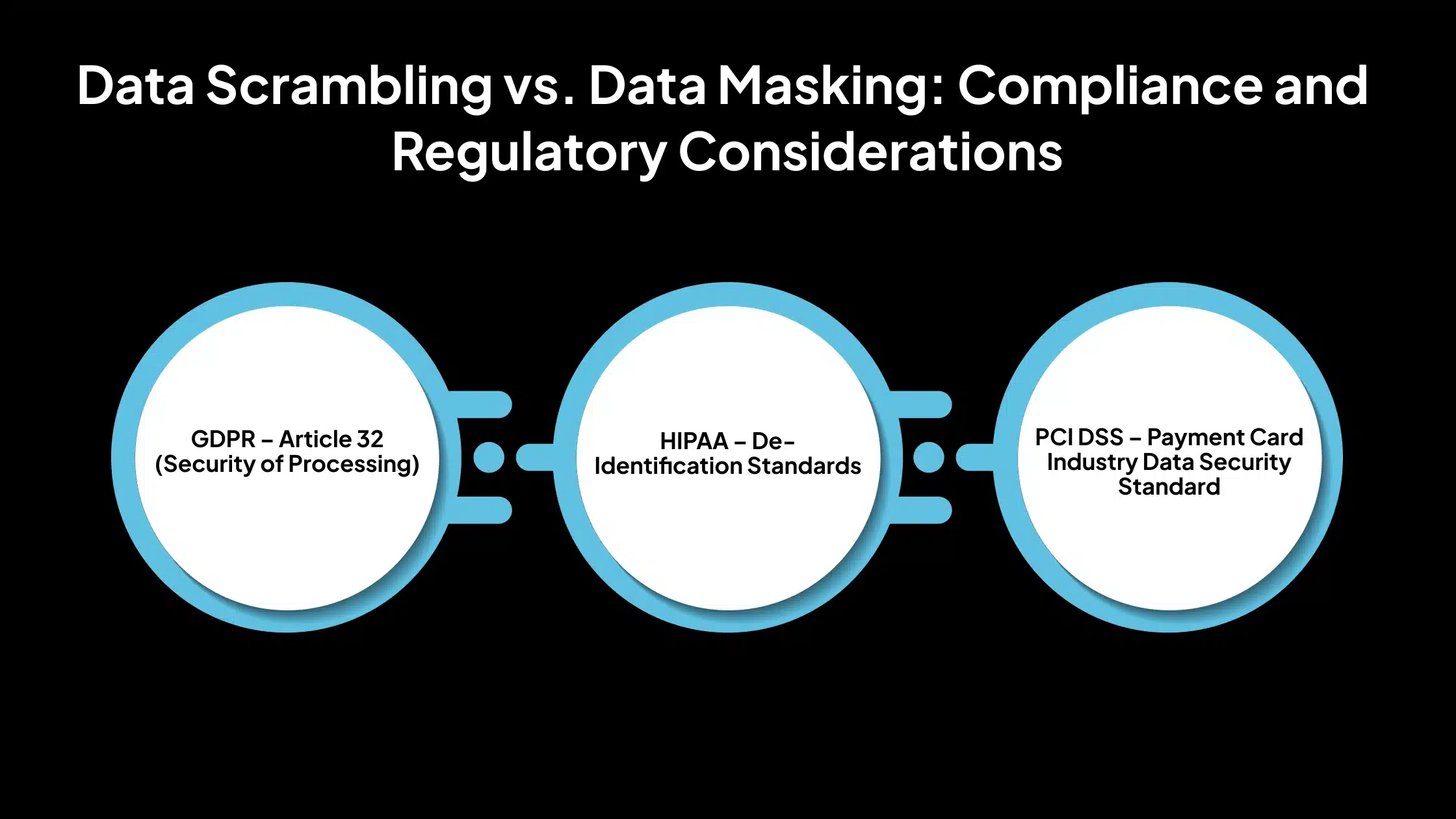
La protección de datos confidenciales es una práctica recomendada de seguridad y un requisito legal en muchas industrias. Regulaciones como GDPR, HIPAA y PCI DSS exigen controles específicos sobre cómo se almacena, procesa y comparte la información personal y confidencial. En este contexto, el enmascaramiento de datos es a menudo el método preferido para cumplir con estos requisitos, mientras que la aleatorización de datos se queda corta. Aquí está el por qué el enmascaramiento de datos es favorecido para el cumplimiento:
1. GDPR – artículo 32 (seguridad del procesamiento)
Artículo 32 del Reglamento General de Protección de Datos (GDPR) exige que las organizaciones implementen medidas técnicas y organizativas apropiadas para proteger los datos personales. Una de esas medidas recomendadas es la seudonimización, que implica reemplazar los datos identificables con valores sustitutos que no revelen directamente la identidad del individuo.
Las técnicas de enmascaramiento de datos GDPR se alinean bien con este requisito al:
- Reemplazar datos reales con valores realistas pero ficticios.
- Permitir a las organizaciones procesar y analizar datos sin exponer identidades reales.
- Apoyar la reversibilidad controlada cuando sea necesario, como a través de la tokenización segura.
Estas técnicas ayudan a mantener la usabilidad de los datos al tiempo que reducen los riesgos de privacidad. En contraste, la aleatorización de datos carece de control, auditabilidad y reversibilidad, lo que la hace inadecuada para cumplir con los requisitos de GDPR. No ofrece ninguna garantía de que la transformación se realizó de acuerdo con los estándares de cumplimiento o de que las relaciones de datos se conservaron.
2. HIPAA – Estándares de desidentificación
La Ley de Portabilidad y Responsabilidad del Seguro de Salud (HIPAA) en los EE. UU. define reglas estrictas para proteger la Información de Salud Protegida (PHI). La PHI debe ser desidentificada utilizando reglas específicas o protegida a través de un manejo seguro. El enmascaramiento de datos apoya el cumplimiento de HIPAA al:
- Eliminar identificadores directos (por ejemplo, nombres, números de Seguro Social).
- Mantener conjuntos de datos realistas para análisis o pruebas de atención médica.
- Permitir métodos de desidentificación determinados por expertos cuando sea necesario.
Los datos aleatorizados carecen de métodos controlados para garantizar que los identificadores se eliminen o reemplacen por completo según los estándares definidos.
3. PCI DSS – Estándar de seguridad de datos de la industria de tarjetas de pago
PCI DSS se aplica a cualquier organización que maneje información de tarjetas de crédito. Exige la protección de los datos del titular de la tarjeta a través de técnicas como el enmascaramiento o el truncamiento.
El enmascaramiento de datos se alinea con estas reglas al:
- Ocultar o reemplazar porciones confidenciales del número de tarjeta.
- Asegurar que los datos enmascarados no se puedan utilizar para el fraude.
- Mantener el formato de datos para pruebas o interfaces de usuario.
Los datos codificados no pueden garantizar que las partes correctas de los datos de la tarjeta estén protegidas y, a menudo, no cumplen con los requisitos de formato y visibilidad de PCI DSS.
Riesgos de usar datos codificados en escenarios de cumplimiento
La codificación no rastrea ni registra cómo se alteran los datos. Dado que el proceso es aleatorio y no reversible, no hay forma de demostrar cómo se transformaron los datos. Esta falta de documentación y control hace que no sea adecuado para auditorías o revisiones regulatorias.
Los datos codificados pueden verse diferentes, pero no siguen las reglas estándar de desidentificación. Algunos elementos de datos confidenciales pueden permanecer parcialmente expuestos o identificables sin métodos estructurados para eliminar o enmascarar los identificadores, lo que crea posibles brechas de cumplimiento y aumenta el riesgo de fugas de datos.
El manejo de datos debe ser deliberado, rastreable y estar alineado con los estándares legales en entornos regulados. El enmascaramiento de datos proporciona protección estructurada, reversibilidad controlada (si es necesario) y es compatible con marcos de cumplimiento específicos de la industria. La codificación de datos, aunque simple, no ofrece el control, la auditabilidad o la garantía necesarios para el manejo de datos confidenciales o regulados.
Codificación de datos frente a enmascaramiento de datos: elegir la técnica adecuada para su negocio
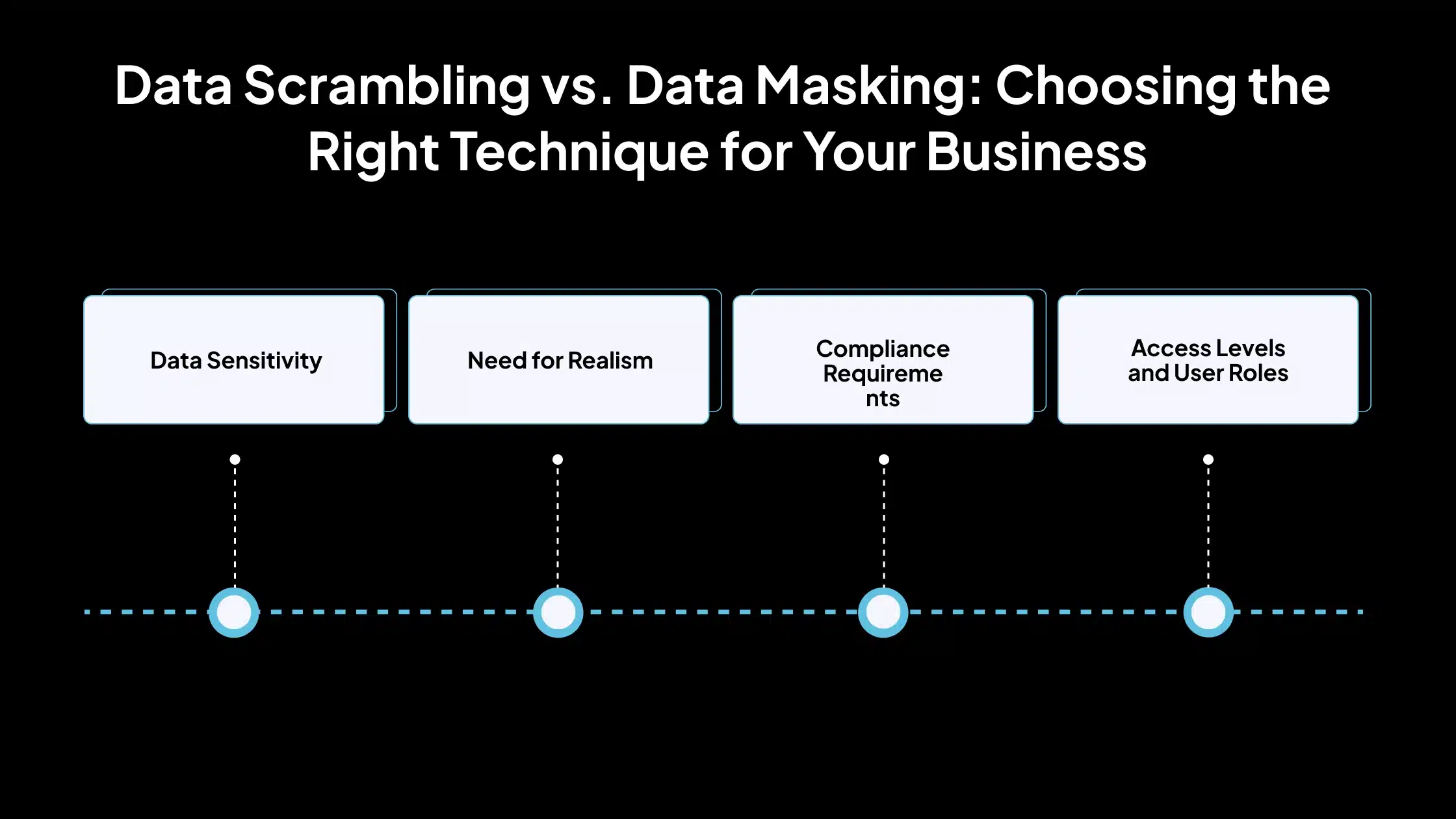
La selección entre la codificación de datos y el enmascaramiento de datos depende de sus objetivos comerciales, la naturaleza de los datos y los riesgos involucrados. Cada método tiene diferentes propósitos y se adapta a diversos entornos. A continuación, se muestran los factores a considerar al decidir qué técnica utilizar.
1. Sensibilidad de los datos
Se prefiere el enmascaramiento si el conjunto de datos contiene información de identificación personal (PII), registros de salud, detalles de pago o datos regulados debido a su protección estructurada y compatibilidad con el cumplimiento.
La codificación puede ser suficiente si el conjunto de datos no es confidencial o requiere la preservación del formato (no el realismo del contenido).
2. Necesidad de realismo
Elija el enmascaramiento de datos si los datos deben parecer realistas para las pruebas, la capacitación, la validación de la interfaz de usuario o el análisis.
Elija la codificación si el realismo no es necesario y solo se requiere la compatibilidad estructural (por ejemplo, el mismo tipo y longitud de datos).
3. Requisitos de cumplimiento
Utilice el enmascaramiento de datos si su organización debe cumplir con GDPR, HIPAA, PCI DSS o estándares similares. Admite la desidentificación, la seudonimización y los controles de acceso seguros.
La codificación no es adecuada para entornos relacionados con el cumplimiento, ya que carece de trazabilidad e implementación basada en estándares.
4. Niveles de acceso y roles de usuario
Si los datos serán accedidos por proveedores externos, desarrolladores externos, analistas o evaluadores, utilice el enmascaramiento de datos para garantizar la seguridad sin exponer los valores reales.
La codificación puede ser aceptable si el acceso está limitado a los equipos de desarrollo internos y los datos son solo para pruebas preliminares.
Herramientas para el enmascaramiento y la codificación de datos: potenciando la transformación segura de los datos
Las empresas a menudo confían en herramientas y plataformas dedicadas para implementar la protección de datos de manera efectiva, lo que proporciona automatización, controles de políticas e integración con los sistemas existentes. A continuación, se muestran las herramientas de uso común para el enmascaramiento y la codificación de datos:
Herramientas de enmascaramiento de datos
Estas herramientas están diseñadas para respaldar el cumplimiento, preservar las relaciones de datos y ofrecer reglas de enmascaramiento que se pueden aplicar a escala.
- Enmascaramiento dinámico de datos de Informatica: Admite el enmascaramiento estático y dinámico. Ofrece reglas de enmascaramiento preconstruidas para datos PII, financieros y de atención médica. Es adecuado para grandes empresas con necesidades regulatorias.
- Delphix: Proporciona enmascaramiento de datos en tiempo real y sobre la marcha, y mantiene la integridad referencial en todos los sistemas. Se utiliza comúnmente para DevOps y entornos de integración continua.
- Enmascaramiento y subconjuntos de datos de Oracle: Esta herramienta ofrece enmascaramiento nativo de bases de datos para entornos Oracle. Incluye plantillas integradas para enmascarar diferentes tipos de datos y admite la creación de subconjuntos de datos para conjuntos de datos enmascarados más pequeños.
- IBM Optim: Se especializa en el enmascaramiento y archivo de datos a escala empresarial. Está diseñado para datos estructurados y no estructurados. Es un acceso integrado basado en roles e informes de cumplimiento.
Herramientas de codificación de datos
La codificación de datos generalmente se implementa a través de soluciones más simples, a menudo utilizando herramientas internas o funciones nativas en los sistemas de bases de datos.
- Scripts personalizados: Los desarrolladores a menudo usan scripts de Python, SQL o shell para mezclar o aleatorizar los valores de los datos. Estos scripts son fáciles de implementar, pero tienen un control y un cumplimiento limitados.
- Opciones nativas de la base de datos: las bases de datos SQL Server y Oracle ofrecen funciones básicas (por ejemplo, NEWID(), DBMS_RANDOM) para codificar cadenas, números o filas. Esto los hace adecuados para la ofuscación rápida de datos en entornos de prueba sin requisitos de cumplimiento.
Para las industrias reguladas, priorice las plataformas como Informatica, Delphix o IBM Optim que ofrecen control completo, informes y soporte de cumplimiento. Para entornos internos de bajo riesgo, los scripts personalizados o las funciones nativas de la base de datos pueden ser suficientes para fines de codificación.
¿Por qué elegir Avahi Data Masker?: enmascaramiento de datos optimizado, escalable y seguro
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi ofrece herramientas que ayudan a las organizaciones a gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es el Data Masker, diseñado para proteger los datos financieros y de identificación personal al tiempo que apoya la eficiencia operativa.
Avahi Data Masker está diseñado para organizaciones que deben manejar información confidencial de forma segura sin comprometer la eficiencia operativa. Ofrece un enfoque estructurado y basado en IA para el enmascaramiento de datos, lo que garantiza que los campos confidenciales, como los identificadores personales, los registros financieros y los datos de salud, estén protegidos y sigan siendo utilizables para procesos internos como análisis, desarrollo y pruebas. Estas son las razones para elegir Avahi Data Masker:
- Compatibilidad entre sectores con el cumplimiento normativo: Permite la gestión segura de datos en los sectores de la sanidad (HIPAA), las finanzas (PCI DSS), el comercio minorista y otros sectores regulados.
- Control de acceso basado en roles: Restringe la visibilidad de los datos a los usuarios autorizados, lo que garantiza que los datos confidenciales estén protegidos durante el acceso de varios equipos o proveedores.
- Lógica de enmascaramiento impulsada por la IA: Utiliza algoritmos inteligentes para identificar y enmascarar los campos confidenciales sin alterar la estructura ni la usabilidad de los datos.
- Flujo de trabajo sencillo y guiado: Una interfaz fácil de usar agiliza el proceso desde la carga de archivos hasta la salida segura.
- Usabilidad de los datos después del enmascaramiento: Los datos enmascarados conservan su formato, lo que permite realizar tareas posteriores como la elaboración de informes, la detección de fraudes o los entornos de prueba.
Esta funcionalidad garantiza la seguridad de los datos, la alineación regulatoria y la continuidad operativa en una sola solución.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, entendemos la importancia crítica de salvaguardar la información confidencial al tiempo que garantizamos flujos de trabajo operativos sin problemas.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programar una llamada de demostración
Preguntas frecuentes
1. ¿Cuál es la diferencia entre la codificación de datos y el enmascaramiento de datos?
La codificación de datos altera aleatoriamente los valores mientras mantiene la estructura de los datos, lo que los hace inutilizables pero técnicamente válidos. Por otro lado, el enmascaramiento de datos reemplaza los datos confidenciales con valores realistas y ficticios que siguen siendo útiles para las pruebas, el análisis o la capacitación. Si bien la codificación es irreversible y no cumple con las regulaciones, el enmascaramiento a veces admite el cumplimiento, el realismo e incluso la reversibilidad.
2. ¿La codificación de datos cumple con las regulaciones como GDPR o HIPAA?
La codificación de datos generalmente no cumple con las regulaciones de privacidad como GDPR, HIPAA o PCI DSS. Carece de auditabilidad, trazabilidad y control estructurado. Por el contrario, el enmascaramiento de datos admite la desidentificación y la seudonimización, lo que lo convierte en la opción preferida para las organizaciones que operan en industrias reguladas.
3. ¿Cuándo debe una empresa utilizar el enmascaramiento de datos en lugar de la codificación de datos?
Una empresa debe utilizar el enmascaramiento de datos cuando los datos deben verse y comportarse como datos reales, especialmente en pruebas, análisis, capacitación de usuarios o intercambio de datos con terceros. Es ideal para situaciones que requieren cumplimiento, realismo de los datos y acceso controlado, mientras que la codificación de datos solo debe usarse para pruebas internas donde la estructura importa más que el contenido.
4. ¿Se pueden utilizar la codificación y el enmascaramiento de datos en una estrategia de protección de datos?
Algunas organizaciones combinan la codificación y el enmascaramiento de datos en función del entorno y la sensibilidad de los datos. La codificación podría usarse para el desarrollo en las primeras etapas, mientras que el enmascaramiento se aplica donde se requiere realismo, cumplimiento y acceso controlado, como las pruebas de aceptación del usuario o la colaboración con terceros.
5. ¿El enmascaramiento de datos es reversible?
El enmascaramiento de datos puede ser reversible o irreversible, según el método. Por ejemplo, la tokenización permite la reversibilidad segura mediante el uso de una bóveda de tokens, mientras que la sustitución o la mezcla a menudo son irreversibles. Esta flexibilidad permitirá a las empresas elegir en función del acceso a los datos y las necesidades de auditoría.



