
TL;DR
|
En 2023, HCA Healthcare, un importante sistema hospitalario de EE. UU., sufrió una filtración de datos que expuso la información personal de más de 11 millones de pacientes. Los datos filtrados incluían detalles de citas, información de contacto y registros de servicios al paciente.
Unos años antes, Anthem Inc. se enfrentó a una de las mayores filtraciones de la historia del sector sanitario. Casi 80 millones de registros, incluidos nombres, identificaciones médicas e información laboral, se vieron comprometidos.
Las organizaciones sanitarias son objetivos atractivos para los ciberataques debido a la gran cantidad de datos confidenciales que manejan. Los historiales médicos electrónicos (HME), la información de facturación, los detalles de los seguros y los identificadores personales constituyen conjuntos de datos de gran valor que, si se exponen, pueden dar lugar a robo de identidad, fraude de seguros y sanciones reglamentarias.
El creciente uso de la IA en la atención sanitaria ha traído nuevas oportunidades para diagnósticos más inteligentes, análisis predictivos y eficiencia operativa. Al mismo tiempo, ha aumentado lo que está en juego para la seguridad de los datos.
Los sistemas de IA dependen de grandes volúmenes de datos de pacientes para funcionar eficazmente, pero estos datos deben protegerse en cada etapa. A medida que la información fluye entre departamentos, sistemas en la nube y herramientas de terceros, el riesgo de exposición aumenta.
El enmascaramiento de datos es una solución compatible con la IA para el sector sanitario que protege la información confidencial sin interrumpir la usabilidad. Al sustituir los datos precisos por valores realistas pero no identificables, el enmascaramiento de datos garantiza que los historiales de los pacientes sigan siendo privados, incluso si acceden a ellos usuarios no autorizados.
Este blog explora el enmascaramiento de datos, qué es, cómo funciona y por qué es una defensa crucial contra la creciente amenaza de una filtración de datos en la atención sanitaria.
El impacto de la filtración de datos en la atención sanitaria
Los datos sanitarios son extremadamente valiosos en la dark web. A diferencia de los números de tarjetas de crédito, que pueden cancelarse rápidamente, la información personal de salud (PHI) incluye datos permanentes, nombres completos, fechas de nacimiento, números de la Seguridad Social, detalles del seguro e historiales médicos. Esta información a menudo se vende a un precio más alto porque puede utilizarse para el robo de identidad, el fraude de seguros y el chantaje. A continuación, se muestran las consecuencias a las que se enfrentan las organizaciones sanitarias tras una filtración de datos.
Presión reguladora
Las organizaciones de atención médica se enfrentan a estrictos requisitos de cumplimiento según las regulaciones de la HIPAA (Ley de Portabilidad y Responsabilidad del Seguro de Salud) en los EE. UU. y el RGPD (Reglamento General de Protección de Datos) en la UE. Estas leyes exigen el manejo seguro de los datos personales, la notificación inmediata de las infracciones y la prueba de salvaguardias adecuadas. El incumplimiento puede resultar en fuertes multas y desafíos legales.
Erosión de la confianza del paciente
Una filtración de datos puede provocar una pérdida inmediata de la confianza del paciente. Los pacientes esperan que sus historiales médicos sean privados. Cuando los datos se exponen, se daña la reputación del proveedor de atención sanitaria y los pacientes dudan en compartir información confidencial en el futuro.
Sanciones económicas
Los organismos reguladores imponen multas sustanciales a las organizaciones de atención médica por fallos de seguridad, en particular por violaciones de la Ley de Portabilidad y Responsabilidad del Seguro de Salud (HIPAA). La estructura de sanciones se divide en niveles según el grado de culpabilidad:

Consecuencias legales
Las organizaciones pueden enfrentarse a demandas de los pacientes afectados, especialmente si se demuestra que no se han establecido las salvaguardias adecuadas. Las demandas colectivas son comunes, y las batallas legales pueden durar años, lo que aumenta el coste financiero y de reputación. Por ejemplo, Anthem Inc. llegó a un acuerdo por 115 millones de dólares tras una filtración que expuso casi 80 millones de registros.
Tiempo de inactividad operativa
La respuesta a una filtración a menudo implica el cierre de sistemas, la realización de investigaciones forenses y la restauración de copias de seguridad de datos. Esto puede interrumpir la atención al paciente, retrasar los tratamientos y sobrecargar los recursos del personal.
Cuanto más largo sea el tiempo de inactividad, mayor será el riesgo para los resultados de los pacientes y la continuidad del negocio. Los ataques de ransomware han provocado una media de casi 19 días de tiempo de inactividad para las organizaciones sanitarias de EE. UU., lo que subraya las graves interrupciones operativas causadas por tales incidentes.
Enmascaramiento de datos: propósito, proceso y tipos

El enmascaramiento de datos ayuda a reducir el riesgo de una filtración de datos en la atención sanitaria al sustituir la información real del paciente por datos realistas pero ficticios, lo que garantiza que los detalles confidenciales permanezcan protegidos incluso si se produce un acceso no autorizado.
La idea principal es mantener el formato y la usabilidad de los datos para que las operaciones comerciales y el rendimiento del sistema no se vean afectados. Por ejemplo, el nombre de un paciente puede ser sustituido por un nombre falso, pero sigue pareciendo un nombre y encaja en el mismo sistema.
Aquí hay una explicación detallada de cada uno de los tipos de enmascaramiento de datos:
Enmascaramiento de datos estático
El enmascaramiento de datos estático se realiza en una copia de una base de datos. Los datos originales se enmascaran una vez y se guardan en un nuevo entorno. Este método se utiliza comúnmente para entornos que no son de producción, como el desarrollo o las pruebas, donde el acceso a datos precisos no es necesario.
Una vez enmascarados, los datos no cambian. Por ejemplo, enmascarar datos en un entorno de prueba antes de compartirlos con desarrolladores externos.
Enmascaramiento de datos dinámicos
El enmascaramiento de datos dinámico oculta los datos confidenciales en tiempo real sin alterar los datos en reposo. Los datos originales permanecen sin cambios en la base de datos, pero los usuarios ven solo la versión enmascarada en función de su nivel de acceso.
A menudo se utiliza en entornos en vivo donde ciertos usuarios deben ver datos limitados. Por ejemplo, un agente de centro de llamadas puede acceder a información parcial del paciente mientras protege el registro completo.
Enmascaramiento determinista
El enmascaramiento determinista garantiza que la misma entrada siempre produzca la misma salida enmascarada. Por ejemplo, “Daniel S” siempre se enmascarará como “Ray Smith”. Esta consistencia es útil cuando es necesario unir o comparar varias bases de datos. Esto ayuda a mantener las relaciones entre los registros enmascarados en diferentes sistemas.
Enmascaramiento no determinista
El enmascaramiento no determinista produce resultados diferentes cada vez que se enmascara la misma entrada. Esto es más seguro, pero puede afectar a la usabilidad si se necesitan resultados consistentes. Este método ayuda a enmascarar los datos para entornos donde las relaciones entre los conjuntos de datos no son importantes.
Enmascaramiento que conserva el formato
El enmascaramiento que conserva el formato mantiene la estructura y el formato originales de los datos. Por ejemplo, un número de la Seguridad Social enmascarado seguirá el formato de 9 dígitos, y un número de teléfono seguirá pareciendo válido.
Garantizar que los datos enmascarados funcionen con sistemas que requieren datos en formatos específicos, como el software EHR o los scripts de validación.
Desafíos en la implementación del enmascaramiento de datos
Si bien reemplazar la información confidencial con valores desidentificados suena simple, implementarlo trae desafíos reales. Estos son algunos de los desafíos que enfrentan las organizaciones sanitarias al implementarlo:
- Preservar la usabilidad de los datos
Los datos enmascarados aún deben funcionar. Eso significa que los números de teléfono deben parecerse a los números, y los ID médicos deben pasar las comprobaciones del sistema. Si el formato cambia, los sistemas pueden rechazar los datos, interrumpir los procesos automatizados o etiquetar incorrectamente los registros. Por ejemplo, si un ID de paciente enmascarado no coincide con los patrones esperados, los sistemas EHR podrían marcarlo como no válido, deteniendo los flujos de trabajo posteriores.
- Mantener la consistencia
Las organizaciones sanitarias a menudo utilizan varias bases de datos en todos los departamentos: clínico, facturación, investigación y soporte. Si el mismo registro de paciente se enmascara de manera diferente en cada sistema, las herramientas internas no pueden vincular los datos de manera confiable. Esto interrumpe las pruebas, los informes y la interoperabilidad. El enmascaramiento consistente es clave, pero difícil cuando los sistemas no están conectados o estandarizados.
- Garantizar la precisión semántica
El enmascaramiento no se trata solo de ocultar datos; debe mantener el significado. Si se cambia una fecha de nacimiento, los indicadores basados en la edad (por ejemplo, pediátrico o geriátrico) deben reflejar ese cambio. De lo contrario, la lógica integrada en los sistemas de análisis, pruebas o toma de decisiones podría fallar o generar resultados engañosos.
- Enmascaramiento de datos sensible al género
Los nombres a menudo revelan el género, lo que importa en la investigación sanitaria, el análisis de tratamientos y los informes de cumplimiento. Si los nombres se intercambian aleatoriamente durante el enmascaramiento sin preservar el género, puede distorsionar los modelos de datos. Por ejemplo, un equipo de investigación que analiza los resultados del tratamiento basados en el género podría sacar conclusiones incorrectas.
- Alinear la seguridad y la funcionalidad
Si la máscara es demasiado agresiva, los datos pierden sentido. Enmascarar demasiado a la ligera, y es un riesgo para la privacidad. El desafío es encontrar el término medio entre proteger los datos del paciente y preservar suficientes detalles para análisis, simulaciones y pruebas útiles.
- Adaptación a los sistemas heredados
Es posible que los sistemas más antiguos no admitan herramientas o integraciones de enmascaramiento modernas. Los proveedores de atención sanitaria a menudo confían en software heredado con estructuras de datos rígidas y flexibilidad limitada. La introducción del enmascaramiento en estos entornos requiere soluciones personalizadas, lo que generalmente aumenta el tiempo y el coste de implementación.
- Rendimiento a escala
Aplicar el enmascaramiento a conjuntos de datos grandes y en constante crecimiento puede ralentizar las operaciones, especialmente en los sistemas en tiempo real. Los hospitales que procesan altos volúmenes de pacientes no pueden permitirse retrasos en el acceso o la actualización de los registros. Si no está bien optimizado, el enmascaramiento dinámico puede introducir latencia en las aplicaciones orientadas al usuario.
Aplicaciones del mundo real del enmascaramiento de datos en la atención sanitaria
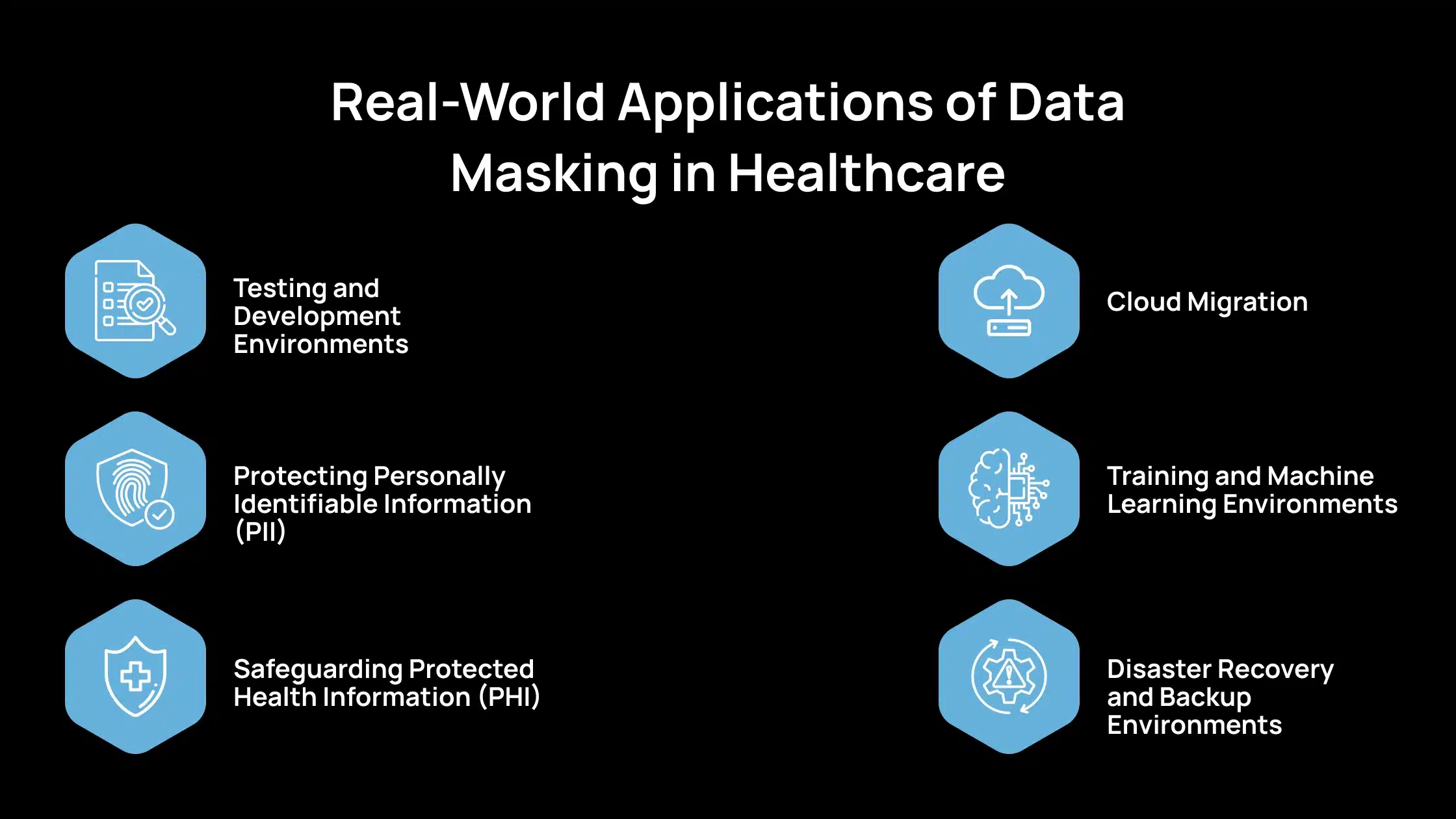
Las organizaciones sanitarias utilizan el enmascaramiento de datos en sus flujos de trabajo para reducir activamente el riesgo de una filtración de datos en la atención sanitaria mientras mantienen las operaciones eficientes. Así es como se utiliza el enmascaramiento de datos en los flujos de trabajo de la atención sanitaria.
1. Entornos de prueba y desarrollo
Cuando los desarrolladores y los probadores necesitan acceder a las bases de datos de pacientes para las actualizaciones del sistema o el desarrollo de aplicaciones, la exposición de datos precisos crea riesgos de privacidad significativos. El enmascaramiento de datos permite a las organizaciones crear versiones realistas pero anónimas de los registros de pacientes. Estos conjuntos de datos enmascarados mantienen la estructura y la lógica de los datos originales, lo que permite realizar pruebas precisas sin revelar información personal.
2. Protección de la información de identificación personal (PII)
Los sistemas sanitarios almacenan PII, como nombres, direcciones, datos de contacto y números de la Seguridad Social. Enmascarar estos elementos antes de usarlos en entornos no seguros reduce el riesgo de exposición de datos, especialmente cuando varios equipos acceden a los mismos sistemas.
3. Protección de la información sanitaria protegida (PHI)
Las regulaciones como HIPAA requieren que las organizaciones se aseguren de que los datos de salud del paciente estén debidamente protegidos. El enmascaramiento de datos permite a los proveedores de atención sanitaria compartir PHI para investigación, informes o análisis mientras protegen las identidades de los pacientes. También apoya el cumplimiento durante las auditorías y las colaboraciones externas.
4. Migración a la nube
A medida que más organizaciones sanitarias se trasladan a plataformas en la nube para el almacenamiento y el análisis, el enmascaramiento se vuelve esencial. La transferencia de datos a entornos de terceros aumenta el riesgo de filtraciones. Los proveedores de atención sanitaria pueden reducir la exposición sin interrumpir los plazos de migración enmascarando los datos confidenciales antes de la migración.
5. Entornos de formación y aprendizaje automático
Los datos se utilizan cada vez más para entrenar modelos de aprendizaje automático en la atención sanitaria para herramientas de diagnóstico, análisis predictivos y más. Los datos enmascarados que reflejan los datos reales de los pacientes garantizan que el modelo aprenda de manera efectiva sin comprometer la privacidad ni infringir las normas de cumplimiento.
6. Entornos de recuperación ante desastres y copia de seguridad
Las copias de seguridad y los conjuntos de datos de recuperación ante desastres a menudo contienen copias completas de la información del paciente. Si estos entornos no son tan seguros como la producción, se convierten en objetivos blandos para las filtraciones. El enmascaramiento garantiza que estos registros no contengan identificadores reales, lo que reduce el impacto de cualquier fuga potencial.
Beneficios del enmascaramiento de datos para las organizaciones sanitarias
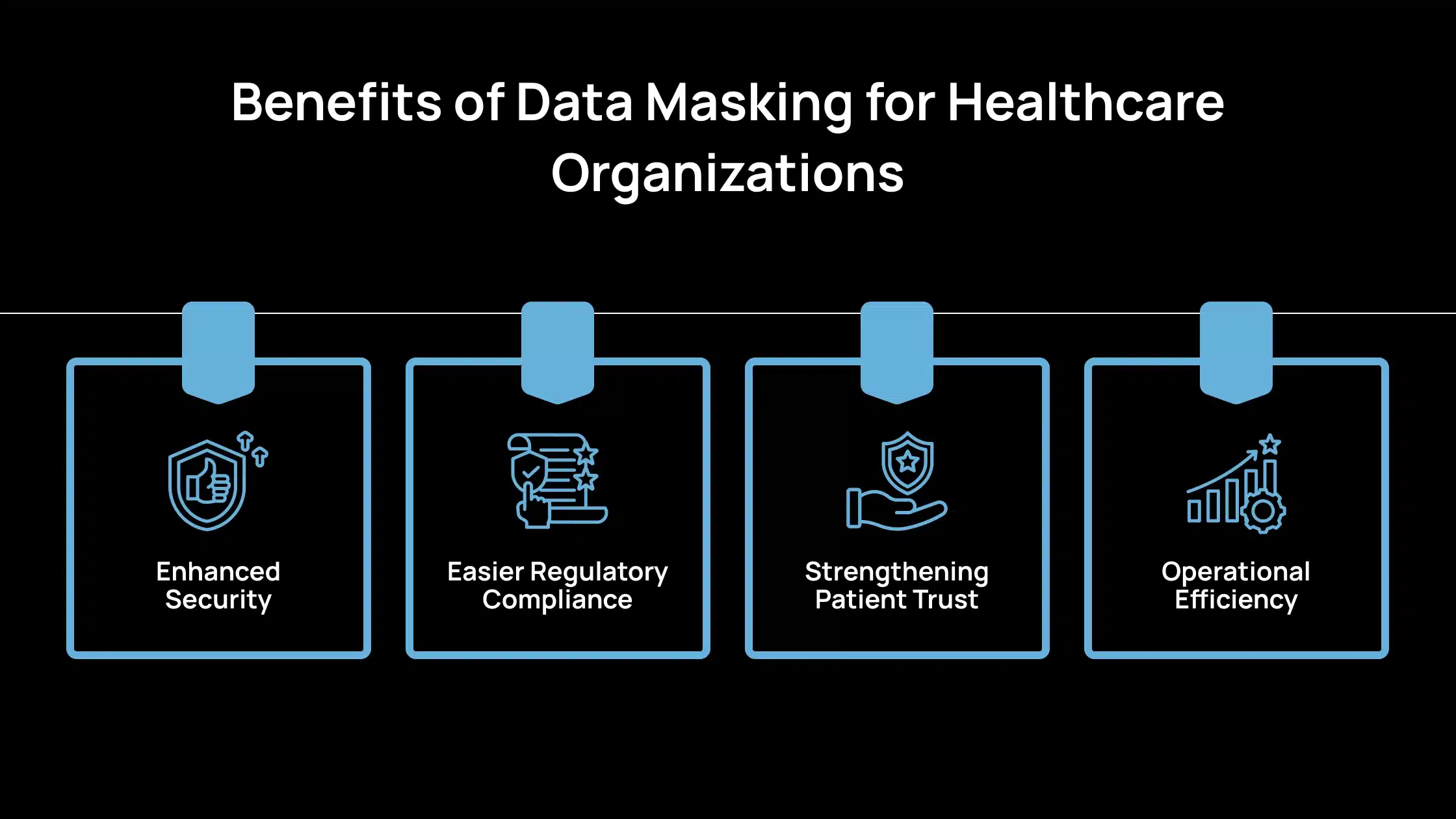
El enmascaramiento de datos permite a los proveedores de atención sanitaria proteger la información confidencial sin ralentizar las operaciones. Aquí hay una lista de algunos beneficios de por qué el enmascaramiento de datos es esencial para las organizaciones:
1. Seguridad mejorada
Los datos enmascarados se pueden utilizar para el desarrollo, las pruebas, el análisis y la formación sin arriesgarse a la exposición a información precisa del paciente. Esto garantiza que los equipos puedan trabajar con conjuntos de datos realistas mientras mantienen segura la información sanitaria protegida (PHI).
El sector sanitario vio el coste medio más alto por filtración en 10,93 millones de dólares. El enmascaramiento de datos puede reducir significativamente este riesgo al garantizar que los datos expuestos no se puedan rastrear hasta personas reales.
2. Cumplimiento normativo más fácil
El enmascaramiento de datos ayuda a las organizaciones sanitarias a cumplir con los estrictos requisitos normativos como HIPAA, GDPR y CCPA. Los datos enmascarados a menudo se consideran desidentificados, lo que reduce la carga regulatoria cuando se utilizan en entornos de no producción o investigación.
3. Fortalecimiento de la confianza del paciente
Cuando los pacientes saben que sus datos se manejan de forma segura, incluso más allá del uso clínico, refuerzan la confianza en el proveedor. El enmascaramiento de datos evita el uso indebido o la exposición accidental, especialmente en los sistemas sanitarios grandes y distribuidos donde varios equipos acceden a los datos.
Una encuesta de Accenture encontró que 1 de cada 4 pacientes cambiaría de proveedor si sus datos se vieran comprometidos. Las medidas sólidas de protección de datos como el enmascaramiento pueden ayudar a mantener la lealtad del paciente.
4. Eficiencia operativa
El enmascaramiento de datos permite el uso seguro de datos en diferentes flujos de trabajo, como el desarrollo de aplicaciones, la formación, el análisis y la migración a la nube. Reduce la necesidad de barreras de seguridad complejas en entornos que no requieren acceso a datos precisos.
Las organizaciones sanitarias se enfrentan a amenazas crecientes a los datos de los pacientes todos los días. Al utilizar el enmascaramiento de datos, pueden proteger la información confidencial sin ralentizar su trabajo. El enmascaramiento reemplaza los datos reales con valores falsos pero realistas, por lo que incluso si alguien obtiene acceso no autorizado, no verá nada útil. Esto ayuda a cumplir con las normas de privacidad y mantiene la confianza del paciente. Dado que una filtración de datos en la atención sanitaria puede provocar pérdidas significativas y problemas legales, el uso del enmascaramiento de datos es un paso innovador y necesario.
Enfrentar los riesgos de datos en la atención sanitaria: ¿por qué Avahi AI es la plataforma adecuada para la seguridad de datos?
Las organizaciones sanitarias se ocupan de grandes volúmenes de datos confidenciales, registros de pacientes, detalles de seguros, diagnósticos, etc. Asegurar estos datos mientras se mantienen utilizables para la prestación de atención, la investigación y las operaciones es un desafío importante.
Avahi AI es una plataforma especialmente diseñada que ayuda a los proveedores de atención sanitaria a administrar, proteger y trabajar con los datos de manera más eficiente. Ofrece una potente función de enmascaramiento de datos que está diseñada para hacer que la seguridad de los datos sea simple, rápida y efectiva. Aquí está el por qué es una opción inteligente:
1. Interfaz fácil de usar
La plataforma cuenta con un diseño sencillo e intuitivo que no requiere conocimientos técnicos. Los usuarios pueden cargar archivos en formatos .txt, .doc o .pdf y procesarlos rápidamente. La configuración es simple, lo que permite a los equipos comenzar sin formación o soporte adicionales.
2. Enmascaramiento rápido y preciso

Los datos confidenciales se enmascaran y se reemplazan rápidamente con valores realistas. La herramienta conserva la estructura y el formato originales de los datos, lo cual es esencial para las pruebas, la formación o el análisis. También mantiene la coherencia semántica, preservando los rangos de edad y los datos de género correctos, lo que hace que el resultado sea significativo.
3. Resumen y vista en paralelo
Avahi AI genera automáticamente resúmenes del contenido enmascarado para una comprensión rápida. También permite a los usuarios ver las versiones originales y enmascaradas una al lado de la otra, lo que facilita la verificación de los resultados y la realización de auditorías. Esta función simplifica la validación y reduce el tiempo de revisión manual.
4. Diseñado para casos de uso sanitario
El enmascarador de datos de Avahi AI está diseñado para manejar información sanitaria protegida (PHI) e información de identificación personal (PII). Admite estándares de cumplimiento clave como HIPAA, GDPR y otras leyes de privacidad de datos. La herramienta garantiza que los datos enmascarados sigan siendo totalmente utilizables en los historiales clínicos electrónicos (EHR) y las plataformas de análisis médico.
5. Admite flujos de trabajo seguros
El enmascarador de datos es ideal para entornos que no son de producción, como el desarrollo, el control de calidad, la investigación y la formación. Garantiza que los datos confidenciales nunca se expongan, incluso cuando se comparten con equipos externos. Esto ayuda a reducir los riesgos durante la migración a la nube o cuando se trabaja con proveedores externos.
6. Ahorra tiempo y recursos
La herramienta reduce el tiempo que los equipos de TI dedican a los procesos manuales al automatizar la desinfección de datos. No es necesario crear scripts personalizados, lo que ahorra esfuerzo y recursos. Esto permite a los equipos centrarse más en la innovación y menos en los desafíos de cumplimiento.
Al elegir Avahi AI, las organizaciones sanitarias obtienen una plataforma fiable que mejora la seguridad, mejora la usabilidad de los datos y ayuda a cumplir con los estándares regulatorios, todo ello ahorrando tiempo.
Descubra la plataforma de IA de Avahi en acción

En Avahi, capacitamos a las empresas para implementar IA generativa avanzada que agiliza las operaciones, mejora la toma de decisiones y acelera la innovación, todo ello con cero complejidad.
Como su socio de consultoría de AWS Cloud de confianza, capacitamos a las organizaciones para aprovechar todo el potencial de la IA, garantizando al mismo tiempo la seguridad, la escalabilidad y el cumplimiento con las soluciones en la nube líderes del sector.
Nuestras soluciones de IA incluyen
- Adopción e integración de la IA: utilice Amazon Bedrock y GenAI para mejorar la automatización y la toma de decisiones.
- Desarrollo de IA personalizado: cree aplicaciones inteligentes adaptadas a las necesidades de su negocio.
- Optimización de modelos de IA: cambie sin problemas entre modelos de IA con comparaciones automatizadas de costes, precisión y rendimiento.
- Automatización de la IA: automatice las tareas repetitivas y libere tiempo para el crecimiento estratégico.
- Seguridad avanzada y gobernanza de la IA: garantice el cumplimiento, la detección de fraudes y la implementación segura de modelos.
¿Quiere liberar el poder de la IA con seguridad y eficiencia de nivel empresarial?
¡Empiece con la plataforma de IA de Avahi!
Programar una llamada de demostración
Preguntas frecuentes
- ¿Qué es el enmascaramiento de datos y cómo protege la información del paciente?
El enmascaramiento de datos reemplaza los datos reales de los pacientes con valores falsos pero realistas, preservando la usabilidad al tiempo que elimina los detalles identificables. Incluso si los usuarios no autorizados acceden a los datos enmascarados, no se pueden rastrear hasta los individuos, lo que lo hace ideal para entornos que no son de producción, como pruebas, formación y análisis.
- ¿Por qué es importante el enmascaramiento de datos en el cumplimiento normativo del sector sanitario?
El enmascaramiento de datos ayuda a los proveedores de atención médica a cumplir con regulaciones como HIPAA y GDPR al reducir la exposición a la información médica protegida (PHI). Dado que los datos enmascarados se consideran desidentificados, es más seguro usarlos en investigación o en sistemas de terceros, lo que reduce tanto el riesgo regulatorio como la fricción operativa.
- ¿Dónde se utiliza el enmascaramiento de datos en entornos sanitarios reales?
Los proveedores de atención médica utilizan el enmascaramiento de datos durante las pruebas de aplicaciones, el entrenamiento de modelos de aprendizaje automático y la migración a la nube. También se aplica para proteger las copias de seguridad, los entornos de desarrollo y los flujos de trabajo de informes, lo que garantiza que los datos confidenciales permanezcan seguros en todos los puntos de contacto.
- ¿Qué desafíos enfrentan las organizaciones sanitarias con el enmascaramiento de datos?
La implementación del enmascaramiento no siempre es fácil; debe preservar el formato de los datos, mantener la coherencia entre los sistemas y funcionar dentro del software heredado. Si no se hace correctamente, el enmascaramiento puede interrumpir los flujos de trabajo o distorsionar los análisis. Por eso, las herramientas específicas para el sector sanitario son esenciales.
- ¿Cómo ayuda Data Masker de Avahi AI a los proveedores de atención médica a mantenerse seguros?
Avahi AI ofrece un enmascaramiento rápido que preserva el formato, diseñado para casos de uso en el sector sanitario. Admite el cumplimiento normativo, mantiene la usabilidad de los datos y simplifica las auditorías con vistas en paralelo y resúmenes automatizados. Está diseñado para mantener la PHI protegida sin ralentizar las operaciones.



