
TL;DR
|
Los datos confidenciales suelen ser más vulnerables donde menos se espera: en sus entornos de desarrollo y prueba.
Si bien las organizaciones invierten mucho en proteger los sistemas de producción, las copias de datos reales a menudo fluyen libremente hacia bases de datos de prueba, herramientas de análisis y plataformas de terceros sin la protección adecuada. ¿El resultado? Exposición evitable.
Un informe de Gartner de 2023 reveló que más del 40% de las filtraciones de datos involucran entornos que no son de producción, donde se utilizan datos reales para operaciones como pruebas de software, entrenamiento de modelos de IA o informes. Además, el informe de IBM sobre el costo de una filtración de datos destaca que la filtración promedio ahora cuesta 4,9 millones de dólares, y las sanciones regulatorias y el daño a la reputación aumentan el impacto.
Para cerrar estas brechas, los equipos de seguridad deben ir más allá de las defensas perimetrales y adoptar técnicas y estrategias de enmascaramiento de datos que oculten la información confidencial y, al mismo tiempo, la mantengan utilizable para los flujos de trabajo internos.
El enmascaramiento de datos permite a las organizaciones ocultar la información confidencial y, al mismo tiempo, mantener su usabilidad en todos los sistemas. Ya se trate de registros de clientes, datos financieros o información de salud, el enmascaramiento garantiza que los datos sigan siendo funcionales para uso interno, sin riesgo de exposición.
Este blog explora siete técnicas probadas de enmascaramiento de datos que todo equipo de seguridad debe conocer. Explicamos cómo funciona cada método, dónde encaja mejor y cómo fortalece el marco de protección de datos de su organización. Ya sea que esté navegando por el RGPD, HIPAA o simplemente buscando cerrar las brechas de seguridad internas, estas técnicas ofrecen soluciones prácticas y escalables.
Comprensión del enmascaramiento de datos: cómo difiere del cifrado y la anonimización
El enmascaramiento de datos es un método de protección de datos que oculta la información confidencial reemplazándola con datos ficticios pero de apariencia realista. Esto garantiza que los datos subyacentes estén protegidos contra el acceso no autorizado, al tiempo que conservan su usabilidad para fines que no son de producción.
El objetivo principal es evitar la exposición de datos confidenciales, como información de identificación personal (PII), registros financieros o datos de salud, durante los procesos de desarrollo de software, prueba, análisis y capacitación.
Esta técnica ayuda a las organizaciones a mantener los flujos de trabajo operativos sin comprometer la seguridad de los datos. A diferencia de la eliminación o restricción, el enmascaramiento de datos permite que los datos sigan siendo funcionales y utilizables por los sistemas o el personal sin revelar valores absolutos.
Los desarrolladores y los equipos de control de calidad a menudo necesitan datos que se comporten como información real del usuario. Los datos enmascarados proporcionan una alternativa segura sin exponer los registros reales del usuario. Los analistas pueden trabajar con conjuntos de datos enmascarados para obtener información y tendencias sin acceder a información confidencial, lo que reduce los riesgos de cumplimiento.
Cuando los proveedores externos o los equipos offshore requieren acceso a las bases de datos, el enmascaramiento de datos garantiza que no se divulgue información confidencial. Las regulaciones como el RGPD, HIPAA y CCPA exigen estrictos controles de datos personales y de salud. El enmascaramiento ayuda a las organizaciones a cumplir con estas obligaciones legales al proteger la información del cliente de la exposición en entornos no seguros.
Cómo difiere el enmascaramiento de datos del cifrado y la anonimización
El cifrado transforma los datos utilizando algoritmos criptográficos en formatos ilegibles que solo se pueden decodificar con una clave específica. Si bien el cifrado es adecuado para el almacenamiento y la transmisión seguros, no permite el uso práctico de los datos en entornos que no son de producción sin descifrarlos.
Por el contrario, el enmascaramiento de datos reemplaza permanentemente los datos originales con una versión enmascarada, lo que los hace útiles para el desarrollo o la capacitación sin necesidad de acceder a los valores originales.
La anonimización elimina los elementos identificables de los datos, lo que hace imposible vincular la información a un individuo. Sin embargo, los datos anonimizados a menudo carecen de realismo y coherencia, especialmente en las pruebas o el análisis. Por otro lado, el enmascaramiento de datos mantiene el formato, la estructura y las interdependencias de los datos, lo que garantiza que se comporten como datos reales mientras están protegidos.
¿Por qué es fundamental el enmascaramiento de datos para los equipos de seguridad?
En las organizaciones actuales basadas en datos, la información confidencial a menudo fluye a través de múltiples departamentos, plataformas y servicios de terceros. Los equipos de seguridad deben asegurarse de que estos datos permanezcan protegidos, especialmente fuera de los entornos de producción. Aquí está el por qué el enmascaramiento de datos se vuelve esencial para los equipos de seguridad:
1. Riesgos de exponer los datos de producción a entornos que no son de producción
Muchas organizaciones utilizan copias de datos de producción en vivo para el desarrollo, las pruebas, la capacitación o el análisis. Sin embargo, estos entornos suelen ser menos seguros y más accesibles para el personal interno o los proveedores.
La exposición de datos reales en tales entornos aumenta el riesgo de fugas accidentales, uso indebido o acceso no autorizado. Sin el enmascaramiento de datos adecuado, los datos confidenciales de los clientes, como nombres, direcciones y registros financieros, pueden exponerse a riesgos innecesarios.
2. Requisitos de cumplimiento (por ejemplo, RGPD, CCPA, HIPAA)
Las regulaciones globales de privacidad de datos requieren que las empresas protejan los datos personales y confidenciales en todos los sistemas, no solo en la producción.
- El RGPD (UE) exige la minimización de datos y la seudonimización de los datos personales utilizados en las pruebas o el análisis.
- La CCPA (California) responsabiliza a las empresas por la forma en que se accede a los datos del consumidor, incluso internamente.
- HIPAA (EE. UU.) requiere la seguridad de la información de salud protegida (PHI) en todas las etapas, incluso cuando la utilizan los desarrolladores o analistas de atención médica.
El enmascaramiento de datos ayuda a cumplir con estos requisitos al garantizar que los entornos que no son de producción no expongan información identificable, lo que reduce el riesgo de incumplimiento y multas. Por ejemplo, el incumplimiento del RGPD puede dar lugar a sanciones de hasta 20 millones de euros o el 4% de la facturación global, lo que sea mayor.
3. Filtraciones de datos del mundo real debido a malas prácticas de enmascaramiento
El hecho de no enmascarar los datos correctamente ha provocado varias filtraciones de datos de alto perfil. Un informe de Verizon de 2022 encontró que 61% de las filtraciones de datos internas se debieron a un manejo deficiente de los datos confidenciales en los entornos de desarrollo y prueba. Otro caso involucró a un proveedor de atención médica que enfrentó una multa de 1,5 millones de dólares de HIPAA por permitir que los contratistas accedieran a los datos de los pacientes en una base de datos de prueba.
Estos incidentes resaltan la importancia de enmascarar los datos antes de que se utilicen en entornos menos seguros o temporales. Un enfoque proactivo fortalece la seguridad y genera confianza con los clientes y los reguladores.
Algoritmos de enmascaramiento de datos: cómo se transforma de forma segura la información confidencial
Los algoritmos de enmascaramiento de datos son reglas o métodos basados en la lógica para transformar datos confidenciales en valores enmascarados. Estos algoritmos garantizan que los datos enmascarados conserven su estructura y formato, al tiempo que eliminan cualquier vínculo directo con los datos originales. Los tipos comunes de algoritmos de enmascaramiento de datos incluyen:

Estos algoritmos se seleccionan en función del tipo de datos, el nivel de protección requerido y el uso previsto del conjunto de datos enmascarado. Elegir el algoritmo correcto garantiza tanto la seguridad como la usabilidad operativa.
Exploración del proceso de enmascaramiento de datos: etapas y funciones
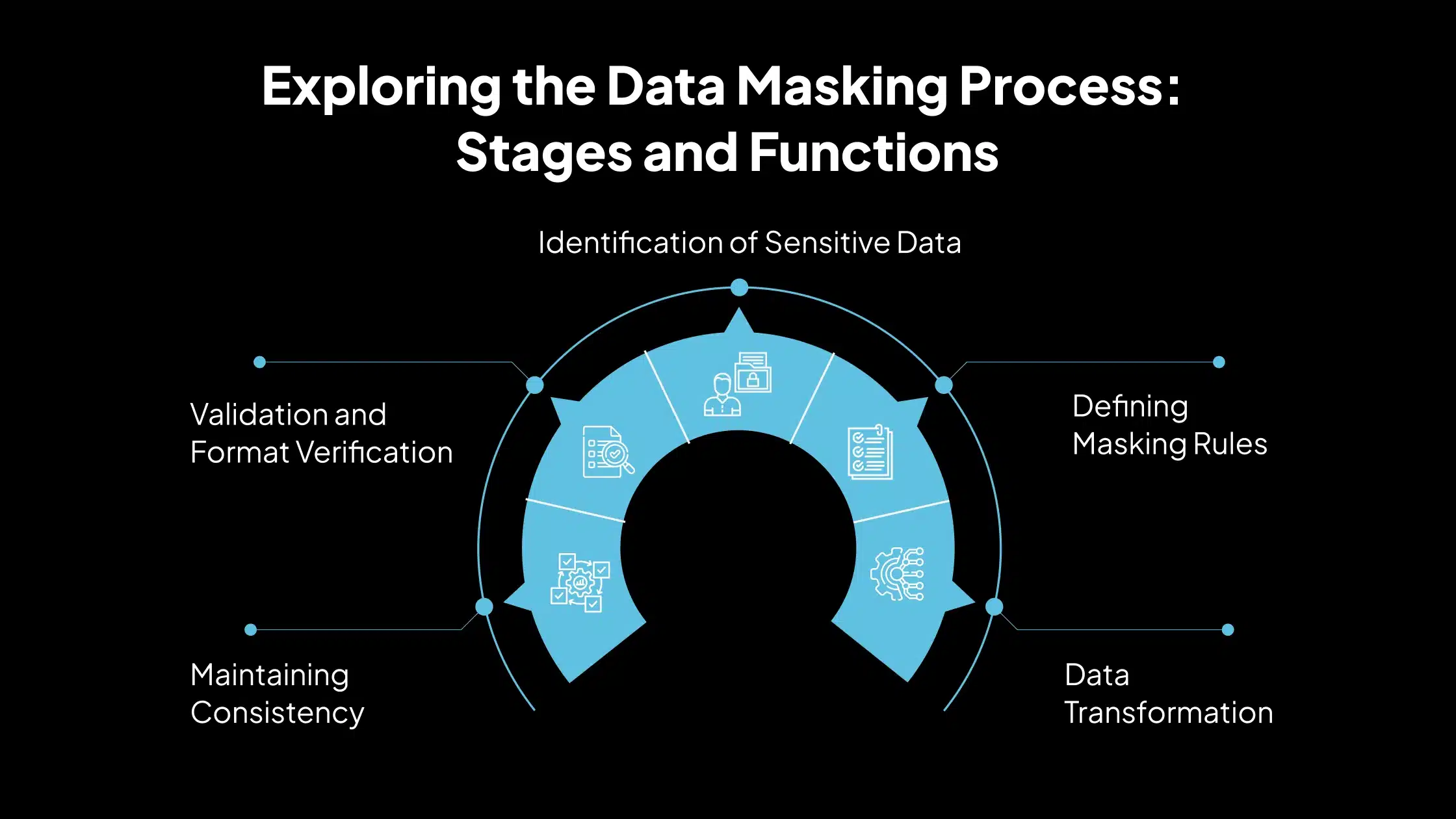
El enmascaramiento de datos protege la información confidencial reemplazándola con valores ficticios, pero estructuralmente similares. El proceso de enmascaramiento sigue un flujo de trabajo sistemático que involucra varios pasos esenciales:
1. Identificación de datos confidenciales
El primer paso es escanear e identificar los datos que deben protegerse. Esto incluye información de identificación personal (PII), detalles financieros, registros de salud y otros datos regulados o confidenciales. Las herramientas de clasificación o las revisiones manuales se utilizan a menudo para localizar campos confidenciales en bases de datos, hojas de cálculo o aplicaciones.
2. Definición de reglas de enmascaramiento
Una vez que se identifican los datos confidenciales, se crean reglas de enmascaramiento específicas. Estas reglas definen cómo se debe transformar cada tipo de datos. Por ejemplo, los nombres pueden reemplazarse con caracteres aleatorios, mientras que los números de tarjetas de crédito pueden ocultarse parcialmente o sustituirse por un formato fijo.
3. Transformación de datos
En esta fase, los datos originales se modifican de acuerdo con las reglas definidas. Varias técnicas de enmascaramiento, como la sustitución, la mezcla, el cifrado o la tokenización, reemplazan los valores reales, manteniendo al mismo tiempo los tipos y formatos de datos originales. Este paso garantiza que los datos enmascarados parezcan realistas y puedan ser procesados por los sistemas sin errores.
4. Mantenimiento de la coherencia
Para garantizar la integridad de los datos en todos los sistemas, el mismo valor confidencial siempre debe enmascararse de la misma manera. Este paso garantiza la coherencia referencial, especialmente cuando los mismos datos aparecen en varias tablas o bases de datos. Por ejemplo, si una dirección de correo electrónico está enmascarada en un sistema, debe enmascararse de forma idéntica dondequiera que aparezca.
5. Validación y verificación del formato
Después de la transformación, los datos enmascarados se validan para confirmar que se ajustan a los requisitos de formato y la lógica empresarial. Este paso comprueba la estructura de los datos, las restricciones de longitud y las dependencias de los campos para garantizar que el conjunto de datos siga siendo funcional y no interrumpa los flujos de trabajo de la aplicación.
Tipos de enmascaramiento de datos: elección del enfoque correcto para sus datos
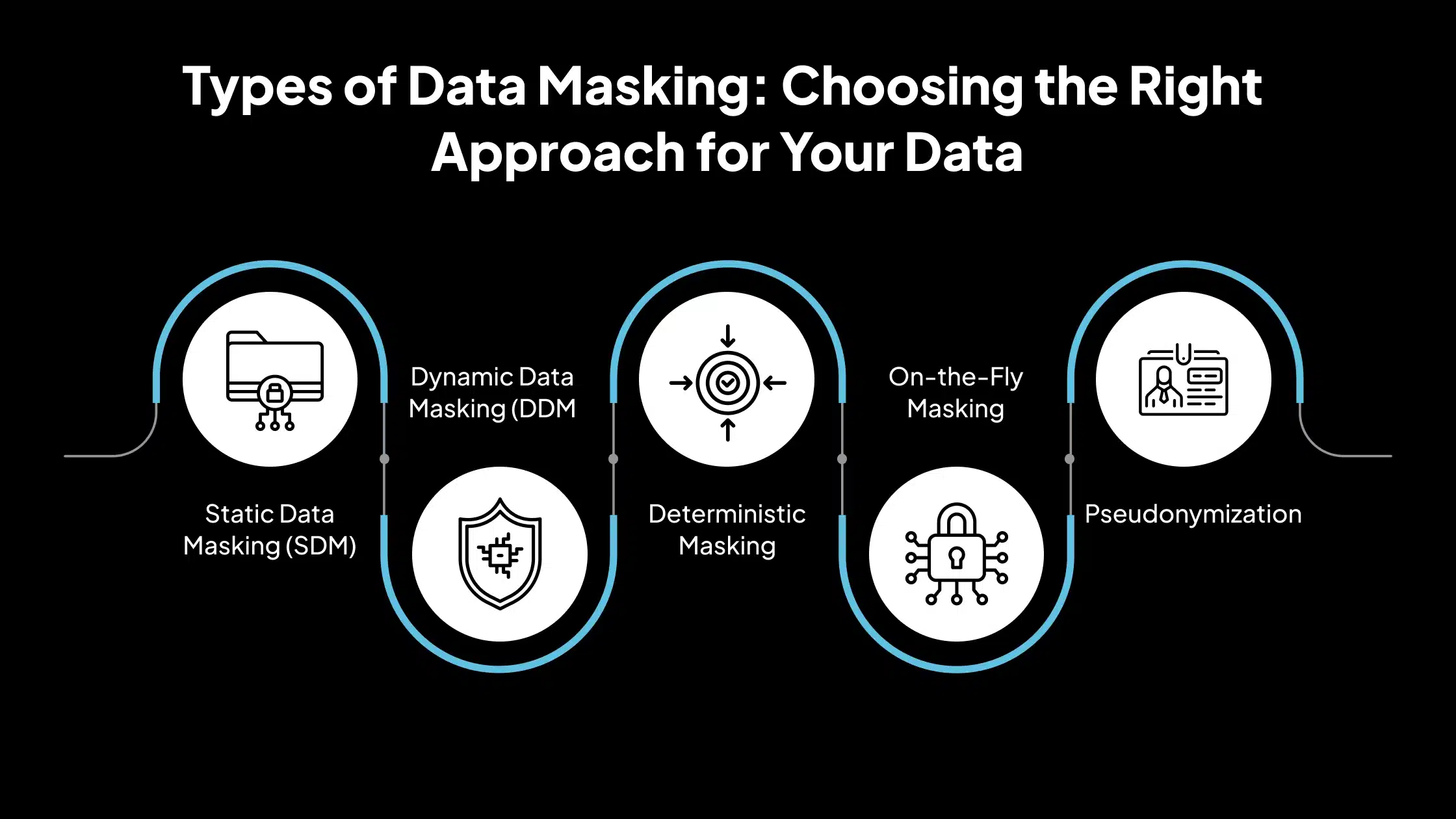
El enmascaramiento de datos se puede implementar de manera diferente según el caso de uso, los objetivos de seguridad y el entorno técnico. A continuación, se muestran los tipos esenciales de enmascaramiento de datos utilizados por los equipos de seguridad y cumplimiento, cada uno explicado con relevancia práctica:
1. Enmascaramiento de datos estáticos (SDM)
El enmascaramiento de datos estáticos implica la creación de una copia de la base de datos enmascarada donde los valores confidenciales se reemplazan antes de trasladarse a entornos que no son de producción. Los datos de producción originales se extraen, se enmascaran de acuerdo con las reglas definidas y se almacenan en un nuevo conjunto de datos.
Por ejemplo, un equipo de desarrollo utiliza un clon enmascarado de la base de datos de clientes para crear y probar nuevas funciones sin exponer datos personales reales. Este tipo de enmascaramiento de datos es ideal para el desarrollo de software, las pruebas, la capacitación y el intercambio con terceros.
2. Enmascaramiento de datos dinámicos (DDM)
El enmascaramiento de datos dinámicos aplica reglas de enmascaramiento en tiempo real a medida que se ejecutan las consultas. Los datos originales permanecen sin cambios en la base de datos, pero los usuarios con acceso restringido ven valores enmascarados al recuperar los datos.
Por ejemplo, un agente de servicio al cliente que ejecuta una consulta en una tabla de clientes ve números de tarjetas de crédito enmascarados, mientras que un administrador ve el valor completo. Esto es útil en entornos de producción donde se necesita una visibilidad limitada de los datos sin alterar los datos almacenados.
3. Enmascaramiento determinista
En el enmascaramiento determinista, la misma entrada siempre produce la misma salida enmascarada. Esto garantiza la coherencia en varias tablas o sistemas donde se requiere la integridad referencial.
Por ejemplo, el nombre «Alice Smith» siempre se enmascara como «Max Doe» en todas las bases de datos. Esto es necesario cuando los mismos datos aparecen en varios lugares y se deben mantener relaciones coherentes, por ejemplo, en bases de datos relacionales.
4. Enmascaramiento sobre la marcha
Este tipo de enmascaramiento se produce durante la transferencia de datos entre sistemas. Los datos confidenciales se enmascaran a medida que se mueven de un entorno de producción a un entorno de desarrollo o prueba, sin almacenamiento temporal de datos sin enmascarar.
Los datos se enmascaran en tránsito a medida que se extraen de la producción y se envían al entorno de un desarrollador.
Esto es adecuado para flujos de trabajo automatizados y canalizaciones de integración continua donde se requiere el enmascaramiento de datos en tiempo real durante la migración.
5. Seudonimización
La seudonimización reemplaza los identificadores personales con seudónimos que son coherentes pero no se pueden vincular a los datos originales sin información adicional almacenada por separado. A diferencia del enmascaramiento tradicional, permite la reversibilidad parcial bajo un estricto control.
Por ejemplo, el nombre real de un paciente se puede reemplazar con un ID codificado como «Usuario12345», con la asignación almacenada en una bóveda segura. Esto es común en la atención médica y la investigación, donde se necesita el análisis de datos sin revelar identidades, al tiempo que se permite la reidentificación futura en condiciones controladas.
Las 7 principales técnicas de enmascaramiento de datos que todo equipo de seguridad debe implementar
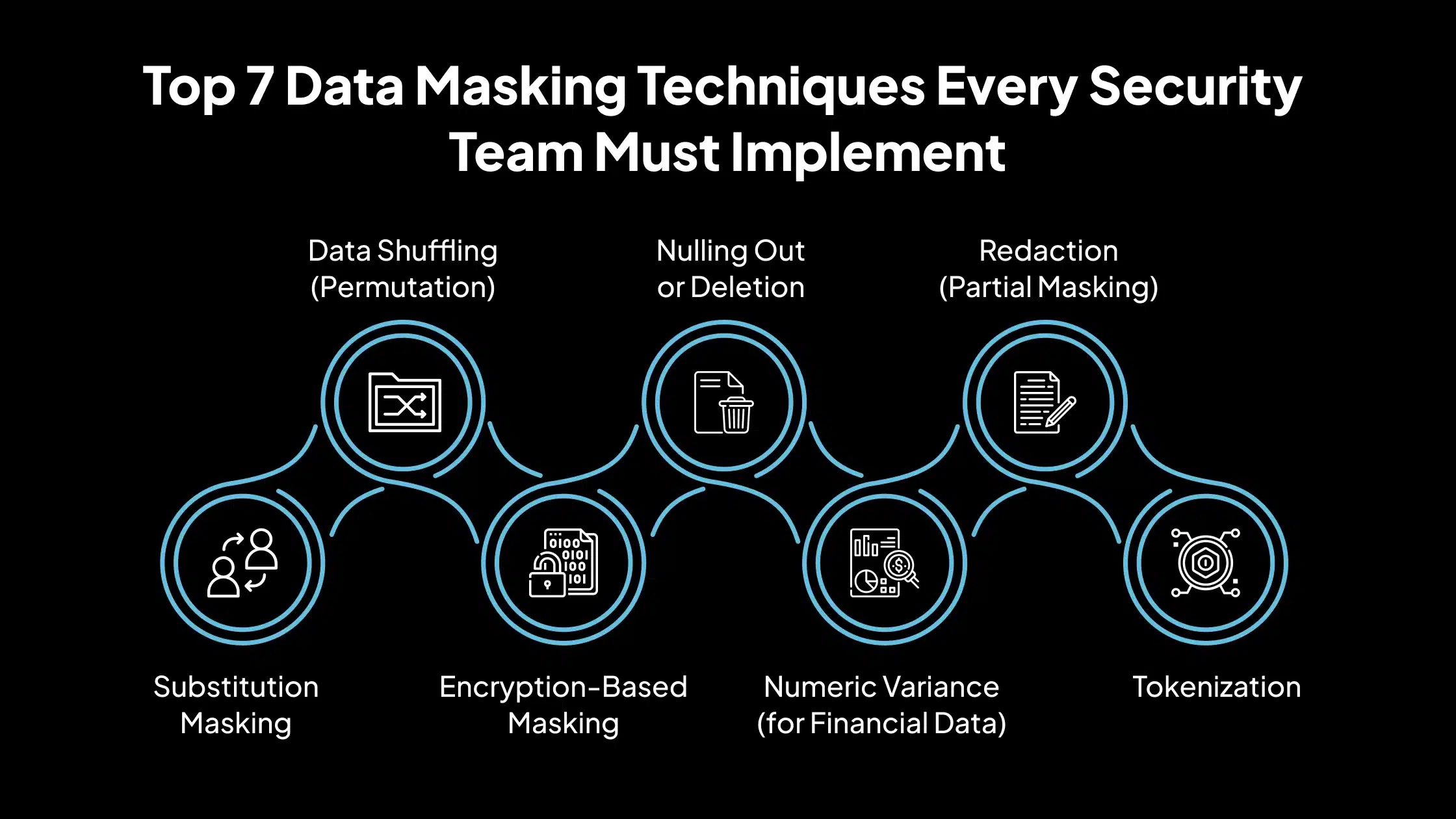
El enmascaramiento de datos no es una solución única para todos; diferentes escenarios requieren diferentes métodos para proteger los datos confidenciales sin perder la usabilidad. A continuación, se muestran siete técnicas probadas de enmascaramiento de datos que los equipos de seguridad pueden aplicar para proteger la información confidencial en los entornos de desarrollo, prueba, análisis y operativos.
Enmascaramiento de sustitución
El enmascaramiento de sustitución reemplaza los datos confidenciales originales con valores falsos de apariencia realista extraídos de tablas de búsqueda predefinidas o generados dinámicamente. El formato de los datos sigue siendo coherente con el original.
Cada valor original se sustituye por un valor seleccionado aleatoriamente de una lista predefinida. Por ejemplo, los nombres reales de los empleados se pueden reemplazar con nombres de un conjunto de datos sintéticos. Los datos sustituidos imitan la estructura, el tipo y el formato del original.
Casos de uso ideales
El enmascaramiento de sustitución es muy adecuado para enmascarar información de identificación personal, como nombres, direcciones de correo electrónico o direcciones físicas en las plataformas CRM. Garantiza que los detalles reales del usuario nunca se expongan durante las pruebas internas o el acceso de terceros.
Esta técnica es particularmente eficaz en entornos de prueba que requieren que los datos se comporten como entradas reales del usuario. Permite a los desarrolladores y a los equipos de control de calidad simular las interacciones del usuario sin comprometer la privacidad de los datos. El enmascaramiento de sustitución también es valioso en demostraciones de productos o sesiones de capacitación, donde se necesitan datos realistas de empleados o clientes para mostrar los flujos de trabajo sin revelar registros genuinos.
Puntos fuertes de seguridad
El enmascaramiento de sustitución reduce significativamente el riesgo de ingeniería inversa o reconstrucción de datos no autorizada al garantizar que los valores enmascarados no estén directamente vinculados a los originales.
Admite una alta usabilidad, lo que permite que las aplicaciones y las interfaces de usuario funcionen como se espera sin encontrar errores de formato o validación debido a datos alterados. A diferencia del cifrado, no requiere la administración de claves, lo que facilita su implementación al tiempo que proporciona una sólida protección en entornos que no son de producción.
Mezcla de datos (permutación)
La mezcla reordena los valores existentes dentro de una columna para que los datos parezcan legítimos, pero ya no se alinean con su registro original. Los valores de una sola columna (por ejemplo, los números de la seguridad social) se mezclan aleatoriamente entre las filas. Esto garantiza que ningún valor esté en su posición original, al tiempo que se mantiene un formato de datos válido.
Casos de uso ideales
La mezcla de datos es ideal para enmascarar identificadores internos o números de contacto en informes donde los valores reales son innecesarios, pero el formato de los datos debe conservarse. Permite que los informes sigan siendo estructuralmente precisos sin exponer información real.
Esta técnica funciona bien para los conjuntos de datos de capacitación donde mantener la distribución general de valores es esencial para el comportamiento realista del modelo, aunque los puntos de datos exactos se aleatoricen.
También es adecuado para escenarios en los que mantener la coherencia interna entre los registros no es esencial, como las tareas básicas de análisis o informes en las que la integridad relacional no es una prioridad.
Puntos fuertes de seguridad
La mezcla de datos es sencilla, lo que la convierte en una opción práctica para las necesidades de enmascaramiento rápido sin una configuración extensa. Conserva los tipos de datos originales y las características estadísticas, lo que garantiza que las salidas sigan siendo válidas para la mayoría de las funciones de procesamiento e informes.
Reordenar los valores sin asignar directamente a la fuente separa eficazmente los vínculos identificables entre los datos enmascarados y los originales, lo que reduce los riesgos de exposición.
Enmascaramiento basado en cifrado
Este método utiliza algoritmos de cifrado para convertir los valores originales en texto cifrado ilegible, protegiendo los datos del acceso no autorizado.
Se aplican algoritmos criptográficos estándar como AES o RSA para transformar los datos. Solo los usuarios con la clave de descifrado correcta pueden acceder a los valores originales. Dependiendo de la configuración, el enmascaramiento puede ser reversible o irreversible.
Casos de uso ideales
El enmascaramiento basado en cifrado es ideal para transmitir de forma segura datos confidenciales a través de diferentes sistemas o entornos, lo que garantiza que permanezcan protegidos durante la transferencia.
Se utiliza comúnmente para almacenar campos altamente confidenciales, como contraseñas, números de cuenta o registros financieros que deben permanecer confidenciales y accesibles solo en condiciones controladas.
Esto también es práctico en sistemas que requieren un enmascaramiento reversible, lo que permite a los usuarios autorizados descifrar y ver los datos originales cuando sea necesario.
Puntos fuertes de seguridad
El cifrado ofrece una alta protección mediante algoritmos criptográficos bien establecidos, lo que hace que sea extremadamente difícil para terceros no autorizados descifrar los datos enmascarados. Es particularmente adecuado para entornos que aplican políticas estrictas de control de acceso, donde solo usuarios o servicios selectos pueden descifrar información confidencial.
Además, el cifrado ayuda a las organizaciones a cumplir con los requisitos reglamentarios relacionados con los datos en reposo y en tránsito, como los que se describen en PCI DSS, HIPAA y RGPD.
Anulación o eliminación
Esta técnica reemplaza los valores confidenciales con NULL o los elimina por completo del conjunto de datos, eliminando cualquier rastro identificable. En escenarios más agresivos, se pueden eliminar filas o columnas enteras si representan un riesgo para la privacidad.
Casos de uso ideales
La anulación o eliminación de datos es eficaz para exportar conjuntos de datos a terceros cuando la información confidencial no es necesaria para sus tareas. Garantiza que solo se compartan los campos no confidenciales, minimizando la exposición.
Esta técnica también es adecuada para registros históricos donde los datos personales ya no son relevantes o necesarios, lo que ayuda a las organizaciones a limpiar los sistemas heredados sin retener riesgos innecesarios.
Se alinea bien con los esfuerzos de cumplimiento centrados en la minimización o eliminación de datos, especialmente cuando las regulaciones exigen la eliminación permanente de categorías específicas de datos personales.
Puntos fuertes de seguridad
Este método garantiza que no quede información privada en el conjunto de datos al eliminar o anular por completo los datos confidenciales. Reduce el riesgo de reidentificación, ofreciendo una sólida garantía de privacidad para individuos y organizaciones.
La anulación o eliminación es especialmente útil cuando el objetivo es la anonimización irreversible, lo que la convierte en una estrategia fiable para requisitos estrictos de protección de datos.
Varianza numérica (para datos financieros)
La varianza numérica introduce un nivel controlado de aleatoriedad en los campos numéricos, oscureciendo los valores originales al tiempo que conserva la precisión relativa.
Se añade o se resta una varianza numérica fija o basada en porcentajes de cada número. Por ejemplo, un salario de 60.000 $ puede enmascararse como 62.500 $ o 58.000 $, preservando el rango y los patrones generales.
Casos de uso ideales
La varianza numérica es muy adecuada para los informes financieros internos, donde las tendencias y los patrones son más importantes que los valores precisos. Permite a los equipos revisar el rendimiento sin revelar cifras exactas.
También es valiosa para los modelos de análisis y previsión, lo que permite a los científicos de datos trabajar con rangos realistas al tiempo que protegen los detalles financieros confidenciales.
Además, este método es ideal para compartir datos de costes o presupuestos con proveedores externos, lo que garantiza que se puedan comunicar las perspectivas empresariales sin exponer números confidenciales.
Puntos fuertes de seguridad
La varianza numérica preserva la integridad estadística general de los datos, lo que permite un análisis preciso al tiempo que oculta los valores exactos. Ayuda a prevenir el uso indebido interno al garantizar que nadie pueda acceder a cifras financieras reales a menos que esté explícitamente autorizado. Esto apoya las pruebas o el modelado seguros y válidos, especialmente en entornos sin divulgación financiera completa.
Redacción (enmascaramiento parcial)
La redacción oculta los datos confidenciales, que se utiliza comúnmente para mostrar información limitada al tiempo que se ocultan los identificadores clave.
Algunos datos se enmascaran utilizando caracteres como asteriscos (por ejemplo, ****5678 para una tarjeta de crédito). Esto preserva información como los últimos dígitos para permitir la referencia o la validación.
Casos de uso ideales
La redacción es ideal para escenarios donde es necesaria la visibilidad parcial de los datos, como mostrar los últimos cuatro dígitos de una tarjeta de crédito o partes de un número de la Seguridad Social.
También es valiosa para las confirmaciones de correo electrónico, los registros o las pistas de auditoría donde se necesitan detalles de usuario limitados para la verificación sin revelar identidades completas. Esta técnica se adapta a los sistemas que requieren la visualización parcial de datos para la eficiencia operativa, como las herramientas de atención al cliente o las plataformas de supervisión de transacciones.
Puntos fuertes de seguridad
La redacción evita la exposición completa de los datos al tiempo que preserva suficiente información para la interacción o validación del usuario. Reduce el riesgo durante la comunicación y la resolución de problemas al garantizar que los detalles confidenciales no sean totalmente visibles para los usuarios finales o los equipos de soporte. Es sencilla y fácil de entender, lo que la convierte en una opción práctica para muchas aplicaciones empresariales.
Tokenización
La tokenización reemplaza los datos confidenciales con valores sustitutos generados aleatoriamente (tokens) no relacionados con los datos originales.
Cada valor confidencial se reemplaza con un token único almacenado en una tabla de asignación o bóveda segura. A diferencia del cifrado, los tokens no se derivan de los datos originales y no se pueden invertir sin acceso a la base de datos de tokens.
Casos de uso ideales
La tokenización es muy eficaz en los sistemas de procesamiento de pagos, donde ayuda a cumplir con la normativa PCI DSS al reemplazar los datos del titular de la tarjeta con tokens no confidenciales.
También se utiliza ampliamente para proteger la información de identificación personal (PII) en las bases de datos de clientes, lo que permite a las organizaciones almacenar y gestionar los datos de los usuarios de forma segura. Además, la tokenización admite API seguras y arquitecturas de microservicios, donde los datos confidenciales deben gestionarse en sistemas distribuidos sin exposición.
Puntos fuertes de seguridad
La tokenización ofrece una gran seguridad al reemplazar los datos reales con tokens aleatorios que no tienen ningún valor explotable sin acceso a la bóveda de asignación segura. Permite el control de acceso basado en roles, lo que garantiza que solo los sistemas o usuarios autorizados puedan recuperar los valores originales cuando sea necesario.
Al minimizar la exposición de los datos confidenciales, la tokenización también ayuda a reducir el alcance y la complejidad de las auditorías de cumplimiento según normas como PCI DSS y HIPAA.
Agilización del acceso seguro con la herramienta inteligente de enmascaramiento de datos de Avahi
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi ofrece herramientas que ayudan a las organizaciones a gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es el Data Masker, diseñado para proteger los datos financieros y de identificación personal al tiempo que apoya la eficiencia operativa.
Descripción general del Data Masker de Avahi
El Data Masker de Avahi es una herramienta versátil de protección de datos diseñada para ayudar a las organizaciones a gestionar de forma segura la información confidencial en diversas industrias, incluyendo la atención sanitaria, las finanzas, el comercio minorista y los seguros.
La herramienta permite a los equipos enmascarar datos confidenciales como números de cuenta, registros de pacientes, identificadores personales y detalles de transacciones sin interrumpir los flujos de trabajo operativos.
El Data Masker de Avahi garantiza que solo los usuarios autorizados puedan ver o interactuar con datos confidenciales aplicando técnicas avanzadas de enmascaramiento y aplicando el control de acceso basado en roles. Esto es especialmente importante cuando varios departamentos o proveedores externos acceden a los datos.
Ya sea protegiendo la información de salud del paciente en cumplimiento con HIPAA, anonimizando los registros financieros para PCI DSS o asegurando los datos del cliente para GDPR, la herramienta ayuda a las organizaciones a minimizar el riesgo de acceso no autorizado al tiempo que preserva la usabilidad de los datos para fines de desarrollo, análisis y supervisión del fraude.
Cómo funciona la función de enmascaramiento de datos
El proceso de enmascaramiento de información confidencial utilizando el Data Masker de Avahi es intuitivo y está impulsado por la IA:
1. Cargar archivo
Los usuarios comienzan cargando el conjunto de datos o el archivo que contiene información confidencial a través de la plataforma Avahi.
2. Vista previa de los datos
Una vez cargada, la herramienta muestra el contenido estructurado, resaltando los campos que normalmente se consideran confidenciales (por ejemplo, PAN, nombres, fechas de nacimiento).
3. Haga clic en la opción ‘Enmascarar datos’
A continuación, los usuarios inician el proceso de enmascaramiento seleccionando la opción ‘Enmascarar datos’ de la interfaz.
4. Transformación impulsada por la IA
Entre bastidores, Avahi utiliza algoritmos inteligentes y reglas predefinidas para identificar y enmascarar los valores de datos confidenciales. Esta transformación garantiza que los datos enmascarados mantengan su formato y usabilidad, pero no contengan la información original.
5. Salida segura
El archivo resultante muestra valores ofuscados en lugar del contenido confidencial original, que se puede utilizar de forma segura para el análisis de fraude, la elaboración de informes o la colaboración con terceros.
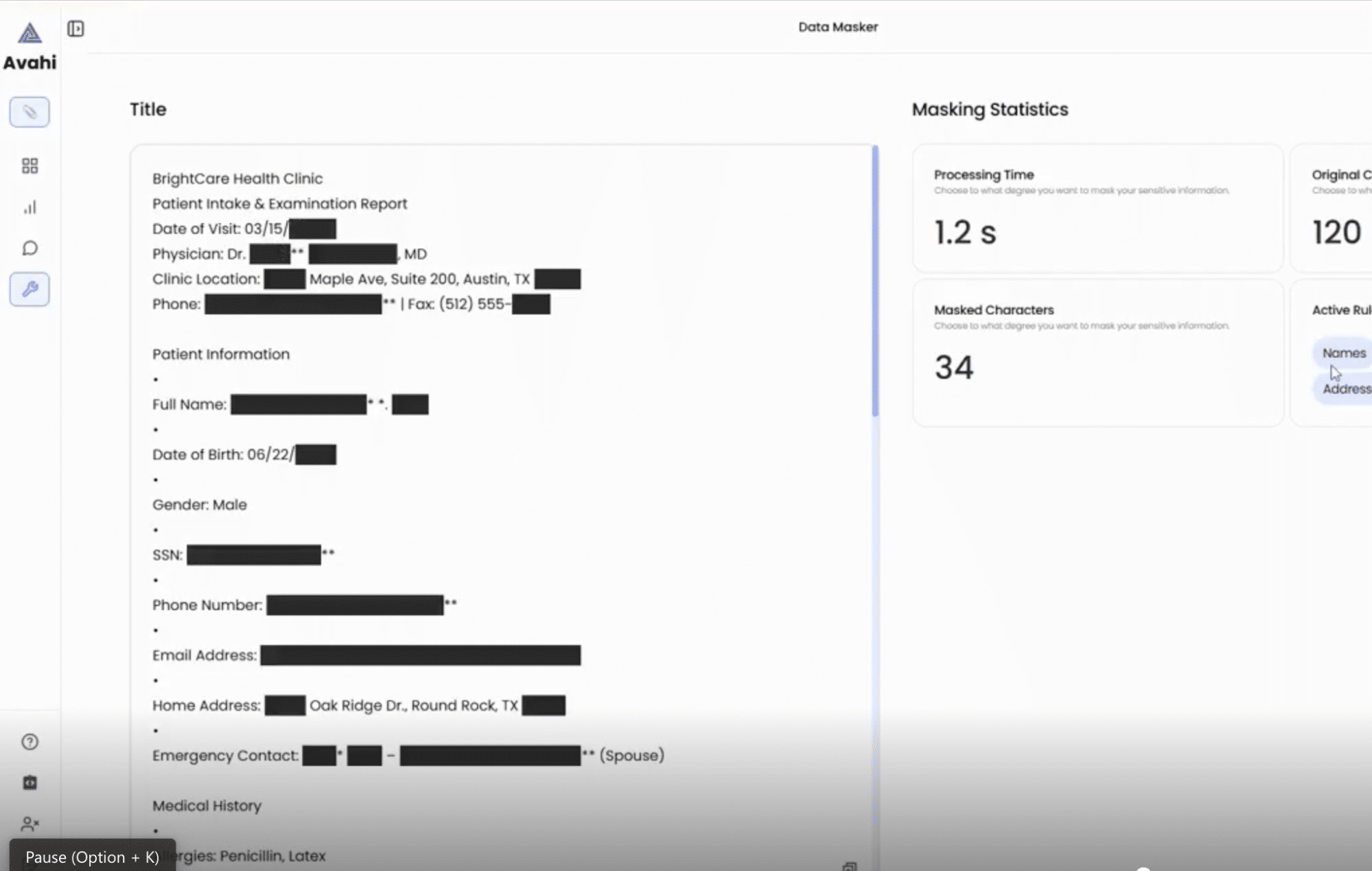
El Data Masker de Avahi integra la automatización, los controles fáciles de usar y el enmascaramiento seguro impulsado por la IA para garantizar el cumplimiento normativo (por ejemplo, PCI DSS) al tiempo que minimiza la fricción operativa.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi
En Avahi, entendemos la importancia crítica de salvaguardar la información confidencial al tiempo que garantizamos flujos de trabajo operativos sin problemas.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programe una llamada de demostración.
Preguntas frecuentes (FAQ)
1. ¿Qué son las técnicas de enmascaramiento de datos y por qué son necesarias?
Las técnicas de enmascaramiento de datos protegen la información confidencial reemplazando los datos originales con valores ficticios pero realistas. Estas técnicas son cruciales para asegurar los datos personales y financieros en entornos que no son de producción, como el desarrollo, las pruebas o el análisis, al tiempo que se mantiene la usabilidad de los datos.
2. ¿Cuáles son los diferentes tipos de enmascaramiento de datos?
Los principales tipos de enmascaramiento de datos incluyen el enmascaramiento de datos estáticos, el enmascaramiento de datos dinámicos, el enmascaramiento determinista, el enmascaramiento sobre la marcha y la seudonimización. Cada tipo sirve para diferentes casos de uso dependiendo de las necesidades de seguridad, la arquitectura del sistema y los requisitos reglamentarios.
3. ¿Cómo funcionan los algoritmos de enmascaramiento de datos?
Los algoritmos de enmascaramiento de datos aplican transformaciones basadas en la lógica a los datos confidenciales para hacerlos ilegibles al tiempo que preservan el formato y la estructura. Los algoritmos estándar incluyen la sustitución, la mezcla, el hash, el enmascaramiento basado en el cifrado y las funciones de enmascaramiento basadas en reglas.
4. ¿Cuál es la diferencia entre el enmascaramiento de datos, el cifrado y la anonimización?
A diferencia del cifrado, que requiere una clave de descifrado, o la anonimización, que elimina permanentemente los identificadores de datos, las técnicas de enmascaramiento de datos reemplazan los datos originales con valores funcionales que conservan la estructura para las pruebas o el análisis sin revelar información real.
5. ¿Cuándo deben las organizaciones utilizar herramientas de enmascaramiento de bases de datos?
Las herramientas de enmascaramiento de bases de datos deben utilizarse al replicar los datos de producción para el desarrollo, el control de calidad, la formación o la elaboración de informes. Estas herramientas automatizan el enmascaramiento de campos confidenciales como la PII o los datos financieros y garantizan el cumplimiento de las regulaciones GDPR, HIPAA y PCI DSS.



