
TL;DR
|
Cada 39 segundos, una empresa sufre un ciberataque.
En un entorno donde los datos confidenciales impulsan todo, desde el conocimiento del cliente hasta las operaciones financieras, una sola infracción puede perturbar la confianza, desencadenar multas regulatorias y dañar la reputación, a menudo de forma irreparable.
A medida que las filtraciones de datos aumentan en frecuencia y gravedad, las organizaciones están bajo una inmensa presión para proteger la información personal y transaccional. Dos de las técnicas más adoptadas en la protección de datos hoy en día son la tokenización de datos y el enmascaramiento de datos. Ambos sirven a un objetivo común, salvaguardar los datos confidenciales, pero funcionan de maneras fundamentalmente diferentes, y elegir el incorrecto para el contexto equivocado puede dejar lagunas críticas.
Este blog desglosa la diferencia entre la tokenización y el enmascaramiento de datos, explicando cómo funciona cada método, cuándo usarlos y cómo se alinean con los marcos regulatorios.
Ya sea protegiendo la información de la tarjeta de crédito en un sistema de pago o anonimizando los registros de pacientes para el análisis, comprender las fortalezas y limitaciones de cada uno es el primer paso para construir una defensa de datos más sólida e inteligente.
Comprensión de la tokenización de datos: definición, tipos, casos de uso y beneficios
La tokenización de datos es una técnica de seguridad de datos que reemplaza la información confidencial, como números de tarjetas de crédito, números de seguridad social o identificadores personales, con marcadores de posición no confidenciales llamados tokens.
Estos tokens son valores generados aleatoriamente sin una relación significativa con los datos originales. Es importante destacar que los datos originales se almacenan de forma segura en un sistema separado conocido como bóveda de tokens, que asigna los tokens a sus valores reales cuando los sistemas autorizados los necesitan.
La característica esencial de la tokenización es que se conserva el formato de los datos originales. Por ejemplo, un número de tarjeta de crédito de 16 dígitos podría reemplazarse con otro token de 16 dígitos que se asemeja a un número de tarjeta válido, pero no tiene valor fuera del sistema.
Tipo de tokenización de datos
1. Tokenización abovedada
En la tokenización abovedada, una base de datos segura, a menudo llamada bóveda de tokens, almacena la relación entre los datos confidenciales originales y su token correspondiente.
Cuando los datos confidenciales necesitan ser tokenizados, se envían a la bóveda, que genera un token único y almacena la asignación. El acceso a la bóveda está estrictamente controlado; solo los sistemas autorizados pueden recuperar los datos originales utilizando el token.
2. Tokenización sin bóveda
La tokenización sin bóveda elimina la necesidad de una base de datos central mediante el uso de algoritmos para generar tokens. Estos algoritmos pueden producir determinísticamente el mismo token para una entrada dada, lo que permite la generación y reversión de tokens sin almacenar los datos originales.
Esto mejora la escalabilidad y reduce la latencia, lo que lo hace adecuado para aplicaciones de alto rendimiento.
3. Tokenización que preserva el formato
La tokenización que preserva el formato garantiza que los tokens generados mantengan el mismo formato y longitud que los datos originales.
Por ejemplo, un número de tarjeta de crédito de 16 dígitos se reemplazaría con otro token de 16 dígitos. Esta preservación permite a los sistemas procesar datos tokenizados sin requerir cambios significativos en la infraestructura existente.
Ventajas de la tokenización de datos
1. Preservación del formato
Una de las principales ventajas de la tokenización es que los tokens mantienen la misma estructura y longitud que los datos originales. Esto facilita la integración de datos tokenizados en los sistemas existentes sin requerir cambios en los esquemas de la base de datos, la lógica de la aplicación o las interfaces de usuario.
Por ejemplo, un sistema que espera un número de teléfono de 10 dígitos puede seguir funcionando correctamente utilizando un token de 10 dígitos.
2. Seguridad de alto nivel
La tokenización mejora la seguridad de los datos al eliminar los datos confidenciales de los entornos vulnerables. Dado que los tokens son aleatorios y no tienen un significado intrínseco, no son útiles incluso si se interceptan.
Además, dado que la tokenización no utiliza algoritmos matemáticos para transformar los datos (a diferencia del cifrado), es inmune a los ataques criptográficos y a los métodos de fuerza bruta.
3. Alcance de cumplimiento reducido (PCI DSS, GDPR)
La tokenización reduce significativamente el alcance de las auditorías de cumplimiento al eliminar los datos confidenciales del entorno de procesamiento primario. Bajo PCI DSS, los sistemas que solo manejan tokens en lugar de datos de tarjetas pueden estar exentos de controles estrictos.
Del mismo modo, en el contexto del Reglamento General de Protección de Datos (RGPD), la tokenización ayuda a minimizar la cantidad de información de identificación personal (PII) almacenada, lo que reduce la exposición y las posibles sanciones en caso de una filtración de datos.
Enmascaramiento de datos explicado: métodos, aplicaciones y ventajas de cumplimiento
El enmascaramiento de datos es una técnica utilizada para ocultar u oscurecer información confidencial alterando su contenido para que se vuelva ilegible o sin sentido para los usuarios no autorizados.
A diferencia de la tokenización, que reemplaza los datos con un token recuperable, el enmascaramiento de datos generalmente implica transformar los datos de una manera que evite que se reviertan. El enmascaramiento tiene como objetivo proteger los datos confidenciales en entornos que no son de producción, como durante el desarrollo de software, las pruebas, la capacitación o el análisis, donde los datos reales no son necesarios.
Existen múltiples técnicas de enmascaramiento, que incluyen la codificación de caracteres, la anulación de datos, la mezcla, la sustitución y el desenfoque de datos. Cada método se selecciona en función del caso de uso y el nivel de protección requerido.
Tipos de enmascaramiento de datos
1. Enmascaramiento de datos estático
El enmascaramiento de datos estático se realiza en una copia de la base de datos de producción. Los datos confidenciales originales se reemplazan con valores enmascarados en esta versión duplicada antes de que se utilicen en entornos inferiores, como el desarrollo o el control de calidad.
Esto garantiza que los datos confidenciales nunca salgan del límite de producción seguro. Una vez enmascarados, los datos no se pueden revertir.
2. Enmascaramiento de datos dinámico
El enmascaramiento de datos dinámico se produce en tiempo real durante la recuperación de datos. Los campos confidenciales se enmascaran sobre la marcha en función de los roles de usuario y los derechos de acceso, mientras que los datos subyacentes permanecen sin cambios en la base de datos. Este método es adecuado cuando diferentes usuarios requieren diferentes niveles de acceso al mismo conjunto de datos.
Por ejemplo, un representante de servicio al cliente puede ver solo los últimos cuatro dígitos del número de tarjeta de crédito de un cliente, mientras que un gerente con privilegios más altos puede ver el número completo. DDM es útil para controlar el acceso a datos confidenciales en entornos de producción en vivo sin modificar los datos reales.
3. Enmascaramiento determinista
El enmascaramiento determinista garantiza que el mismo valor de entrada siempre se reemplace con el mismo valor enmascarado. Esta consistencia es crucial cuando los datos enmascarados necesitan mantener la integridad referencial en diferentes sistemas o bases de datos.
Por ejemplo, si el nombre «Alice» se enmascara como «Elex» en una tabla, también se enmascarará como «Elex» en todas las demás tablas relacionadas. Esto es particularmente beneficioso en escenarios de prueba donde son necesarias relaciones de datos consistentes.
Beneficios del enmascaramiento de datos
1. Minimiza el riesgo en entornos que no son de producción
Uno de los principales beneficios del enmascaramiento de datos es su capacidad para proteger los datos confidenciales fuera del entorno de producción. Dado que los sistemas de prueba, ensayo o análisis son más vulnerables al acceso no autorizado, el uso de datos enmascarados garantiza que cualquier infracción en estos entornos no exponga datos reales.
2. Preserva la estructura e integridad de los datos
Los datos enmascarados mantienen el formato, las relaciones y la integridad referencial de la base de datos original. Esto permite a los equipos realizar pruebas y análisis precisos sin necesidad de datos reales.
Por ejemplo, los ID de cliente pueden estar enmascarados, pero aún siguen un formato válido y permanecen vinculados a los registros de transacciones asociados.
3. Admite el cumplimiento de las regulaciones de privacidad
El enmascaramiento de datos se usa ampliamente para respaldar el cumplimiento de varias regulaciones de protección de datos, incluidas HIPAA, GDPR y estándares ISO. Las organizaciones reducen su exposición legal y financiera en caso de una filtración de datos al anonimizar o seudonimizar los datos confidenciales.
Tokenización vs. Enmascaramiento de datos: cómo funciona cada proceso
Comprender cómo operan la tokenización y el enmascaramiento de datos es crucial para implementar estrategias efectivas de protección de datos. Ambas técnicas tienen como objetivo salvaguardar la información confidencial, pero difieren en sus metodologías y aplicaciones.
1. Cómo funciona la tokenización de datos
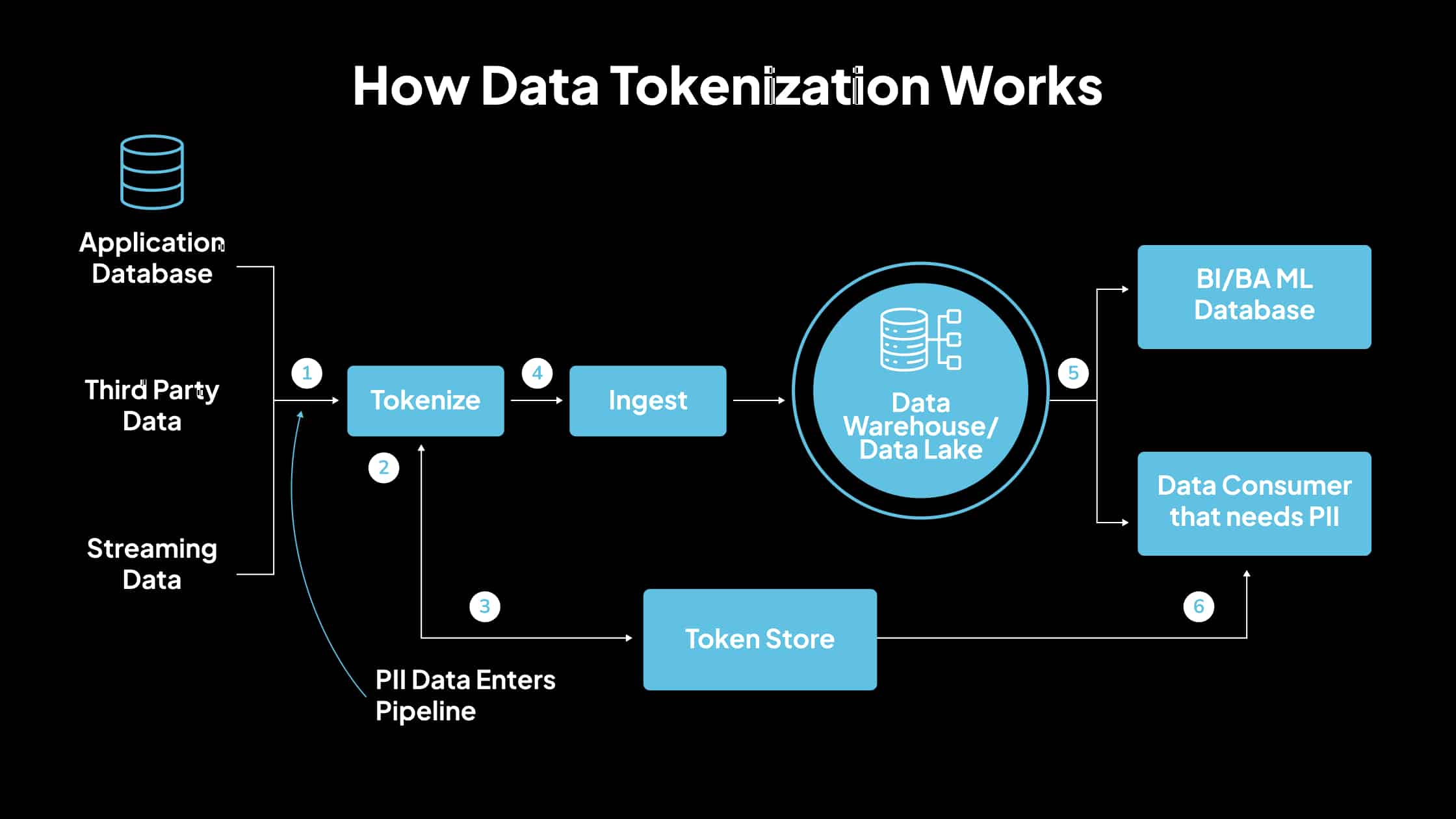
La tokenización de datos implica sustituir elementos de datos confidenciales con equivalentes no confidenciales o tokenizados. Estos tokens no tienen un significado o valor explotable, lo que reduce el riesgo asociado con las filtraciones de datos. Los datos confidenciales originales se almacenan de forma segura en una ubicación separada, a menudo denominada bóveda de tokens.
Pasos esenciales en la tokenización:
- Identificación de datos confidenciales: Determine qué elementos de datos requieren protección, como números de tarjetas de crédito, números de seguridad social o identificadores personales.
- Generación de tokens: Cree un token que reemplace los datos confidenciales. Este token suele ser una cadena aleatoria que mantiene el formato de los datos originales, pero carece de cualquier valor significativo.
- Asignación segura: Establezca una asociación segura entre el token y los datos originales. Esta asignación se almacena en un entorno protegido, lo que garantiza que solo los sistemas autorizados puedan recuperar los datos originales cuando sea necesario.
- Uso de datos: Reemplace el token con datos confidenciales en sistemas y procesos. Esto permite operaciones normales sin exponer información confidencial real.
2. Cómo funciona el enmascaramiento de datos
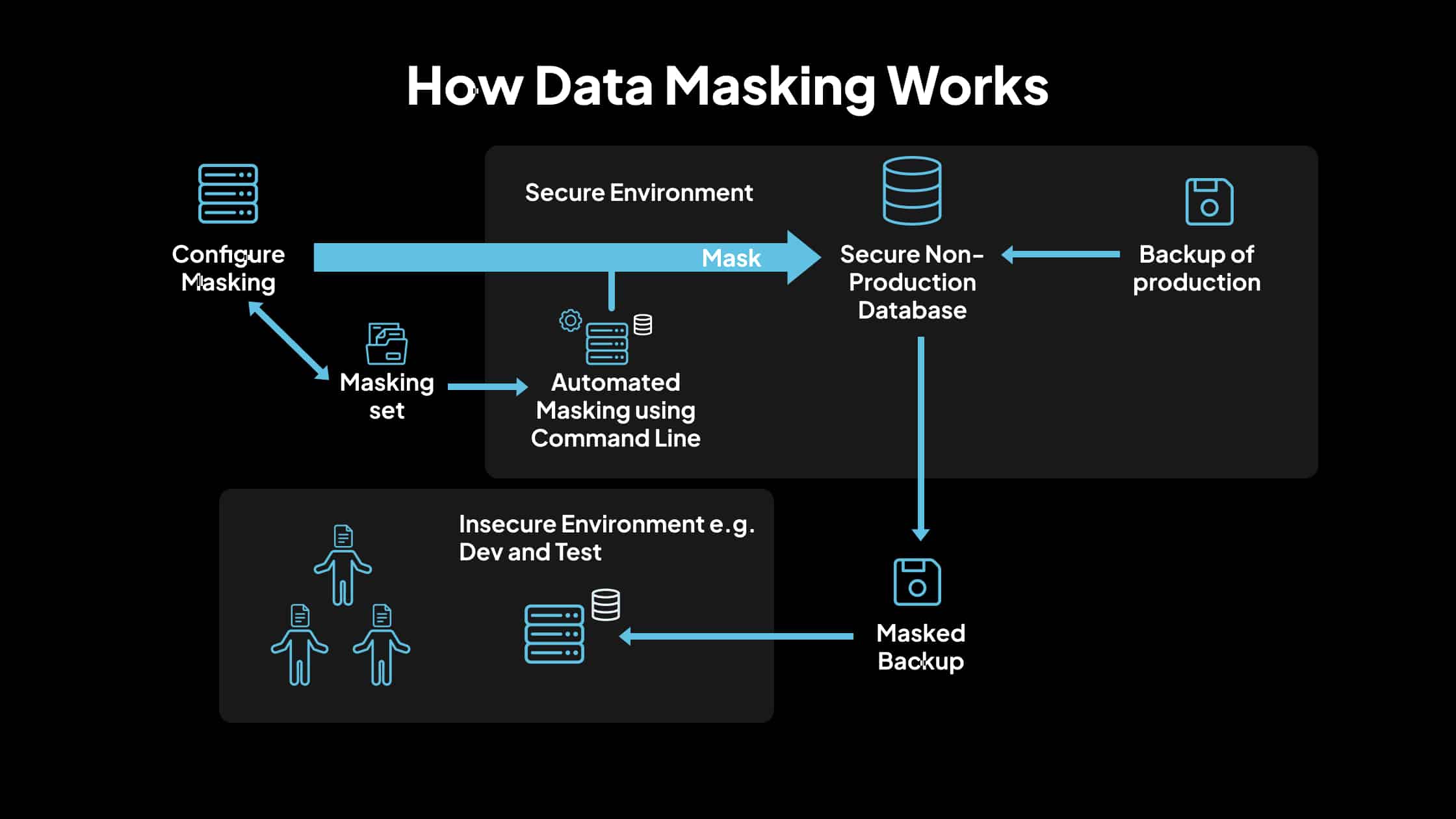
El enmascaramiento de datos es un método utilizado para proteger la información confidencial reemplazándola con datos ficticios pero realistas. Esto garantiza que las personas no autorizadas no puedan acceder a los datos reales, al tiempo que permite que los datos sean útiles para fines de prueba, desarrollo y capacitación. A continuación, se muestra una explicación detallada de cómo funciona el proceso de enmascaramiento de datos:
- Identificar y clasificar datos confidenciales
Comience realizando un inventario completo de sus activos de datos para identificar la información confidencial que requiere protección. Esto incluye información de identificación personal (PII), registros financieros, información de salud y otros datos confidenciales. Clasifique estos datos según los niveles de confidencialidad y los requisitos reglamentarios para determinar las técnicas de enmascaramiento adecuadas.
- Definir políticas y reglas de enmascaramiento:
Establezca políticas claras que describan qué elementos de datos necesitan enmascaramiento y las reglas específicas para transformarlos. Estas políticas deben alinearse con los estándares de seguridad de la organización y las obligaciones de cumplimiento.
Por ejemplo, reemplace los nombres reales con nombres ficticios u ofusque los números de tarjetas de crédito, excepto los últimos cuatro dígitos.
- Seleccionar técnicas de enmascaramiento apropiadas
Elija las técnicas de enmascaramiento que mejor se adapten a los tipos de datos y los casos de uso previstos. Las técnicas comunes incluyen:
- Sustitución: Reemplazar datos reales con datos ficticios realistas (por ejemplo, intercambiar nombres reales con nombres generados aleatoriamente).
- Mezcla: Reorganizar aleatoriamente los datos dentro de una columna para interrumpir el orden original.
- Variación de número y fecha: Alterar los valores numéricos o las fechas dentro de un rango especificado para ocultar las cifras exactas mientras se mantiene la utilidad de los datos.
- Enmascaramiento: Ocultar partes de datos con caracteres como asteriscos (por ejemplo, mostrar un número de tarjeta de crédito como **** **** **** 1234).
- Anulación: Reemplazar los datos con valores nulos elimina efectivamente la información del conjunto de datos.
- Redacción: Eliminar o tachar datos confidenciales por completo.
- Aplicar enmascaramiento a los datos
Implemente las técnicas de enmascaramiento seleccionadas en los datos identificados. Dependiendo de la complejidad y la escala de los datos, esto se puede hacer utilizando herramientas o scripts especializados de enmascaramiento de datos.
Asegúrese de que el proceso de enmascaramiento mantenga la integridad de los datos y que los datos enmascarados sigan siendo utilizables para los fines previstos.
- Probar y validar datos enmascarados
Después del enmascaramiento, pruebe minuciosamente los datos para confirmar que cumplen con los estándares de seguridad y usabilidad requeridos.
Verifique que los datos enmascarados no expongan correctamente información confidencial y funciones dentro de las aplicaciones y los sistemas. Este paso es crucial para garantizar que el proceso de enmascaramiento no haya introducido errores o inconsistencias.
- Implementar datos enmascarados en entornos de destino
Una vez validados, implemente los datos enmascarados en entornos que no son de producción, como plataformas de desarrollo, prueba o capacitación. Asegúrese de que existan controles de acceso para evitar el acceso no autorizado a los datos enmascarados y originales.
- Supervisar y mantener los procesos de enmascaramiento
Supervise continuamente la eficacia de los procesos de enmascaramiento de datos y actualícelos para abordar nuevos tipos de datos, cambios regulatorios o amenazas de seguridad en evolución. Las auditorías y revisiones periódicas ayudan a mantener el cumplimiento y los estándares de protección de datos.
Tokenización vs. Enmascaramiento de datos: comparación de características
A continuación, se muestra una comparación detallada característica por característica de la tokenización frente al enmascaramiento de datos para ayudarlo a comprender sus diferencias en funcionalidad y aplicación.
1. Reversibilidad
Tokenización
La tokenización es un proceso reversible. Cada token se asigna a sus datos originales mediante una bóveda de tokens segura. Solo los sistemas o usuarios autorizados con los permisos correctos pueden recuperar los datos originales accediendo a esta bóveda. Esto hace que la tokenización sea adecuada para casos de uso en los que los datos originales deben restaurarse para fines de procesamiento o informes.
Enmascaramiento
La mayoría de las técnicas de enmascaramiento de datos son irreversibles. Una vez que los datos se enmascaran, especialmente en el enmascaramiento estático, los valores originales se alteran u ofuscan permanentemente.
Esto hace que sea imposible recuperar los datos originales, lo cual es aceptable en entornos como las pruebas de software o el análisis, donde no se requieren datos reales.
2. Preservación del formato de datos
Tokenización
Los datos tokenizados conservan el mismo formato y estructura que los datos originales. Por ejemplo, un número de tarjeta de crédito de 16 dígitos sigue siendo un token de 16 dígitos, lo que facilita el mantenimiento de la compatibilidad con las aplicaciones, los esquemas de bases de datos y las interfaces de usuario existentes.
Esto permite a las organizaciones integrar la tokenización sin necesidad de rediseñar el sistema.
Enmascaramiento
Los datos enmascarados también preservan el formato, especialmente cuando se utilizan técnicas de enmascaramiento que preservan el formato. Sin embargo, dependiendo del método utilizado, se pueden introducir variaciones (por ejemplo, sustitución de caracteres frente a anulación).
Si bien la integridad estructural generalmente se mantiene, el contenido se altera para que no sea confidencial e inutilizable fuera del entorno previsto.
3. Nivel de seguridad
Tokenización
La tokenización proporciona un alto nivel de seguridad al reemplazar completamente los valores confidenciales con tokens no relacionados.
Estos tokens no tienen un valor explotable a menos que se combinen con la bóveda de tokens fuertemente protegida. Esto minimiza la exposición en caso de acceso no autorizado y no es susceptible a ataques criptográficos.
Enmascaramiento
El enmascaramiento de datos también mejora la seguridad al transformar los datos para ocultar el contenido confidencial. Sin embargo, debido a que a menudo utiliza métodos o patrones deterministas, los datos enmascarados pueden inferirse parcialmente si no se diseñan adecuadamente.
Su uso principal es en entornos con menor riesgo de exposición, pero aún necesita ser administrado (por ejemplo, desarrollo, análisis).
4. Soporte de cumplimiento
Tokenización
La tokenización admite el cumplimiento de las regulaciones de la industria como PCI DSS y GDPR al eliminar los datos confidenciales de los sistemas dentro del alcance.
Al almacenar solo tokens en la mayoría de los entornos y aislar los datos reales en una bóveda segura, las organizaciones pueden reducir significativamente la cantidad de sistemas sujetos a auditorías de cumplimiento y reducir los costos asociados.
Enmascaramiento
El enmascaramiento de datos se utiliza comúnmente para respaldar el cumplimiento de normativas como HIPAA, RGPD y las normas ISO, especialmente en la protección de la información de identificación personal (PII) o la información personal de salud (PHI) durante las operaciones internas. Es un método práctico para lograr la minimización de datos en entornos de análisis y pruebas.
5. Complejidad de la integración
Tokenización
La implementación de la tokenización requiere cambios en el flujo de datos, la infraestructura de bóveda segura y la lógica de tokenización de la aplicación.
Implica la configuración de controles de acceso, almacenamiento seguro y procesos de detokenización, lo que hace que la implementación sea más compleja, pero beneficiosa en entornos de alto riesgo.
Enmascaramiento
El enmascaramiento de datos generalmente tiene una menor complejidad de integración. Se puede aplicar a copias estáticas de datos o dinámicamente en la capa de aplicación con cambios mínimos en la infraestructura. Muchas soluciones de enmascaramiento se pueden integrar rápidamente en las canalizaciones de prueba o desarrollo, lo que ofrece una ruta de implementación más rápida.
Cuándo usar la tokenización frente al enmascaramiento: elegir el método de protección de datos adecuado
La elección entre la tokenización y el enmascaramiento depende de cómo y dónde se utilicen sus datos. Aquí le mostramos cómo elegir el método correcto en función de cómo utilice y proteja sus datos.
Cuándo usar la tokenización
Procesamiento de pagos y cumplimiento de PCI DSS
En el procesamiento de pagos, la tokenización es una herramienta fundamental para mejorar la seguridad y lograr el cumplimiento del Estándar de Seguridad de Datos para la Industria de Tarjetas de Pago (PCI DSS). Al reemplazar los datos confidenciales del titular de la tarjeta, como los números de cuenta principales (PAN), con tokens no confidenciales, las empresas pueden minimizar el almacenamiento de datos reales de la tarjeta dentro de sus sistemas.
Esto reduce el riesgo de filtraciones de datos y reduce el alcance de los requisitos de cumplimiento de PCI DSS, lo que podría reducir los costos y esfuerzos asociados.
Protección de datos sanitarios y cumplimiento de HIPAA
La protección de la información del paciente es primordial en la atención médica, y la tokenización sirve como un método eficaz para proteger los registros electrónicos de salud (EHR). Al sustituir los datos sanitarios confidenciales por tokens, los proveedores de atención médica pueden garantizar que la información del paciente siga siendo confidencial, en consonancia con las regulaciones de la Ley de Portabilidad y Responsabilidad del Seguro Médico (HIPAA).
Esta técnica permite el manejo seguro de los datos en diversas aplicaciones, incluida la facturación y la investigación, sin exponer los detalles del paciente.
Protección de datos confidenciales en el análisis
Las organizaciones a menudo necesitan analizar datos que contienen información confidencial. La tokenización permite el uso de dichos datos en el análisis al reemplazar los elementos confidenciales con tokens, preservando así la utilidad de los datos y manteniendo la privacidad.
Esto es beneficioso al analizar el comportamiento del cliente o realizar estudios de mercado, ya que permite la recopilación de información significativa sin comprometer la privacidad individual.
Almacenamiento de datos en la nube
Las organizaciones a menudo almacenan datos confidenciales en entornos de nube para análisis, servicio al cliente o fines operativos. La tokenización les permite almacenar y procesar datos sin revelar identidades reales o información confidencial a los proveedores de servicios en la nube.
Esto es particularmente valioso cuando se trabaja con plataformas de terceros, ya que limita la exposición de los datos originales y garantiza el cumplimiento de las regulaciones de privacidad en varias jurisdicciones.
Aplicaciones de pago móvil
En las billeteras móviles y las aplicaciones de pago (por ejemplo, Apple Pay, Google Pay), la tokenización protege los datos del titular de la tarjeta durante las transacciones. En lugar de transmitir el número de tarjeta real, se utiliza un token.
Este token es único por transacción o por dispositivo, lo que hace que sea mucho más difícil para los atacantes interceptar y reutilizar los datos de pago. Permite transacciones seguras y sin contacto sin exponer la información financiera original.
Cuándo elegir el enmascaramiento de datos
Entornos de desarrollo y prueba
El acceso a datos realistas es esencial para obtener resultados precisos en el desarrollo y las pruebas de software. Sin embargo, el uso de datos confidenciales reales plantea riesgos de seguridad.
El enmascaramiento de datos aborda este desafío ofuscando la información confidencial y creando conjuntos de datos que imitan los datos reales, protegiendo así los detalles confidenciales. Esta práctica garantiza que los desarrolladores y evaluadores puedan trabajar eficazmente sin comprometer la seguridad de los datos.
Fines de capacitación y educativos
La capacitación del personal o la educación de los estudiantes a menudo requiere acceso a datos que reflejen escenarios del mundo real. El enmascaramiento de datos permite a las organizaciones divulgar datos sin revelar información confidencial. Los alumnos pueden aprender y practicar utilizando conjuntos de datos realistas enmascarando los identificadores personales y los detalles confidenciales, lo que garantiza el cumplimiento de las regulaciones de privacidad y el mantenimiento de la confidencialidad de los datos.
Intercambio seguro de datos con terceros
Al compartir datos con socios externos, como proveedores o investigadores, la protección de la información confidencial es crucial. El enmascaramiento de datos facilita el intercambio seguro de datos al anonimizar los detalles confidenciales, preservando al mismo tiempo la estructura y la usabilidad de los datos.
Esto permite a las organizaciones colaborar eficazmente sin arriesgarse a filtraciones de datos o violar las leyes de privacidad.
Enmascaramiento de datos para desarrolladores y analistas
El acceso a los datos de producción a menudo es necesario para la depuración, el desarrollo de funciones o el análisis estadístico en el desarrollo de software y el análisis de datos. Sin embargo, la exposición de datos confidenciales en tales entornos aumenta el riesgo de fuga o uso indebido accidental.
El enmascaramiento de datos permite a los desarrolladores y analistas trabajar con datos realistas manteniendo la confidencialidad. Garantiza la coherencia en las relaciones de datos (por ejemplo, transacciones de clientes, saldos de cuentas) al tiempo que oculta la información de identificación personal (PII).
Agilización del acceso seguro con la herramienta inteligente de enmascaramiento de datos de Avahi
Como parte de su compromiso con las operaciones de datos seguras y conformes, la plataforma de IA de Avahi proporciona herramientas que permiten a las organizaciones gestionar la información confidencial de forma precisa y exacta. Una de sus características más destacadas es Data Masker, diseñado para proteger los datos financieros y de identificación personal, a la vez que respalda la eficiencia operativa.
Descripción general del Data Masker de Avahi
El Data Masker de Avahi es una herramienta versátil de protección de datos diseñada para ayudar a las organizaciones a gestionar de forma segura la información confidencial en diversas industrias, incluyendo la atención sanitaria, las finanzas, el comercio minorista y los seguros.
La herramienta permite a los equipos enmascarar datos confidenciales como números de cuenta, registros de pacientes, identificadores personales y detalles de transacciones sin interrumpir los flujos de trabajo operativos.
El Data Masker de Avahi garantiza que solo los usuarios autorizados puedan ver o interactuar con datos confidenciales aplicando técnicas avanzadas de enmascaramiento y aplicando el control de acceso basado en roles. Esto es especialmente importante cuando varios departamentos o proveedores externos acceden a los datos.
Ya sea protegiendo la información de salud del paciente en cumplimiento con HIPAA, anonimizando los registros financieros para PCI DSS o asegurando los datos del cliente para GDPR, la herramienta ayuda a las organizaciones a minimizar el riesgo de acceso no autorizado al tiempo que preserva la usabilidad de los datos para fines de desarrollo, análisis y supervisión del fraude.
Cómo funciona la función de enmascaramiento de datos
El proceso de enmascaramiento de información confidencial utilizando el Data Masker de Avahi es intuitivo y está impulsado por la IA:
1. Cargar archivo
Los usuarios comienzan cargando el conjunto de datos o el archivo que contiene información confidencial a través de la plataforma Avahi.
2. Vista previa de los datos
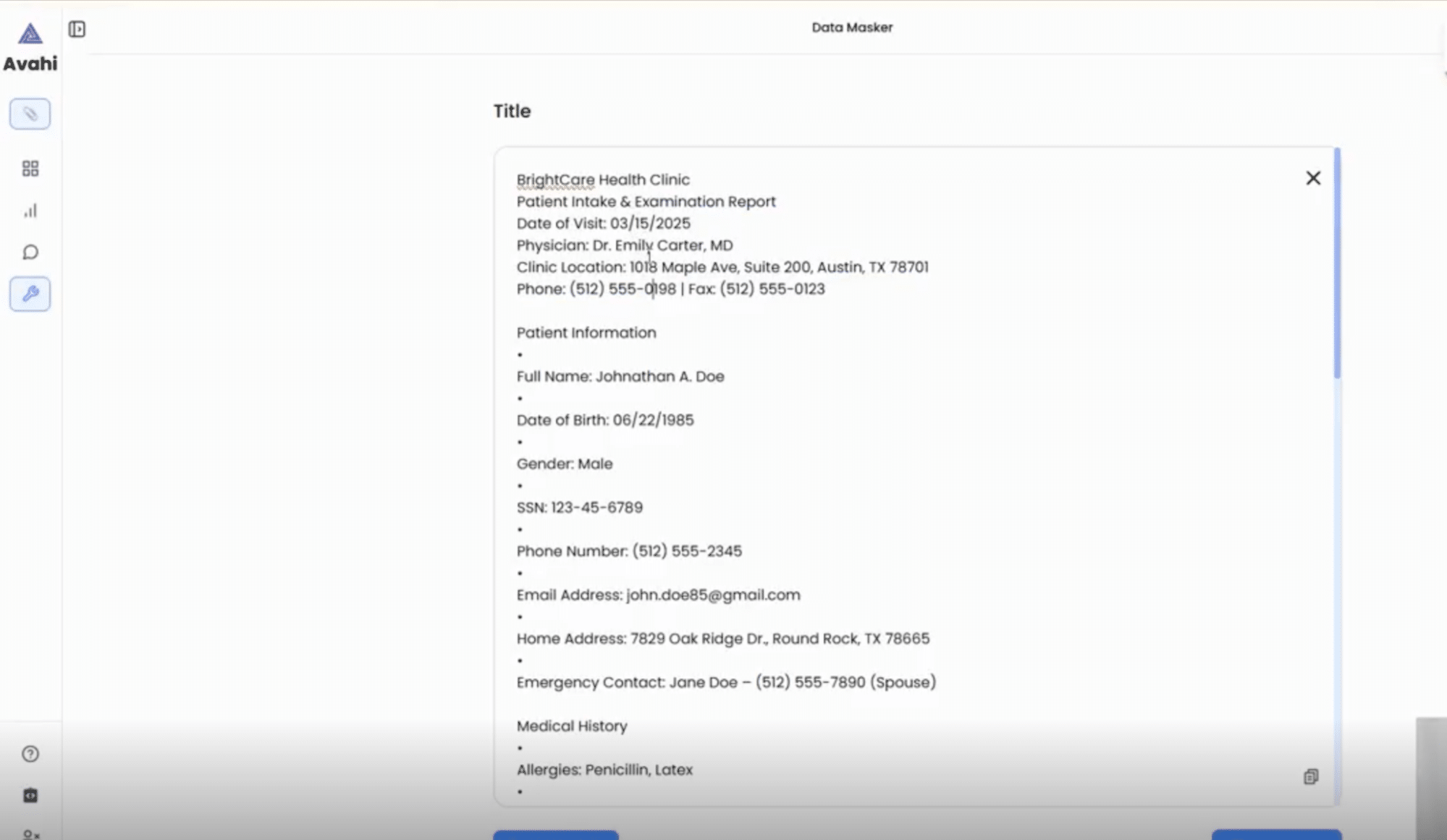
Una vez cargada, la herramienta muestra el contenido estructurado, resaltando los campos que normalmente se consideran confidenciales (por ejemplo, PAN, nombres, fechas de nacimiento).
3. Haga clic en la opción ‘Enmascarar datos’
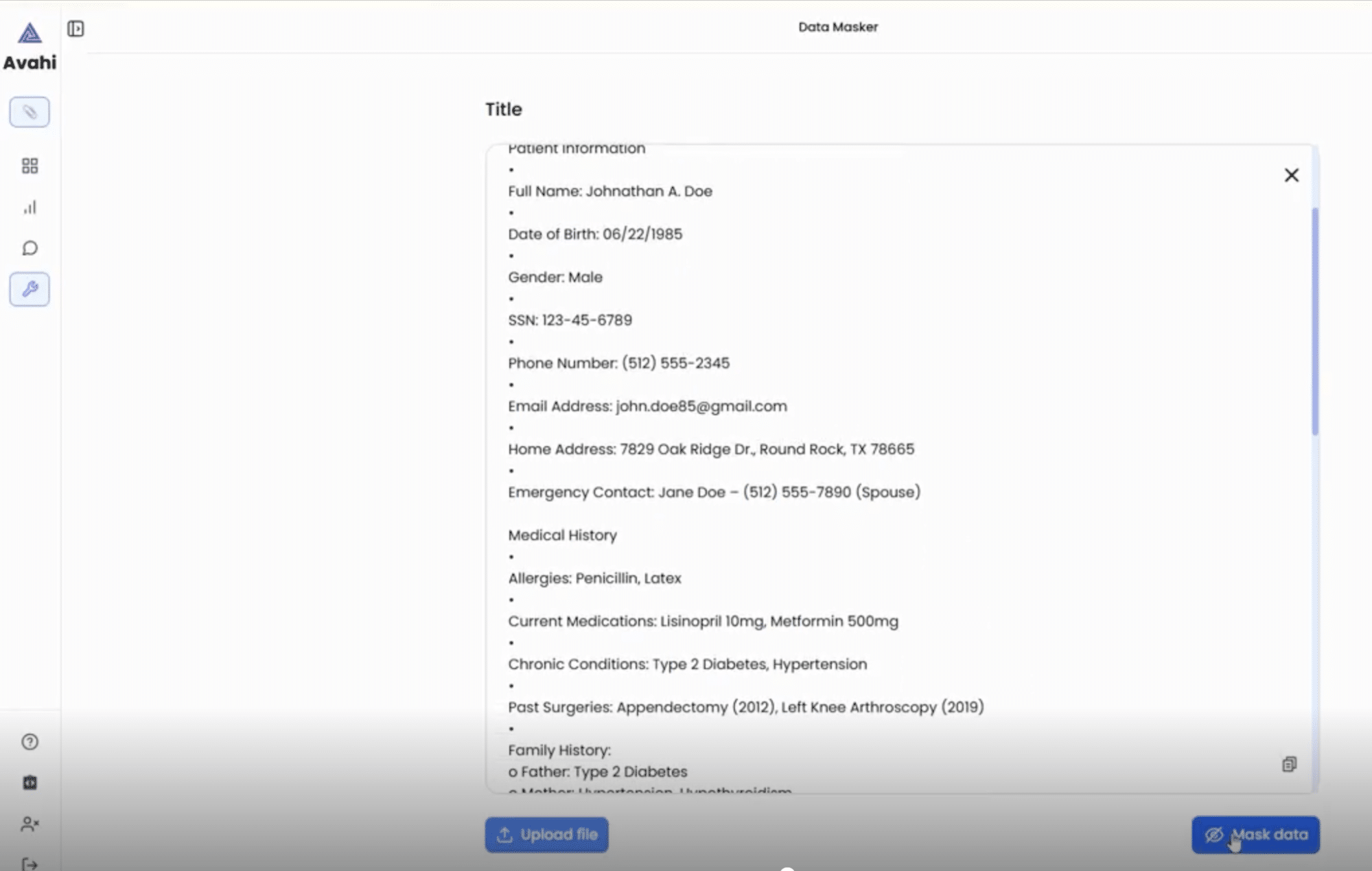
A continuación, los usuarios inician el proceso de enmascaramiento seleccionando la opción ‘Enmascarar datos’ de la interfaz.
4. Transformación impulsada por la IA
Entre bastidores, Avahi utiliza algoritmos inteligentes y reglas predefinidas para identificar y enmascarar los valores de datos confidenciales. Esta transformación garantiza que los datos enmascarados mantengan su formato y usabilidad, pero no contengan la información original.
5. Salida segura
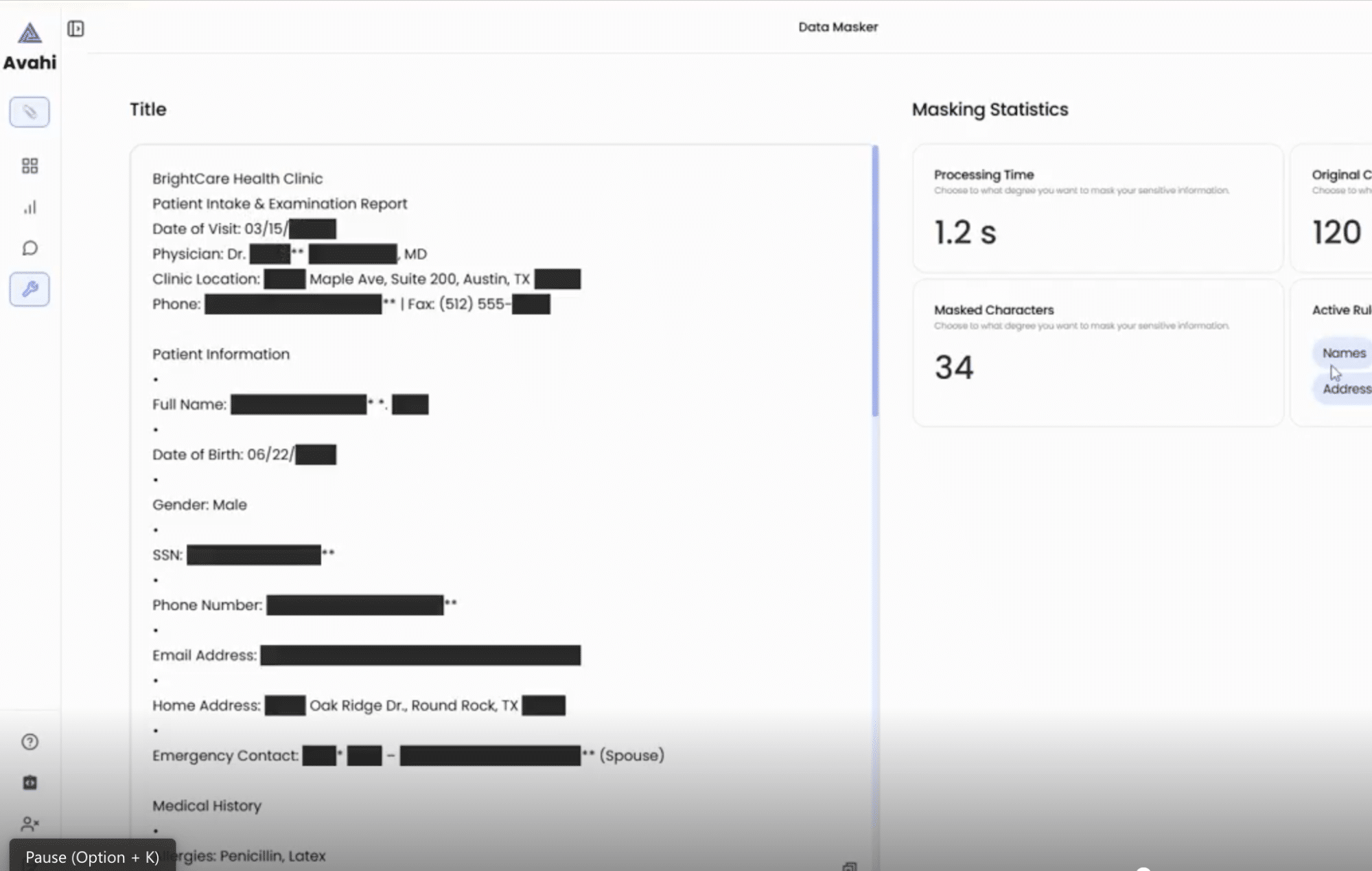
El archivo resultante muestra valores ofuscados en lugar del contenido confidencial original, que se puede utilizar de forma segura para el análisis de fraude, la elaboración de informes o la colaboración con terceros.
El Data Masker de Avahi integra la automatización, los controles fáciles de usar y el enmascaramiento seguro impulsado por la IA para garantizar el cumplimiento normativo (por ejemplo, PCI DSS) al tiempo que minimiza la fricción operativa.
Simplifique la protección de datos con la solución de enmascaramiento de datos impulsada por la IA de Avahi

En Avahi, reconocemos la importancia crucial de proteger la información confidencial, a la vez que mantenemos flujos de trabajo operativos perfectos.
Con el Data Masker de Avahi, su organización puede proteger fácilmente los datos confidenciales, desde la atención sanitaria hasta las finanzas, al tiempo que mantiene el cumplimiento normativo con estándares como HIPAA, PCI DSS y GDPR.
Nuestra solución de enmascaramiento de datos combina técnicas avanzadas impulsadas por la IA con el control de acceso basado en roles para mantener sus datos seguros y utilizables para el desarrollo, el análisis y la detección de fraudes.
Ya sea que necesite anonimizar registros de pacientes, transacciones financieras o identificadores personales, el Data Masker de Avahi ofrece un enfoque intuitivo y seguro para la protección de datos.
¿Listo para asegurar sus datos al tiempo que garantiza el cumplimiento? ¡Comience con el Data Masker de Avahi!
Programar una llamada de demostración
Preguntas frecuentes (FAQ)
1. ¿Cuál es la diferencia entre la tokenización y el enmascaramiento en la seguridad de los datos?
La principal diferencia entre la tokenización y el enmascaramiento radica en su reversibilidad y en los casos de uso específicos para los que se aplican. La tokenización reemplaza los datos confidenciales con tokens no confidenciales y almacena de forma segura los datos originales, lo que la hace ideal para los sistemas transaccionales. Por el contrario, el enmascaramiento de datos altera los datos para evitar la reversibilidad, lo que lo hace adecuado para entornos que no son de producción, como el desarrollo o las pruebas.
2. ¿Cuándo debe utilizar la tokenización frente al enmascaramiento para proteger los datos?
Cuándo utilizar la tokenización frente al enmascaramiento depende de su entorno. Utilice la tokenización para los sistemas de producción en vivo, especialmente donde se requiere el cumplimiento de PCI. Utilice el enmascaramiento en áreas que no son de producción, como el desarrollo, el control de calidad o la capacitación, para trabajar con datos realistas pero anonimizados de forma segura.
3. ¿Cómo se comparan la tokenización y el enmascaramiento con otras técnicas de seguridad de datos?
En una comparación de técnicas de seguridad de datos, la tokenización y el enmascaramiento destacan por proteger los datos confidenciales en reposo o en uso. Si bien el cifrado protege los datos matemáticamente, la tokenización y el enmascaramiento reducen la exposición al riesgo al reemplazar u ofuscar los elementos confidenciales, especialmente en los análisis, el almacenamiento y los entornos de terceros.
4. ¿Puede la tokenización admitir el cumplimiento del RGPD para proteger los datos de los clientes?
Sí, las técnicas de tokenización del RGPD ayudan a proteger los datos personales al reemplazar los identificadores con tokens sin sentido, lo que reduce el riesgo de exposición. Minimiza el almacenamiento de información de identificación personal (PII) y limita el impacto potencial en caso de una filtración de datos.
5. ¿Cómo ayuda el enmascaramiento de datos a los desarrolladores y analistas en entornos seguros?
El enmascaramiento de datos para desarrolladores y analistas garantiza que los equipos puedan trabajar con conjuntos de datos realistas sin exponer información confidencial. Mantiene las relaciones y la estructura de los datos al tiempo que elimina los datos identificables, lo que es especialmente útil en las soluciones de enmascaramiento de datos HIPAA y los entornos de prueba.



