TL;DR
|
El sector de la atención médica y las ciencias biológicas ha experimentado una transformación digital masiva en la última década, lo que ha llevado a una vasta recopilación de datos. Para encontrar valor en estos datos y adoptar modelos de aprendizaje automático, las organizaciones deben abordar desafíos como la normalización, la disponibilidad, la integridad y la gobernanza de los datos. La información médica está muy distribuida, es contextual e incluye principalmente datos no estructurados, como formularios de admisión, notas clínicas, radiografías, tomografías computarizadas, recetas manuscritas, reclamaciones de seguros, etc.
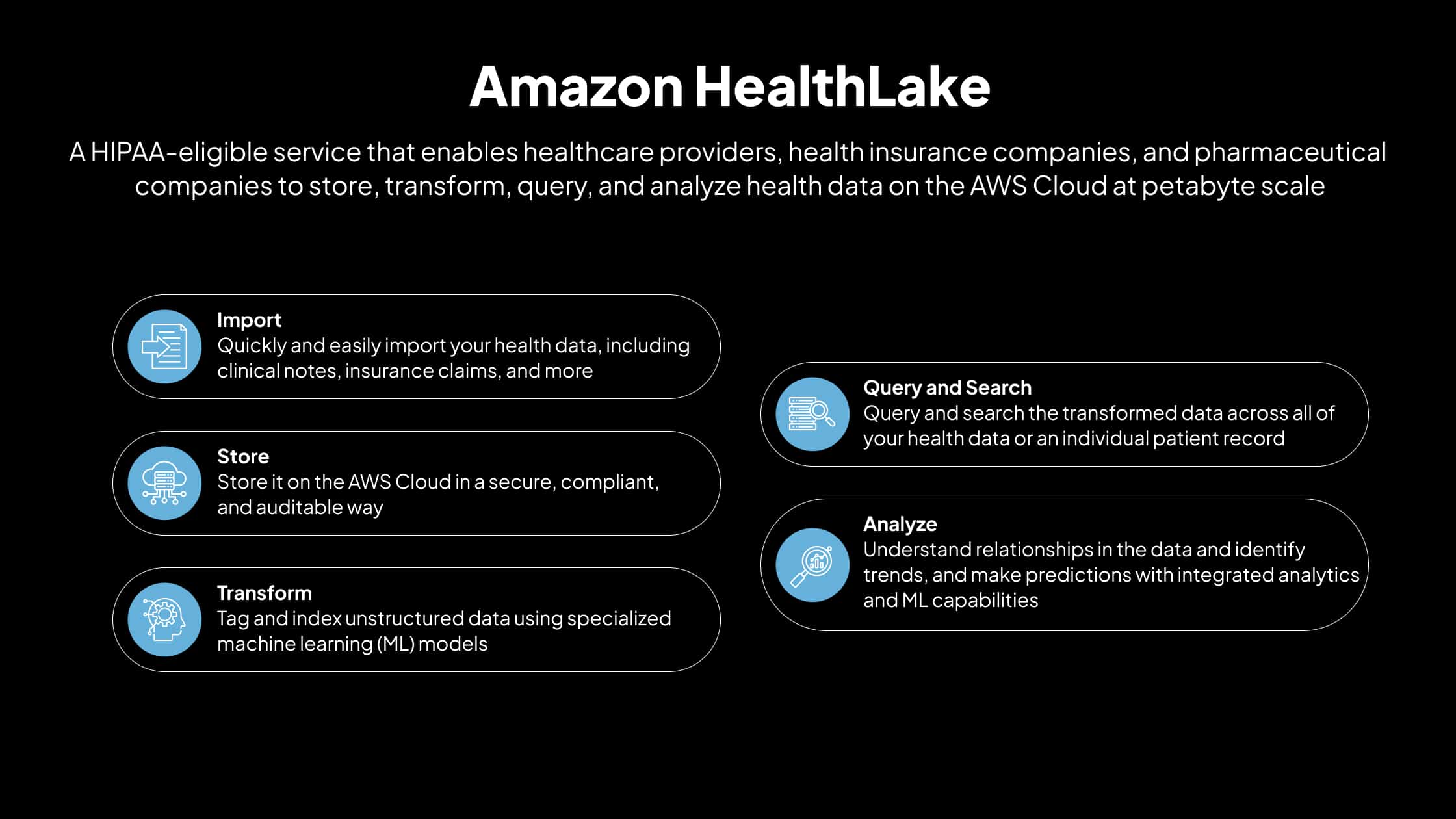
Amazon lanzó un nuevo servicio en re:invent 2020 para abordar el creciente problema de la gestión de datos relacionados con la salud en la nube. El servicio, denominado Amazon HealthLake, es un servicio totalmente gestionado y apto para HIPAA que permite a las empresas de atención médica y ciencias biológicas almacenar, transfo rmar, consultar y analizar datos de salud en la nube de AWS a escala de petabytes. Para evaluar estas capacidades sin riesgos, muchas organizaciones inician una prueba de concepto de AWS dirigida. Este piloto permite a los equipos importar de forma segura datos estructurados y no estructurados de sistemas locales y aprovechar modelos de aprendizaje automático preconstruidos para normalizar, indexar y etiquetar fechas clave, descriptores médicos o diagnósticos antes de comprometerse con un despliegue completo.
Las empresas pueden agregar toda su información de salud dispar, en varios estilos y formatos, en un lago de datos centralizado aprovisionado y gestionado por Amazon HealthLake. Este enfoque centralizado permite a los usuarios buscar, analizar y consultar toda su información de salud rápidamente a través de una única interfaz.
Amazon HealthLake se encarga de configurar varias fuentes de datos, ingiere los datos, indexa toda la información para que se pueda buscar más adelante y la almacena en formatos estándar abiertos, como el formato exigido por FHIR. Procesa los datos de texto no estructurados mediante PNL y las imágenes mediante modelos de ML como la clasificación binaria, la clasificación multiclase o la regresión. Una vez que los datos se han convertido en información estructurada y centralizada, se obtiene una visión completa del historial de un paciente individual a un nivel de granularidad en el que se pueden aplicar análisis avanzados o modelos de aprendizaje automático para la predicción.