

TL;DR
|
Every organization that handles sensitive data faces a simple reality: one weak link in data security can result in massive financial, legal, and reputational damage. In 2024 alone, businesses worldwide incurred an average breach cost of $4.45 million, with personal and financial data being among the most frequently targeted types of data.
What’s even more concerning is that many of these breaches didn’t occur in production systems; they happened because sensitive data was exposed in non-production environments, such as development, testing, or analytics.
This makes one thing clear: protecting sensitive data at every stage of its lifecycle is no longer just about compliance, it’s about safeguarding your business from real, measurable risk.
By applying the correct data masking techniques, you can ensure that even if data is accessed without authorization, it remains useless to attackers while still serving business needs.
In this blog, you’ll discover six practical data masking best practices that can help your organization reduce exposure, strengthen security, and confidently meet regulatory requirements.
The Importance of Data Masking: Why It Matters for Your Organization
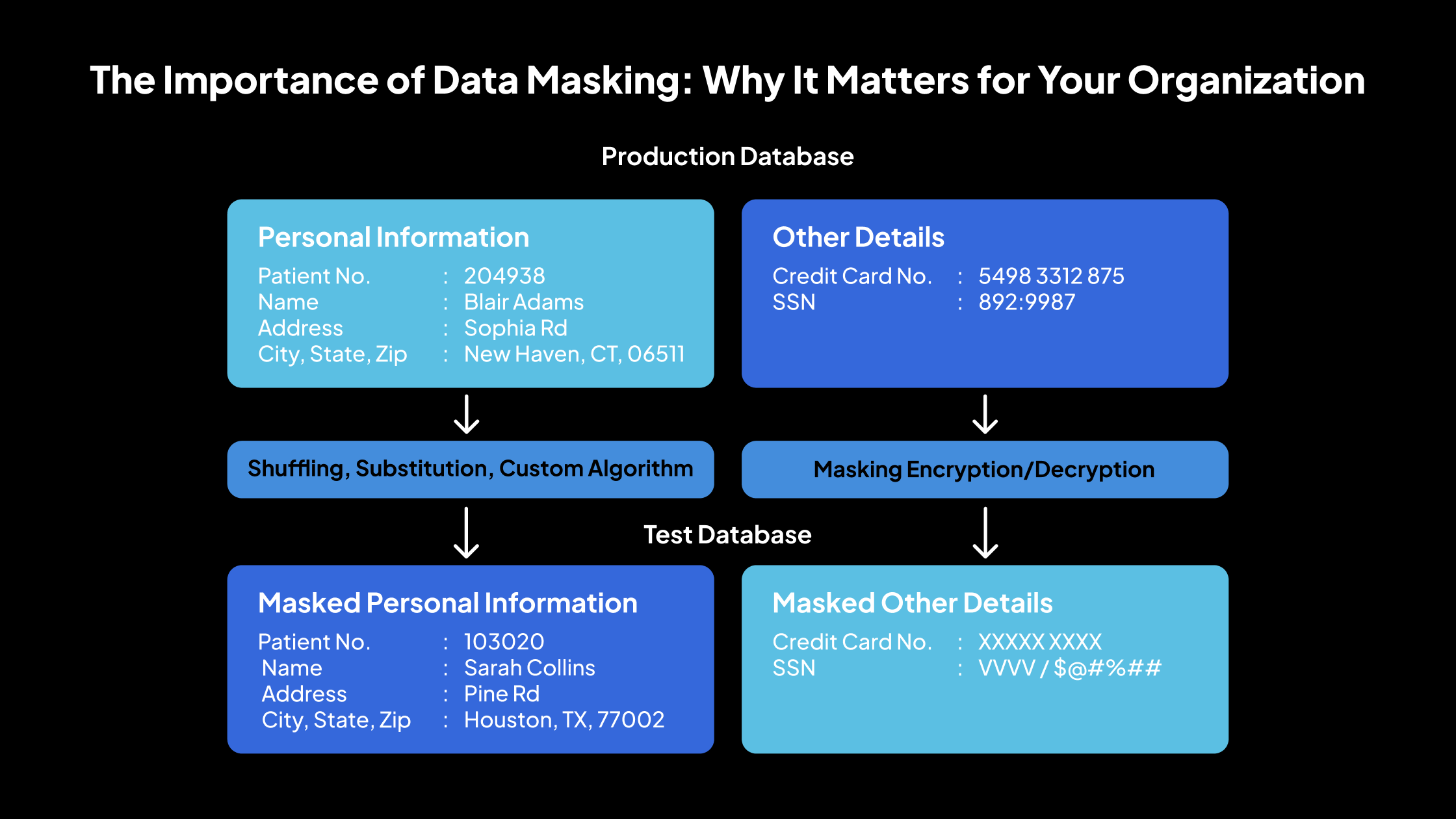
Data masking is a method of replacing sensitive information with realistic but fake data. It is primarily used to protect confidential details while maintaining the data’s usability for non-production activities, such as software testing, training, or demonstrations.
The masked data retains the same format as the original, but its values are altered so that they cannot be traced back or reversed to reveal the actual information. Standard masking techniques include shuffling characters, substituting words or numbers, and using encryption. Here is why data masking is essential:
Protects Against Data Breaches
Data masking helps protect organizations from threats such as data loss, unauthorized access, and insider misuse. By masking sensitive details, even if data is exposed during an attack, it remains unusable to cybercriminals. Masking reduces the risk of this financial impact by making data meaningless to attackers.
Cloud Security
Many organizations are moving their data to cloud environments. Data masking reduces the risks associated with storing sensitive information in the cloud by ensuring that exposed or mishandled data cannot compromise the organization. This is especially important as 85% of businesses now operate in multi-cloud environments.
Safe Data Sharing
Masked data allows businesses to share information with authorized users, such as developers, testers, or analysts, without revealing actual customer or business details. This ensures compliance with privacy standards while supporting development and innovation.
Regulatory Compliance
Data masking supports compliance with data protection regulations, such as GDPR, HIPAA, and CCPA. These laws require organizations to secure personal and sensitive data. Masking is an effective way to meet these legal obligations during activities like testing and analytics.
Better Data Sanitization
Simple file deletion often leaves behind traces of data that can be recovered. Masking provides an extra layer of protection by overwriting original values with fake data, making recovery and misuse of deleted data much harder.
-
Data Utility for Testing and Training
Masked data retains the same structure and format as the original, allowing it to be used in software testing, user training, or demo environments without exposing sensitive information. This ensures realistic scenarios without risking data leaks.
6 Data Masking Best Practices for Compliance and Security

Below are six essential data masking best practices that help protect sensitive data, support compliance, and strengthen your organization’s security posture.
1. Conduct Comprehensive Data Discovery and Classification
A strong data masking strategy begins with identifying exactly what data requires protection and where it is stored. Without this foundation, masking efforts may overlook critical data or apply unnecessary masking, resulting in risks and inefficiencies.
Identify Sensitive Data
The first step is to locate and understand all sensitive data that your organization handles. This includes:
| Personally Identifiable Information (PII) | Protected Health Information (PHI) | Financial Data |
| Data that can identify an individual, such as names, addresses, phone numbers, social security numbers, and passport numbers. | Health records, diagnoses, treatment details, and insurance information are covered under regulations such as HIPAA. | Credit card numbers, bank account details, transaction histories, and tax records. |
Sensitive data may be stored in structured formats (e.g., databases, data warehouses) or unstructured formats (e.g., documents, emails, spreadsheets). It is essential to map all locations where this data resides, including on-premise systems, cloud environments, and third-party platforms.
Failing to identify hidden or forgotten data repositories is a significant security risk. A 2023 Ponemon Institute study found that 67% of organizations had sensitive data in locations they were unaware of, increasing exposure to breaches.
Utilize Automated Tools
Given the scale and complexity of modern IT environments, manual data discovery is inefficient and prone to errors. Organizations should adopt automated data discovery and classification tools that utilize technologies like:
- Pattern matching (e.g., detecting formats of credit card numbers or social security numbers)
- Machine learning and AI models to recognize data types across various systems
- Metadata scanning to assess file properties and database schemas
These tools can scan large volumes of data, identify sensitive elements, and classify them accurately in real-time or on a scheduled basis. Additionally, automation helps maintain an up-to-date inventory of sensitive data as systems evolve, data expands, and new sources are introduced.
Examples of widely used data discovery tools, such as Microsoft Purview, help integrate with data masking tools, thereby reducing both the time and risk associated with manual processes.
Establish Data Taxonomy
Once data is identified, it must be classified according to sensitivity level, regulatory requirement, and business use case. This is known as building a data taxonomy. A well-defined taxonomy helps determine:
- What data requires masking or encryption?
- Which masking techniques should be applied?
- Who can access masked or unmasked data?
- Which regulations apply to each data category?
A taxonomy might include categories such as:
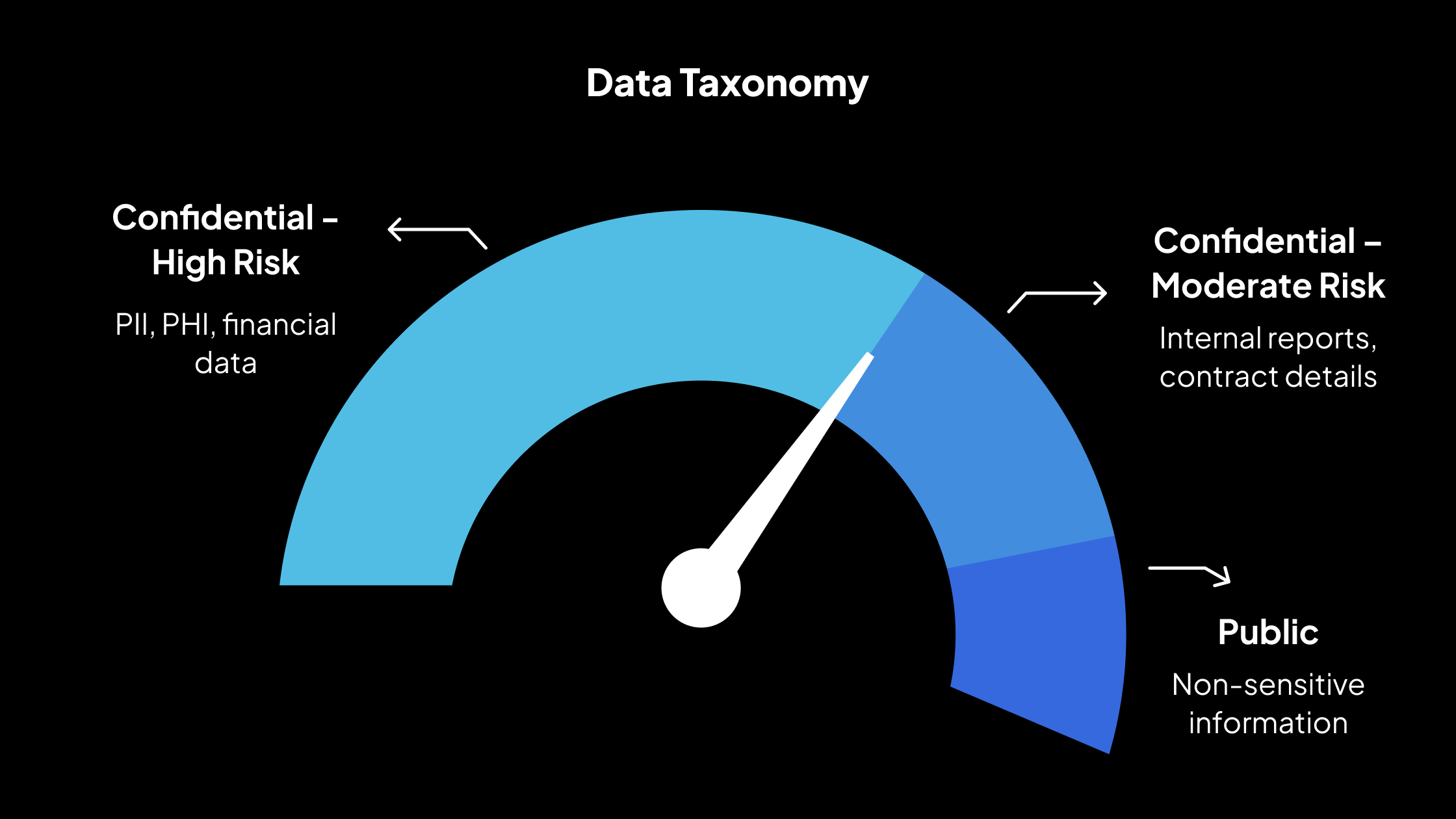
- Confidential – High Risk: PII, PHI, financial data (must always be masked in non-production environments)
- Confidential – Moderate Risk: Internal reports, contract details (masking depends on use case)
- Public: Non-sensitive information (no masking required)
Establishing and maintaining this taxonomy ensures consistency across the organization and simplifies regulatory reporting and audits. It also enables precise, risk-based application of data masking, reducing both operational overhead and unnecessary data obfuscation.
2. Choose Appropriate Data Masking Techniques
Selecting the correct data masking technique is crucial for striking a balance between security, compliance, and usability. The choice depends on the data type, the purpose of masking, and the environment in which the masked data will be used.
Static vs. Dynamic Data Masking
Static Data Masking (SDM)
Static data masking involves creating a masked copy of a database or data set. The masking process is performed once on the original data, and the resulting data set is then used in non-production environments (e.g., development, testing, training).
The masked data is persistent and stored separately from the original data. SDM ensures that sensitive data is never exposed in these settings because the original data never leaves production systems.
Dynamic Data Masking (DDM)
Dynamic data masking applies masking on the fly, at query runtime. The original data stays intact in the database, but users see masked values based on their access rights. Masking rules are applied in real-time, ensuring sensitive data is protected without the need for separate datasets.
It is used in production systems where certain users (e.g., support teams, contractors) require restricted views, as well as in customer service portals where partial data visibility is necessary. DDM offers flexibility and reduces storage overhead, but requires careful configuration of access control.
Masking Methods
Substitution
Substitution replaces sensitive values with realistic, but fake, values from a pre-defined dataset. For example, replacing real names with names from a sample list. It is used for PII masking (names, addresses) and is suitable for testing and demo environments where realistic data is required.
Shuffling
Shuffling randomizes data within a column. For example, customer emails might be shuffled so that no record retains its original email. It is used for internal testing where format matters, but exact value relationships do not, and scenarios where data consistency across rows is not critical.
Encryption
Encryption transforms data into an unreadable format using cryptographic algorithms. Only authorized users with decryption keys can access the original data.
It is used for protecting sensitive data in transit or at rest, as well as in high-security environments where data must be encrypted for specific users.
Tokenization
Tokenization replaces sensitive data with a unique, randomly generated value (token). The relationship between the original data and the token is maintained in a secure token vault.
It is used for payment processing (e.g., replacing credit card numbers with tokens)
And in systems requiring traceability between original and masked data
Preserve Data Integrity
It is essential that data masking does not break applications or processes that rely on the data. Referential integrity ensures that relationships between data elements (e.g., foreign key constraints in databases) remain intact after masking.
Here are some essential considerations
- Consistent masking: The same original value should always map to the same masked value where necessary (e.g., customer IDs across tables).
- Format preservation: Masked data should retain the format of the original data (e.g., date formats, string lengths) to prevent errors in applications that use it.
- Business logic compatibility: Masking should not interfere with system logic, reporting, or analytics.
Failing to preserve integrity can lead to test failures, incorrect results, or broken systems in non-production environments.
3. Implement Role-Based Access Controls (RBAC)
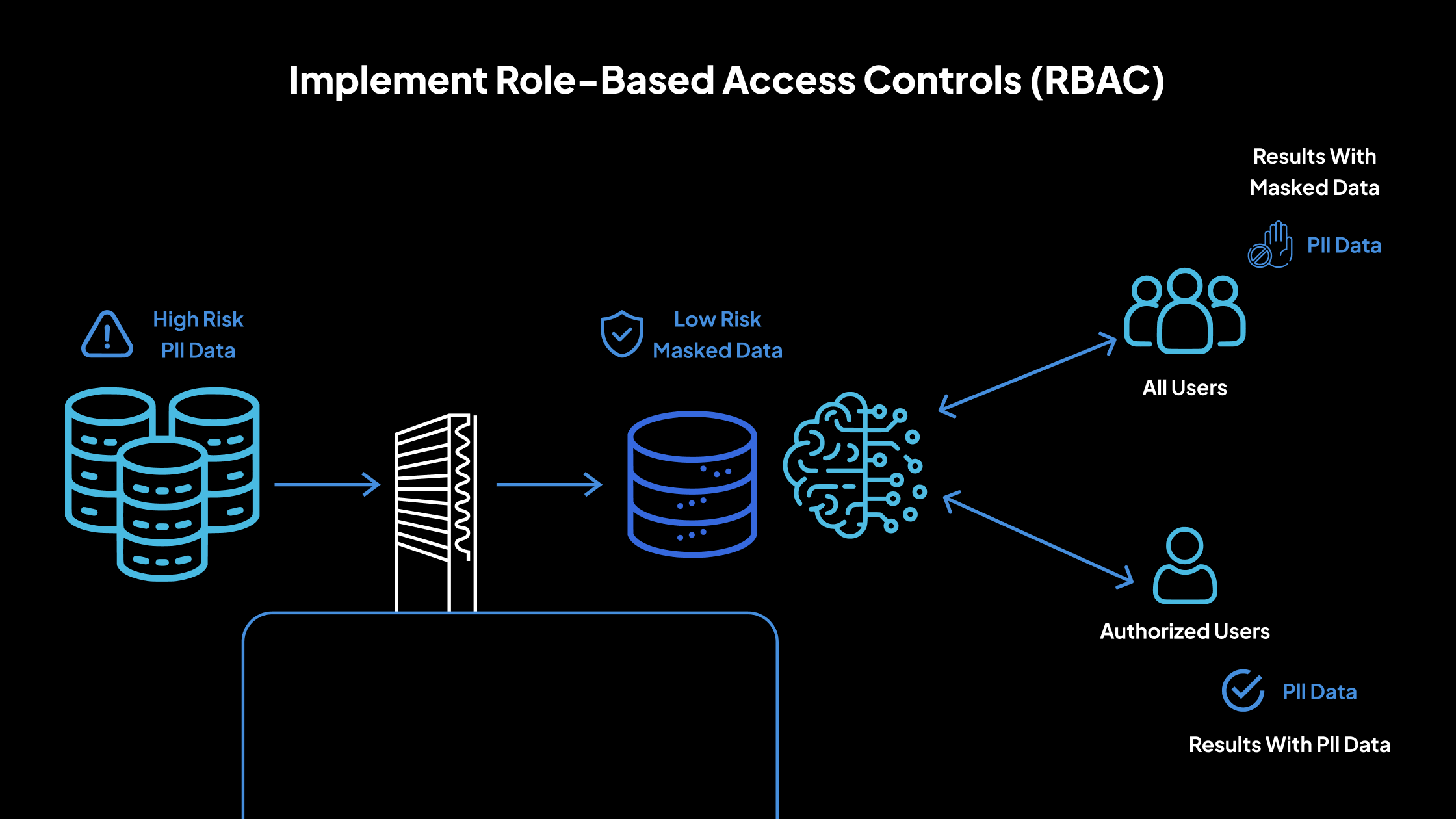
Role-Based Access Control (RBAC) is a security mechanism that helps ensure sensitive data is only accessible to authorized individuals. By assigning permissions based on job roles, organizations can reduce the risk of unauthorized data exposure and maintain compliance with data protection regulations.
Define User Roles
The first step in RBAC is to define user roles within the organization clearly. Each role should reflect specific job functions and responsibilities. For example:
| Database Administrator | Developer | Data Analyst |
| Requires access to manage and maintain databases, including masked and unmasked data. | Needs access to masked data for testing, but no access to production or unmasked data. | Can work with aggregated or anonymized data, with no access to identifiable personal data. |
Roles should be mapped to access rights based on the principle of least privilege; users are granted only the permissions necessary to perform their duties. This reduces the risk of accidental or intentional misuse of sensitive data.
Restrict Access to Sensitive Data
Once roles are defined, it is crucial to enforce access restrictions. Sensitive data, such as personally identifiable information (PII) or protected health information (PHI), should only be visible in unmasked form to individuals with a legitimate business need.
For example, developers working in non-production environments should only interact with data that is masked or anonymized. Customer service teams may see partial data (e.g., the last four digits of a credit card) rather than complete data sets.
These restrictions help protect data from insider threats and accidental exposure while supporting business operations. Modern databases and applications often provide built-in support for role-based permissions, making it easier to enforce these controls.
Monitor and Audit Access
RBAC should be supported by continuous monitoring and auditing to ensure that access policies are adhered to and to identify any anomalies. This involves logging all data access activities, including queries run against sensitive data, changes to masking rules, and modifications to permissions.
Regularly reviewing audit logs helps identify unauthorized access attempts or suspicious patterns, and generating reports for compliance purposes demonstrates to regulators that data access is controlled and monitored.
Automated monitoring tools can provide real-time alerts when access policies are violated, enabling swift action to contain potential risks.
4. Regularly Audit and Update Masking Policies
Data masking is not a one-time activity. As business environments, data systems, and regulatory requirements evolve, masking policies must be reviewed and updated to ensure continued effectiveness. A systematic approach to auditing and updating these policies helps organizations reduce risk and maintain compliance.
Adapt to Changes
Masking policies must be flexible enough to adjust when key elements of the business or technical environment change.
Examples of such changes include modifications to data structures, such as new fields added to a database or schema changes in a data warehouse, updates in business processes that introduce new data flows or change how sensitive data is handled and new or revised data privacy regulations (e.g., updates to GDPR, CCPA, or the introduction of new regional laws).
If masking rules do not account for these changes, sensitive data could be left exposed. Therefore, organizations should have a formal process for updating masking policies whenever systems or compliance requirements change. This process should involve collaboration between data governance, compliance, and IT teams to ensure all angles are covered.
Conduct Periodic Reviews
Organizations should conduct regular audits to verify that their masking policies and controls are functioning as intended. These reviews should verify that all sensitive data is masked adequately across all environments, including production replicas, backups, and testing systems.
Checking for policy drift, where masking rules may no longer align with current business or regulatory needs, and testing masking effectiveness, ensuring that masked data cannot be reverse-engineered or re-identified.
An audit cycle might be quarterly or semi-annual, depending on the sensitivity of the data and regulatory requirements. Audit results should be documented and shared with stakeholders, including compliance and security teams.
Incorporate Feedback Loops
Audit findings should feed directly into the process of improving masking practices. This feedback loop ensures that weaknesses identified during audits lead to actionable improvements in masking techniques or policies, new risks are addressed promptly, preventing data exposure before issues escalate, and masking strategies remain aligned with business objectives and regulatory standards.
Incorporating feedback helps create a cycle of continuous improvement. Masking policies should not remain static; they must evolve based on internal findings and external changes to ensure data security and compliance.
5. Integrate Data Masking into the Development Lifecycle
To build secure and compliant systems, data masking should be integrated at every stage of the software development lifecycle (SDLC). This ensures that sensitive data is protected not only in production but also in non-production environments where data is often at higher risk due to broader access and fewer controls.
Secure Non-Production Environments
Development, testing, and training environments often require realistic data to simulate production conditions. However, using actual production data in these environments creates a significant security risk. Non-production systems often have lower security controls, broader access by third parties or contractors, and a higher risk of accidental data leakage.
Always apply data masking to sensitive data before copying or moving it into non-production environments. Masking techniques should ensure that the data retains its structure and referential integrity so that testing and development activities are not disrupted.
This protects personally identifiable information (PII), protected health information (PHI), and financial data from unnecessary exposure while allowing teams to work with realistic datasets.
Automate Masking Processes
Manual data masking is time-consuming, error-prone, and challenging to scale in modern development environments, particularly those employing agile or DevOps practices. To address this, organizations should integrate automated data masking tools into their CI/CD pipelines.
Automation ensures masking is consistently applied whenever data is refreshed in non-production environments, reduces human error, and enforces compliance with masking policies.
Automated masking solutions can be configured to run as part of build, deployment, or data refresh processes. This guarantees that no unmasked data enters test or development systems, supporting secure-by-design principles.
Educate Development Teams
Technology alone is not enough. Development and testing teams must understand the importance of data masking and its role in secure software practices. Without proper awareness, teams might bypass masking controls or unintentionally expose sensitive data.
Explain the risks associated with using real production data in non-production environments. Guide secure coding practices that align with data masking requirements. Teach how to work with masked data during debugging, testing, and analysis without compromising security.
Regular workshops, documentation, and integration of data security topics into development onboarding programs help build a culture of security awareness.
6. Ensure Compliance with Data Protection Regulations
Data masking plays a crucial role in helping organizations comply with data protection laws. To achieve and maintain compliance, it is essential to align masking practices with legal standards, document these efforts, and continuously monitor regulatory changes.
Understand Regulatory Requirements
Different data protection laws specify how organizations should handle and protect sensitive information. It is essential to understand the obligations related to data masking under these regulations:
- GDPR (General Data Protection Regulation) — Requires data controllers and processors to implement appropriate technical measures, such as pseudonymization and data masking, to protect personal data (Article 32). Masking supports GDPR principles by minimizing the exposure of identifiable information in non-production environments or during data sharing.
- HIPAA (Health Insurance Portability and Accountability Act) — Mandates the safeguarding of protected health information (PHI). Masking helps meet HIPAA’s Privacy and Security Rule requirements by de-identifying PHI when used outside of clinical systems.
- CCPA (California Consumer Privacy Act) — Emphasizes consumer rights over personal information. Data masking reduces the risk of unauthorized disclosure, supporting compliance with the CCPA’s data security provisions.
Understanding these legal requirements helps determine where and how masking should be applied, ensuring that masking strategies are designed to meet specific compliance needs.
Document Compliance Efforts
To demonstrate compliance during audits or regulatory reviews, it is essential to maintain clear and accurate records of data masking activities. This includes masking policy documents that describe which data elements are masked, the techniques used, and the reasons for masking.
Process records showing how masking is applied during data migrations, environment refreshes, or data sharing activities. Access logs detailing who applied or modified masking rules, along with the dates and times of these changes. Proper documentation not only supports audit readiness but also helps internal teams review and improve masking practices over time.
Stay Informed on Legal Updates
Data privacy regulations continue to evolve as governments introduce new laws and update existing ones. For example, the expansion of U.S. state-level privacy laws (such as the Colorado Privacy Act) has added new compliance obligations.
Organizations must stay updated on these changes to ensure that masking practices remain compliant. This can be achieved through regular legal reviews in collaboration with compliance or legal teams, monitoring updates from official regulatory bodies and privacy advocacy groups, and adjusting masking policies and tools as needed to align with new requirements.
Staying proactive reduces the risk of non-compliance and ensures that data protection measures remain effective as laws change.
Protect Sensitive Information with Avahi’s Intelligent Data Masking Tool
As part of its commitment to secure and compliant data operations, Avahi’s AI platform provides tools that enable organizations to manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Overview of Avahi’s Data Masker
Avahi’s Data Masker is a versatile data protection tool designed to help organizations securely handle sensitive information across various industries, including healthcare, finance, retail, and insurance.
The tool enables teams to mask confidential data such as account numbers, patient records, personal identifiers, and transaction details without disrupting operational workflows.
Avahi’s Data Masker ensures only authorized users can view or interact with sensitive data by applying advanced masking techniques and enforcing role-based access control. This is especially important when multiple departments or external vendors access data.
Whether protecting patient health information in compliance with HIPAA, anonymizing financial records for PCI DSS, or securing customer data for GDPR, the tool helps organizations minimize the risk of unauthorized access while preserving data usability for development, analytics, and fraud monitoring purposes.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution

At Avahi, we recognize the crucial importance of safeguarding sensitive information while maintaining seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions
1) What are the data masking best practices that organizations should follow?
Data masking best practices encompass conducting comprehensive data discovery, selecting the appropriate masking techniques, implementing role-based access controls, regularly auditing masking policies, integrating masking into the development lifecycle, and ensuring compliance with data protection regulations. These practices help protect sensitive information while supporting operational and compliance needs.
2) Why is data masking necessary for compliance and security?
Data masking is crucial because it prevents unauthorized access to sensitive data, reduces the risk of data breaches, and ensures compliance with regulations such as GDPR, HIPAA, and CCPA. It allows organizations to work with realistic data in non-production environments without exposing actual confidential information.
3) What’s the difference between static and dynamic data masking?
Static data masking creates a masked copy of a dataset used in non-production environments, such as development or testing. Dynamic data masking masks data at query runtime, displaying masked values to unauthorized users while preserving the original data in production systems.
4) How does data masking support cloud security?
Data masking supports cloud security by ensuring that sensitive data stored or processed in the cloud is obfuscated. Even if cloud data is mishandled or exposed, masked data is useless to attackers. This is crucial as most organizations now rely on multi-cloud environments.
5) Does data masking affect data utility for testing and analytics?
No. When done correctly, data masking preserves the format and structure of the original data. This allows teams to perform realistic testing, training, and analysis without exposing sensitive information.



