

Sensitive data is often most vulnerable where it’s least expected: in your development and testing environments.
While organizations invest heavily in securing production systems, copies of real data often flow freely into staging databases, analytics tools, and third-party platforms without adequate protection. The result? Preventable exposure.
A 2023 report by Gartner revealed that over 40% of data breaches involve non-production environments, where real data is used for operations like software testing, AI model training, or reporting. Additionally, IBM’s Cost of a Data Breach Report highlights that the average breach now costs $4.9 million, with regulatory penalties and reputational damage escalating the impact.
To close these gaps, security teams must move beyond perimeter defenses and adopt data masking techniques and strategies that conceal sensitive information while keeping it usable for internal workflows.
Data masking enables organizations to obscure confidential information while maintaining its usability across systems. Whether it’s customer records, financial data, or health information, masking ensures the data remains functional for internal use, without risking exposure.
This blog explores seven proven data masking techniques every security team should know. We explain how each method works, where it fits best, and how it strengthens your organization’s data protection framework. Whether you’re navigating GDPR, HIPAA, or simply looking to close internal security gaps, these techniques offer practical and scalable solutions.
Understanding Data Masking: How It Differs from Encryption & Anonymization
Data masking is a data protection method that hides sensitive information by replacing it with fictitious but realistic-looking data. This ensures that the underlying data is shielded from unauthorized access while retaining its usability for non-production purposes.
The primary goal is to prevent exposure of confidential data, such as personally identifiable information (PII), financial records, or health data, during software development, testing, analytics, and training processes.
This technique helps organizations maintain operational workflows without compromising data security. Unlike deletion or restriction, data masking allows data to remain functional and usable by systems or personnel without revealing absolute values.
Developers and QA teams often need data that behaves like real user information. Masked data provides a secure alternative without exposing actual user records. Analysts can work with masked datasets to derive insights and trends without accessing sensitive information, thus reducing compliance risks.
When third-party vendors or offshore teams require access to databases, data masking ensures sensitive information is not disclosed. Regulations such as GDPR, HIPAA, and CCPA mandate strict personal and health data controls. Masking helps organizations meet these legal obligations by safeguarding customer information from exposure in non-secure environments.
How Data Masking Differs from Encryption and Anonymization
Encryption transforms data using cryptographic algorithms into unreadable formats that can only be decoded with a specific key. While encryption is suitable for secure storage and transmission, it does not allow practical use of the data in non-production environments without decrypting it.
In contrast, data masking permanently replaces the original data with a masked version, making it useful for development or training without needing access to the original values.
Anonymization removes identifiable elements from data, making it impossible to link the information to an individual. However, anonymized data often lacks realism and consistency, especially in testing or analytics. On the other hand, data masking maintains the data’s format, structure, and interdependencies, ensuring it behaves like real data while being protected.
Why is Data Masking Critical for Security Teams?
In today’s data-driven organizations, sensitive information often flows through multiple departments, platforms, and third-party services. Security teams must ensure this data remains protected, especially outside production environments. Here is why data masking becomes essential for security teams:
1. Risks of Exposing Production Data to Non-Production Environments
Many organizations use copies of live production data for development, testing, training, or analytics. However, these environments are usually less secure and more accessible to internal staff or vendors.
Exposing real data in such settings increases the risk of accidental leaks, misuse, or unauthorized access. Without proper data masking, sensitive customer data like names, addresses, and financial records can be exposed to unnecessary risk.
2. Compliance Requirements (e.g., GDPR, CCPA, HIPAA)
Global data privacy regulations require businesses to protect personal and sensitive data across all systems, not just in production.
- GDPR (EU) mandates data minimization and pseudonymization for personal data used in testing or analytics.
- CCPA (California) holds companies accountable for how consumer data is accessed, even internally.
- HIPAA (USA) requires the security of protected health information (PHI) at all stages, including when used by healthcare developers or analysts.
Data masking helps meet these requirements by ensuring that non-production environments don’t expose identifiable information, reducing the risk of non-compliance and fines. For instance, GDPR non-compliance can lead to penalties of up to €20 million or 4% of global turnover, whichever is higher.
3. Real-World Data Breaches Due to Poor Masking Practices
Failure to mask data properly has led to several high-profile data breaches. A 2022 Verizon report found that 61% of internal data breaches were due to poor handling of sensitive data in development and staging environments. Another case involved a healthcare provider that faced a $1.5 million HIPAA fine for allowing contractors to access patient data in a test database.
These incidents highlight the importance of masking data before it’s used in less secure or temporary environments. A proactive approach strengthens security and builds trust with customers and regulators.
Data Masking Algorithms: How Sensitive Information Is Transformed Securely
Data masking algorithms are logic-based rules or methods for transforming sensitive data into masked values. These algorithms ensure the masked data retains its structure and format while removing any direct link to the original data. Common types of data masking algorithms include:

These algorithms are selected based on the data type, the level of protection required, and the intended use of the masked dataset. Choosing the right algorithm ensures both security and operational usability.
Exploring the Data Masking Process: Stages and Functions
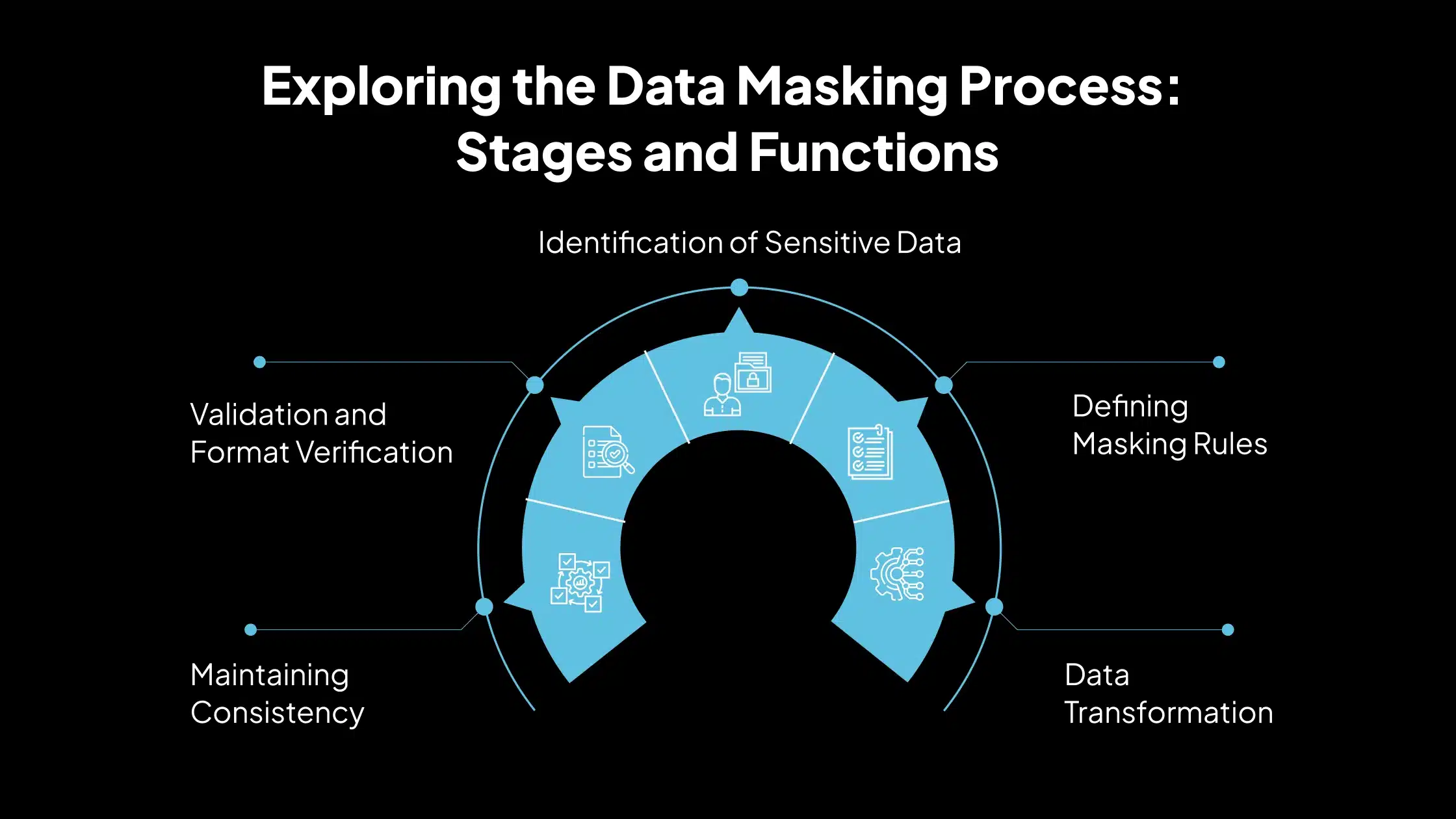
Data masking protects sensitive information by replacing it with fictitious, yet structurally similar, values. The masking process follows a systematic workflow involving several essential steps:
1. Identification of Sensitive Data
The first step is to scan and identify data that needs to be protected. This includes personally identifiable information (PII), financial details, health records, and other regulated or confidential data. Classification tools or manual reviews are often used to locate sensitive fields across databases, spreadsheets, or applications.
2. Defining Masking Rules
Once the sensitive data is identified, specific masking rules are created. These rules define how each type of data should be transformed. For example, names may be replaced with random characters, while credit card numbers might be partially hidden or substituted with a fixed format.
3. Data Transformation
In this phase, the original data is altered according to the defined rules. Various masking techniques, such as substitution, shuffling, encryption, or tokenization, replace the real values while maintaining the original data types and formats. This step ensures the masked data looks realistic and can be processed by systems without errors.
4. Maintaining Consistency
To ensure data integrity across systems, the same sensitive value must always be masked in the same way. This step ensures referential consistency, especially when the same data appears in multiple tables or databases. For instance, if an email address is masked in one system, it should be masked identically wherever it occurs.
5. Validation and Format Verification
After transformation, the masked data is validated to confirm that it adheres to format requirements and business logic. This step checks for data structure, length constraints, and field dependencies to ensure that the dataset remains functional and does not break application workflows.
Types of Data Masking: Choosing the Right Approach for Your Data
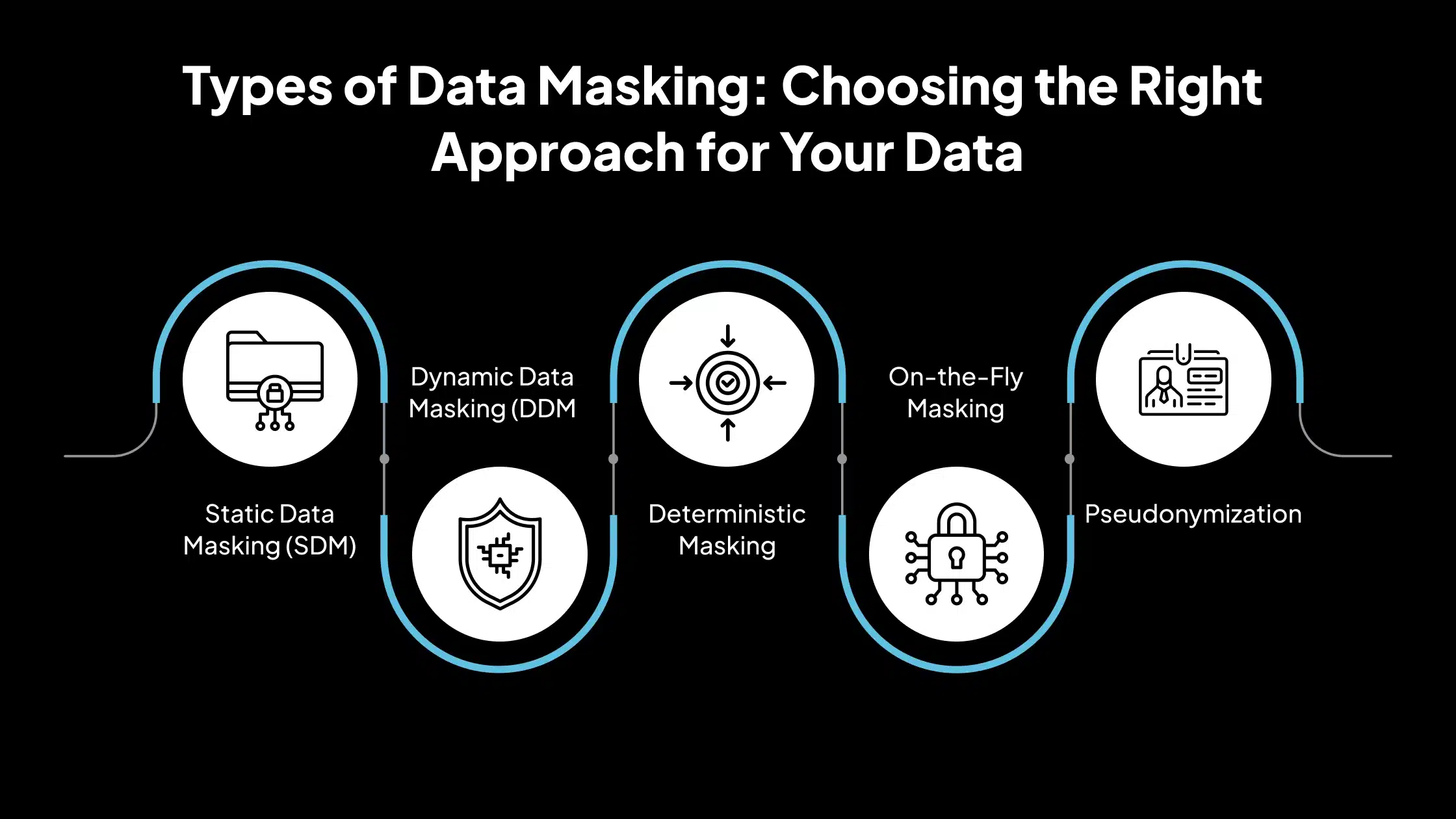
Data masking can be implemented differently depending on the use case, security goals, and technical environment. Below are the essential types of data masking used by security and compliance teams, each explained with practical relevance:
1. Static Data Masking (SDM)
Static Data Masking involves creating a masked database copy where sensitive values are replaced before being moved to non-production environments. The original production data is extracted, masked according to defined rules, and stored in a new dataset.
For example, a development team uses a masked clone of the customer database to build and test new features without exposing real personal data. This data masking type is ideal for software development, testing, training, and sharing with third parties.
2. Dynamic Data Masking (DDM)
Dynamic Data Masking applies masking rules in real-time as queries are executed. The original data stays unchanged in the database, but users with restricted access see masked values when retrieving data.
For instance, a customer service agent running a query on a customer table sees masked credit card numbers, while an admin sees the full value. This is helpful in production environments where limited data visibility is needed without altering the stored data.
3. Deterministic Masking
In deterministic masking, the same input always produces the same masked output. This ensures consistency across multiple tables or systems where referential integrity is required.
For example, the name “Alice Smith” is always masked as “Max Doe” across databases. This is necessary when the same data appears in multiple places and consistent relationships must be maintained, e.g., in relational databases.
4. On-the-Fly Masking
This type of masking happens during data transfer between systems. Sensitive data is masked as it moves from a production environment to a development or testing environment, with no temporary storage of unmasked data.
Data is masked in transit as it is pulled from production and sent to a developer’s environment.
This is suitable for automated workflows and continuous integration pipelines where real-time data masking is required during migration.
5. Pseudonymization
Pseudonymization replaces personal identifiers with pseudonyms that are consistent but unlinkable to the original data without additional information stored separately. Unlike traditional masking, it allows partial reversibility under strict control.
For example, a patient’s real name can be replaced with a coded ID like “User12345,” with the mapping stored in a secure vault. This is common in healthcare and research, where data analysis is needed without revealing identities while allowing for future re-identification under controlled conditions.
Top 7 Data Masking Techniques Every Security Team Must Implement
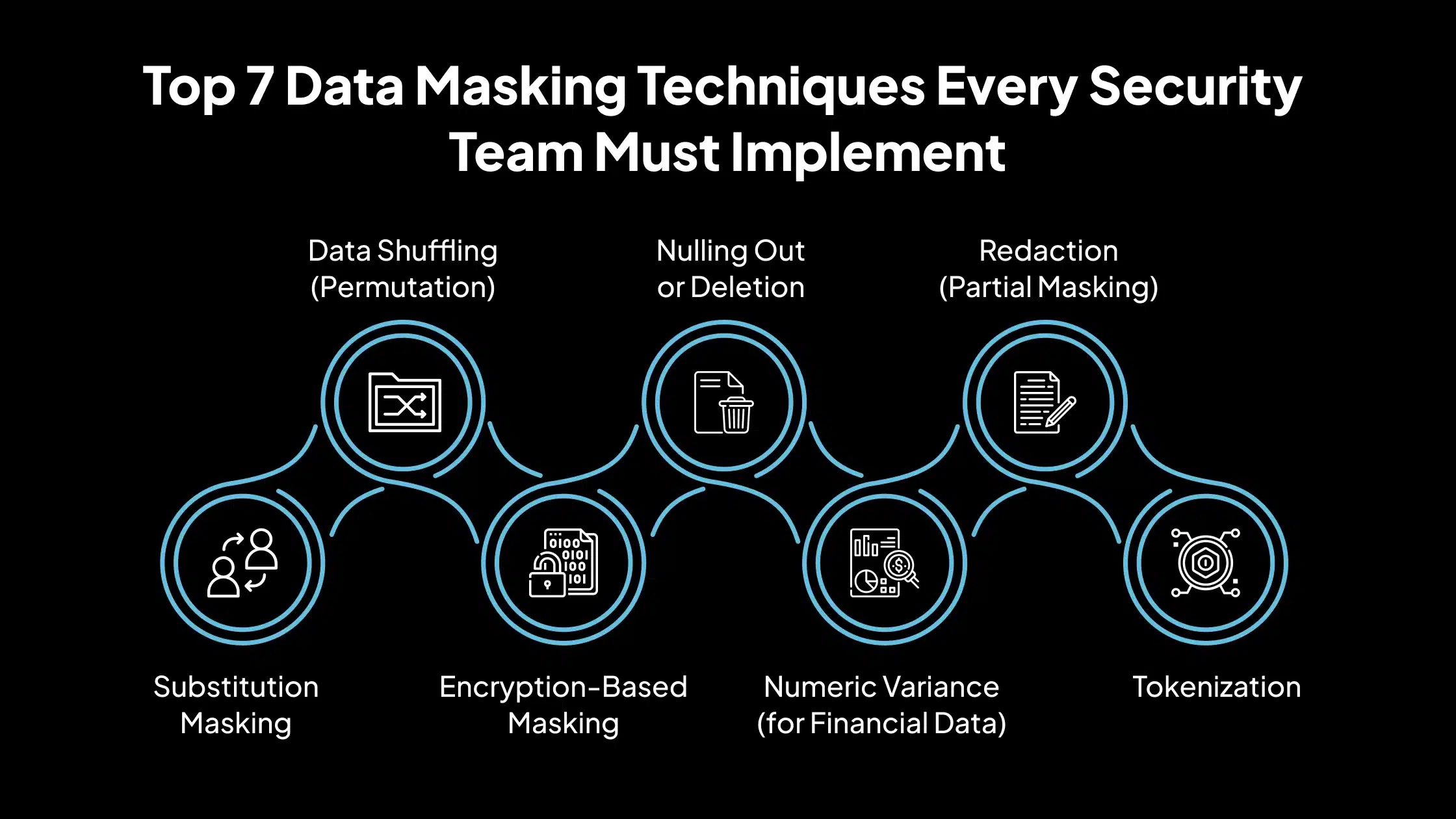
Data masking is not a one-size-fits-all solution; different scenarios require different methods to protect sensitive data without losing usability. Below are seven proven data masking techniques that security teams can apply to safeguard confidential information across development, testing, analytics, and operational environments.
Substitution Masking
Substitution masking replaces original sensitive data with realistic-looking fake values drawn from predefined lookup tables or generated dynamically. The data format remains consistent with the original.
Each original value is substituted with a randomly selected value from a predefined list. For example, actual employee names can be replaced with names from a synthetic dataset. The substituted data mimics the original’s structure, type, and format.
Ideal Use Cases
Substitution masking is well-suited for masking personally identifiable information such as names, email addresses, or physical addresses in CRM platforms. It ensures that real user details are never exposed during internal testing or third-party access.
This technique is particularly effective in test environments that require data to behave like real user inputs. It enables developers and QA teams to simulate user interactions without compromising data privacy. Substitution masking is also valuable in product demos or training sessions, where realistic employee or customer data is needed to showcase workflows without revealing genuine records.
Security Strengths
Substitution masking significantly reduces the risk of reverse engineering or unauthorized data reconstruction by ensuring the masked values are not directly linked to the originals.
It supports high usability, allowing applications and user interfaces to function as expected without encountering format or validation errors due to altered data. Unlike encryption, it doesn’t require key management, making it easier to implement while providing strong protection in non-production environments.
Data Shuffling (Permutation)
Shuffling reorders existing values within a column so that the data appears legitimate but no longer aligns with its original record. Values from a single column (e.g., social security numbers) are randomly shuffled among the rows. This ensures no value is in its original position while maintaining a valid data format.
Ideal Use Cases
Data shuffling is ideal for masking internal identifiers or contact numbers in reports where the actual values are unnecessary but the data format must be preserved. It allows reports to remain structurally accurate without exposing real information.
This technique works well for training datasets where maintaining the overall value distribution is essential for realistic model behavior, even though exact data points are randomized.
It is also suitable for scenarios where maintaining internal consistency between records isn’t essential, such as basic analytics or reporting tasks where relational integrity is not a priority.
Security Strengths
Data shuffling is straightforward, making it a practical choice for quick masking needs without extensive configuration. It retains the original data types and statistical characteristics, ensuring that outputs remain valid for most processing and reporting functions.
Reordering values without directly mapping to the source effectively severs identifiable links between the masked and original data, reducing exposure risks.
Encryption-Based Masking
This method uses encryption algorithms to convert original values into unreadable ciphertext, protecting the data from unauthorized access.
Standard cryptographic algorithms like AES or RSA are applied to transform the data. Only users with the correct decryption key can access the original values. Depending on the configuration, masking can be reversible or irreversible.
Ideal Use Cases
Encryption-based masking is ideal for securely transmitting sensitive data across different systems or environments, ensuring it remains protected during transfer.
It is commonly used to store highly sensitive fields such as passwords, account numbers, or financial records that must remain confidential and accessible only under controlled conditions.
This is also practical in systems that require reversible masking, allowing authorized users to decrypt and view the original data when necessary.
Security Strengths
Encryption offers high protection using well-established cryptographic algorithms, making it extremely difficult for unauthorized parties to decipher the masked data. It is particularly suitable for environments that enforce strict access control policies, where only select users or services can decrypt sensitive information.
Additionally, encryption helps organizations comply with regulatory requirements related to data at rest and in transit, such as those outlined in PCI DSS, HIPAA, and GDPR.
Nulling Out or Deletion
This technique replaces sensitive values with NULLs or deletes them entirely from the dataset, removing any identifiable traces. In more aggressive scenarios, entire rows or columns may be removed if they pose a privacy risk.
Ideal Use Cases
Nulling out or deleting data is effective for exporting datasets to third parties when sensitive information is not needed for their tasks. It ensures that only non-sensitive fields are shared, minimizing exposure.
This technique is also suitable for historical records where personal data is no longer relevant or required, helping organizations clean up legacy systems without retaining unnecessary risk.
It aligns well with compliance efforts focused on data minimization or disposal, especially when regulations mandate the permanent removal of specific categories of personal data.
Security Strengths
This method ensures that no private information remains in the dataset by completely removing or nullifying sensitive data. It reduces the risk of re-identification, offering a strong guarantee of privacy for individuals and organizations.
Nulling or deletion is especially useful when irreversible anonymization is the goal, making it a reliable strategy for strict data protection requirements.
Numeric Variance (for Financial Data)
Numeric variance introduces a controlled level of randomness to numeric fields, obscuring the original values while retaining relative accuracy.
A percentage-based or fixed numeric variance is added or subtracted from each number. For example, a salary of $60,000 may be masked as $62,500 or $58,000, preserving the general range and patterns.
Ideal Use Cases
Numeric variance is well-suited for internal financial reporting, where trends and patterns are more important than precise values. It allows teams to review performance without revealing exact figures.
It’s also valuable for analytics and forecasting models, enabling data scientists to work with realistic ranges while protecting sensitive financial details.
Additionally, this method is ideal for sharing cost or budget data with external vendors, ensuring business insights can be communicated without exposing confidential numbers.
Security Strengths
Numeric variance preserves the overall statistical integrity of the data, allowing accurate analysis while concealing exact values. It helps prevent internal misuse by ensuring no one can access real financial figures unless explicitly authorized. This supports secure and valid testing or modeling, especially in environments without full financial disclosure.
Redaction (Partial Masking)
Redaction hides sensitive data, commonly used for displaying limited information while concealing key identifiers.
Some data is masked using characters like asterisks (e.g., ****5678 for a credit card). This preserves information like the last few digits to enable reference or validation.
Ideal Use Cases
Redaction is ideal for scenarios where partial data visibility is necessary, such as displaying the last four digits of a credit card or portions of a Social Security number.
It’s also valuable for email confirmations, logs, or audit trails where limited user details are needed for verification without revealing full identities. This technique fits systems that require partial data display for operational efficiency, like customer support tools or transaction monitoring platforms.
Security Strengths
Redaction prevents full data exposure while preserving enough information for user interaction or validation. It reduces risk during communication and troubleshooting by ensuring sensitive details are not fully visible to end users or support teams. It is straightforward and easily understood, making it a practical option for many business applications.
Tokenization
Tokenization replaces sensitive data with randomly generated surrogate values (tokens) unrelated to the original data.
Each sensitive value is replaced with a unique token stored in a secure mapping table or vault. Unlike encryption, tokens are not derived from the original data and cannot be reversed without access to the token database.
Ideal Use Cases
Tokenization is highly effective in payment processing systems, where it helps meet PCI DSS compliance by replacing cardholder data with non-sensitive tokens.
It’s also widely used to protect personally identifiable information (PII) in customer databases, allowing organizations to store and manage user data securely. Additionally, tokenization supports secure APIs and microservices architectures, where sensitive data must be handled across distributed systems without exposure.
Security Strengths
Tokenization offers strong security by replacing real data with random tokens that have no exploitable value without access to the secure mapping vault. It enables role-based access control, ensuring only authorized systems or users can retrieve the original values when necessary.
By minimizing the exposure of sensitive data, tokenization also helps reduce the scope and complexity of compliance audits under standards like PCI DSS and HIPAA.
Streamlining Secure Access with Avahi’s Intelligent Data Masking Tool
As part of its commitment to secure and compliant data operations, Avahi’s AI platform offers tools that help organizations manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Overview of Avahi’s Data Masker
Avahi’s Data Masker is a versatile data protection tool designed to help organizations securely handle sensitive information across various industries, including healthcare, finance, retail, and insurance.
The tool enables teams to mask confidential data such as account numbers, patient records, personal identifiers, and transaction details without disrupting operational workflows.
Avahi’s Data Masker ensures only authorized users can view or interact with sensitive data by applying advanced masking techniques and enforcing role-based access control. This is especially important when multiple departments or external vendors access data.
Whether protecting patient health information in compliance with HIPAA, anonymizing financial records for PCI DSS, or securing customer data for GDPR, the tool helps organizations minimize the risk of unauthorized access while preserving data usability for development, analytics, and fraud monitoring purposes.
How the Data Masking Feature Works
The process of masking sensitive information using Avahi’s Data Masker is intuitive and AI-powered:
1. Upload File
Users begin by uploading the dataset or file containing sensitive information through the Avahi platform.
2. Data Preview
Once uploaded, the tool displays the structured content, highlighting fields typically considered sensitive (e.g., PANs, names, dates of birth).
3. Click ‘Mask Data’ Option
Users then initiate the masking process by selecting the ‘Mask Data’ option from the interface.
4. AI-Powered Transformation
Behind the scenes, Avahi uses intelligent algorithms and predefined rules to identify and mask sensitive data values. This transformation ensures that the masked data maintains its format and usability but does not contain the original information.
5. Secure Output
The resulting file shows obfuscated values instead of the original sensitive content, which can be used safely for fraud analysis, reporting, or third-party collaboration.
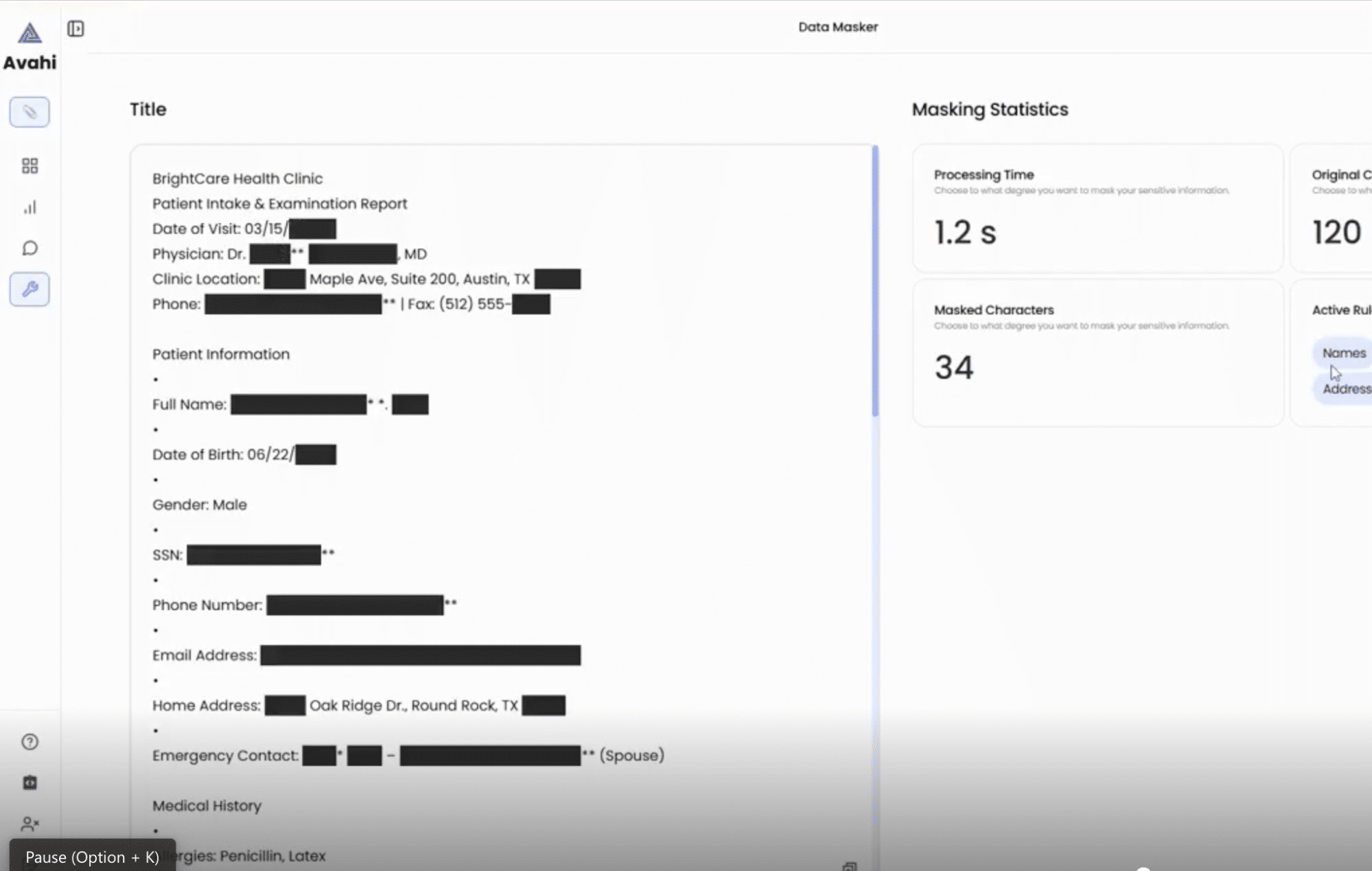
Avahi’s Data Masker integrates automation, user-friendly controls, and secure AI-driven masking to ensure regulatory compliance (e.g., PCI DSS) while minimizing operational friction.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution
At Avahi, we understand the critical importance of safeguarding sensitive information while ensuring seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions (FAQs)
1. What are data masking techniques, and why are they necessary?
Data masking techniques protect sensitive information by replacing original data with fictitious yet realistic values. These techniques are crucial for securing personal and financial data in non-production environments such as development, testing, or analytics while maintaining data usability.
2. What are the different types of data masking?
The main types of data masking include Static Data Masking, Dynamic Data Masking, Deterministic Masking, On-the-Fly Masking, and Pseudonymization. Each type serves different use cases depending on security needs, system architecture, and regulatory requirements.
3. How do data masking algorithms work?
Data masking algorithms apply logic-based transformations to sensitive data to make it unreadable while preserving format and structure. Standard algorithms include substitution, shuffling, hashing, encryption-based masking, and rule-based masking functions.
4. What is the difference between data masking, encryption, and anonymization?
Unlike encryption, which requires a decryption key, or anonymization, which permanently removes data identifiers, data masking techniques replace original data with functional values that retain structure for testing or analytics without revealing real information.
5. When should organizations use database masking tools?
Database masking tools should be used when replicating production data for development, QA, training, or reporting. These tools automate the masking of sensitive fields like PII or financial data and ensure compliance with GDPR, HIPAA, and PCI DSS regulations.



