

TL;DR
|
One mistake in handling sensitive data can cost millions or even destroy trust that took years to build.
As companies collect more personal data, concerns around privacy are growing sharply. According to a recent survey, 70% of business leaders report that their companies have increased the collection of consumer personal data over the last year. At the same time, 86% of individuals say data privacy is a growing concern, and 68% are troubled by the level of data collection by companies.
These concerns are prompting organizations to reassess their data collection, storage, and sharing practices. As businesses increasingly rely on data for operations, analytics, and innovation, the risks of mishandling sensitive information have never been higher.
Data masking and data anonymization play a crucial role in safeguarding sensitive data from unauthorized access, ensuring privacy, and meeting compliance with stringent regulations such as GDPR, HIPAA, and PCI DSS.
However, they serve different purposes and are suited to various scenarios. Choosing the wrong approach can result in unnecessary exposure or lost data utility. In this blog, we break down the differences between Data Masking and Data Anonymization to help you understand when to use each and how to make the right choice for your organization. Let’s explore how you can protect data effectively while enabling secure and responsible data use.
How Data Masking Protects Sensitive Data: Features, Techniques, and Use Cases

Data masking is a technique used to conceal or modify sensitive data, preventing unauthorized individuals from accessing or misusing it. Even though the data is masked, it still looks realistic and keeps its original format. This allows software systems to work correctly during testing, development, or training without exposing actual sensitive information.
Essential Characteristics of Data Masking
1. Reversible Under Controlled Conditions
In some cases, masked data can be converted back to its original form, but only by authorized users who have the proper tools or keys. This is usually done under strict security controls.
2. Preserves Data Format and Structure
Data masking maintains the original structure of the data. For example, if the original data is a 10-digit phone number, the masked data will also look like a 10-digit phone number. This helps systems work as they should without errors.
3. Used Primarily in Non-Production Environments
Data masking is primarily used in environments such as testing, development, and training. These are areas where real data is not necessary, but realistic-looking data helps in checking or demonstrating how a system works.
Common Techniques of Data Masking
1. Substitution
Substitution replaces real data with fake but realistic-looking data. The substituted values follow the same format and type as the original data, ensuring that systems and applications continue to function correctly.
For example, in a customer database, actual names like John Smith and Priya Patel might be replaced with names like Alex Brown and Maria Gomez drawn from a list of common names. Similarly, a real address such as 123 Elm Street could be swapped for 456 Oak Avenue.
This method helps create test or training data that looks authentic without revealing any real information.
2. Shuffling
Shuffling rearranges or mixes up data values within the same column so that individual records no longer match their original owners. This keeps the data valid in terms of type and format, but it disconnects it from the actual people or items to which it belongs.
3. Masking Out
Masking out hides parts of the data using symbols such as asterisks or Xs. This reveals only part of the data while protecting the rest.
For example, a credit card number like 1234 5678 9012 3456 could be masked as XXXX XXXX XXXX 3456, showing only the last four digits. Similarly, an email address like alex.brown@example.com could be masked as a**@example.com*.
This method is practical when limited parts of the data need to be visible for verification, while the sensitive parts stay hidden.
4. Encryption
Encryption converts data into unreadable code using an algorithm and an encryption key. The data can only be converted back to its original form (decrypted) using the correct key. Encryption adds strong protection but requires key management and access control.
A customer’s account number or social security number can be encrypted so that it appears as a string of random letters and numbers to anyone without access to the decryption key, such as GH57@9sJ2! instead of 123-45-6789.
This ensures that even if the data is accessed without authorization, it cannot be understood without the key.
5. Nulling Out
Nulling out removes the sensitive data entirely and replaces it with empty (null) values. The structure of the database remains intact, but the actual data is no longer there.
For example, in a test database, fields like social security number, date of birth, or email address might be set to null or empty values. Instead of displaying any data, those fields remain blank.
This is often used when the data itself is not needed for the test, but the database must remain valid.
Benefits of Data Masking
The masked data looks and behaves like the original data. This helps teams test and validate systems in conditions that closely resemble real-world use. Non-production environments are often less secure than live systems. By masking the data, the risk of someone accessing real sensitive information is reduced.
Data masking helps organizations comply with laws and regulations such as GDPR, HIPAA, or PCI DSS. It ensures sensitive data is not exposed where it shouldn’t be, while still allowing essential work to continue.
Understanding Data Anonymization: Key Features, Methods, and Benefits
Data anonymization is the process of permanently removing or changing personal information in a dataset so that individuals cannot be identified. Once data is anonymized, it is impossible to trace it back to a specific person. This ensures the data is safe to use for analysis, research, or sharing without compromising privacy.
Essential Characteristics of Data Anonymization
Irreversible Process
Anonymization changes the data so that it can never be linked back to the original person. Unlike data masking, there is no way to reverse the changes and recover the original details.
Ensures Individuals Cannot be re-identified
The goal of anonymization is to ensure that no one can determine the identity of the data owner, even when combined with other datasets. It removes or alters information that could reveal an identity.
Suitable for Data Analysis and Sharing
Since anonymized data no longer contains personal identifiers, it can be safely shared with other organizations, researchers, or the public for analysis or reporting.
Standard Techniques of Data Anonymization
1. Generalization
Generalization replaces precise data with broader categories. For example, instead of showing someone’s exact age as 43, the data might show an age range, such as “40-50.” Similarly, a specific address might be changed to just the city or region. This reduces the detail level so that individuals cannot be easily identified.
2. Suppression
Suppression removes certain pieces of data entirely. For example, names, Social Security numbers, or exact birth dates may be deleted from the dataset. This ensures that sensitive information does not exist in the shared data at all.
3. Pseudonymization
Pseudonymization replaces personal identifiers, such as names or IDs, with pseudonyms (fake or randomly generated identifiers).
While this still hides the real identity, it allows data related to the same person to be linked together for analysis. However, pseudonymized data is not fully anonymized unless the link to the real identity is also destroyed.
4. Perturbation
Perturbation alters the original data by adding small changes or “noise.” For example, income figures might be slightly adjusted so that the overall statistics stay the same, but the exact values are not absolute. This makes it harder to link the data back to individuals.
5. Synthetic Data Generation
Synthetic data generation creates completely artificial data that has the same statistical properties as the real data.
For instance, a dataset might be generated that reflects patterns seen in the original data but contains no real personal information at all. This method is helpful for safely sharing data for analysis or testing without risking privacy.
Benefits of Data Anonymization
Anonymization enables organizations to share data securely, as it excludes personal details that could compromise someone’s privacy.
By anonymizing data, organizations can comply with stringent data privacy laws that mandate the protection of personal information. Properly anonymized data ensures that no one can connect the data back to specific individuals, even when combined with other datasets.
Data Masking vs. Data Anonymization: A Comparative Analysis

When deciding between data masking and data anonymization, it is essential to understand the key differences between these two techniques. Below is a detailed comparison of both techniques:
1. Reversibility
Data Masking
Data masking can be reversible in controlled conditions. This means that the original data can sometimes be restored from the masked data, but only by authorized users who have access to the necessary tools, keys, or processes.
This feature can be helpful if there is a specific business need to view or recover the original data during development or testing. However, this reversibility introduces a level of risk because, if not managed properly, it could expose sensitive information.
Data Anonymization
Data anonymization is irreversible. Once data has been anonymized, there is no method to trace it back to the original individual or value. All personal identifiers are permanently removed or altered in a manner that prevents re-identification.
This makes anonymization a stronger method for privacy protection, especially when data needs to be shared with external parties or outside the organization.
2. Data Utility
Data Masking
Data masking is designed to preserve the format and structure of the original data. For example, if a field in a database contains a 16-digit credit card number, the masked version will also include a 16-digit number that looks realistic.
This allows systems, applications, and processes that rely on specific data formats to function correctly during development, testing, or training. The data behaves like real data without exposing sensitive information.
Data Anonymization
Data anonymization may alter the data to such an extent that it loses some of its utility for certain types of analysis. For example, generalizing data into ranges or adding noise might reduce its accuracy or level of detail.
While anonymized data is still helpful for broader research and trend analysis, it may not be suitable for tasks that require precise individual-level data, such as detailed customer behavior modeling or transactional testing.
3. Security Level
Data Masking
Data masking provides a strong level of security for protecting sensitive information in non-production environments. By masking data in development, testing, or training systems, organizations reduce the risk of unauthorized access to real information.
However, because data masking can be reversible in some cases, and because the masked data is still stored alongside the original structure, it does not offer the highest level of privacy protection.
Data Anonymization
Data anonymization offers a higher level of privacy protection because it ensures that no individual can be identified from the data, even if unauthorized parties access it.
Since anonymization is irreversible, it eliminates the risk of exposing original sensitive information through the dataset itself. This makes it ideal for situations where data will be shared externally, such as with research institutions, partners, or the public.
4. Compliance
Data Masking
Data masking helps organizations meet compliance requirements in controlled environments, such as development or testing systems. It is often part of a broader data protection strategy to ensure sensitive data is not exposed in areas where it is not needed.
Masking can help meet internal security policies and specific regulatory standards that require data protection in non-production environments.
Data Anonymization
Data anonymization is essential for compliance when data is shared outside the organization. Regulations such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA) require or encourage the anonymization of personal data before it is shared externally.
Anonymization enables organizations to demonstrate that they are taking appropriate steps to protect individual privacy and meet their legal obligations related to data sharing and processing.
Data Masking vs Data Anonymization Use Cases: Choosing the Right Approach
Selecting between data masking and data anonymization depends on how the data will be used, who will access it, and what level of privacy protection is required. Below is a detailed explanation to help you determine which method best suits your specific needs.
When to Use Data Masking
1. Software Testing and Development
Data masking is commonly used when developers or testers need to work with data that looks and behaves like the real thing. This helps ensure that systems are appropriately tested without exposing actual sensitive data.
2. User Training Environments
When employees or system users are being trained, masked data allows them to practice with realistic information. This ensures that training reflects real-world use without risking privacy.
3. Outsourcing to Third Parties
When work is given to external vendors or contractors who need access to systems or data, masking ensures that sensitive details are hidden while still providing data that is useful for their tasks.
4. Internal Analytics in Non-Production Systems
Masked data can be used for internal reporting or analysis in environments that are not live production systems, where security controls might not be as strict.
5. When Data Needs to Retain Its Original Format
If systems or processes depend on data being in a particular format or structure, such as specific number lengths, date formats, or text patterns, data masking helps maintain that structure. This allows systems to run correctly without exposing real data.
When to Use Data Anonymization
1. Publishing Open Data Sets
Organizations use anonymization when releasing data to the public, such as government agencies sharing public health data or companies providing transparency reports. This protects individual privacy while making data available for public use.
2. Medical Research and Public Health Studies
In health-related research, anonymization is crucial to comply with privacy laws and ethical standards. It allows valuable analysis of health trends without revealing the identities of individuals.
3. Data Sharing for Regulatory Reporting
When organizations need to report to regulators or governing bodies, anonymized data ensures compliance with privacy laws while still fulfilling reporting requirements.
4. When sharing data with external parties
Data anonymization is the preferred choice when data is being shared outside the organization, such as with partners, researchers, or vendors. It ensures that no personal information can be linked back to individuals, reducing privacy risks.
Here is a look at essential factors that should guide your decision.
|
Data Privacy Best Practices: Effective Ways to Apply Masking and Anonymization
Whether using data masking or data anonymization, it is essential to follow best practices to ensure data privacy is effectively maintained. Below are essential practices organizations should follow when applying these techniques.
1. Understand the Purpose of Data Use
Before applying any method, clearly define why the data is needed and how it will be used. This helps determine the right level of data protection. For example, use data masking for internal testing and anonymization for external sharing.
2. Apply the Principle of Least Privilege
Give access only to those who need it. Ensure that only authorized personnel can view or handle masked or anonymized data, reducing the risk of accidental exposure.
3. Regularly Review and Update Techniques
Data privacy risks and regulatory requirements are subject to change over time. Review masking and anonymization processes regularly to ensure they are up to date and continue to meet both internal policies and external regulations.
4. Conduct Risk Assessments
Before sharing or using masked or anonymized data, assess the risk of re-identification. This is especially important when combining datasets or sharing data externally.
5. Document Data Protection Processes
Maintain clear records of how data masking or anonymization was applied to ensure transparency and accountability. This includes the techniques used, the individuals who applied them, and the reasons why the approach was selected. Documentation helps demonstrate compliance with laws and standards.
6. Use Trusted Tools and Technologies
Choose reliable software tools designed for data masking or anonymization. Ensure that the tool meets security standards and fits your organization’s data protection needs.
7. Test for Data Utility
After masking or anonymizing, test the data to confirm it still meets the requirements of its intended use. For example, verify that masked data functions correctly in testing systems, or that anonymized data continues to support meaningful analysis.
Streamlining Secure Access with Avahi’s Intelligent Data Masking Tool
As part of its commitment to secure and compliant data operations, Avahi’s AI platform provides tools that enable organizations to manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Overview of Avahi’s Data Masker
Avahi’s Data Masker is a versatile data protection tool designed to help organizations securely handle sensitive information across various industries, including healthcare, finance, retail, and insurance.
How the Data Masking Feature Works
The process of masking sensitive information using Avahi’s Data Masker is intuitive and AI-powered:
1. Upload File
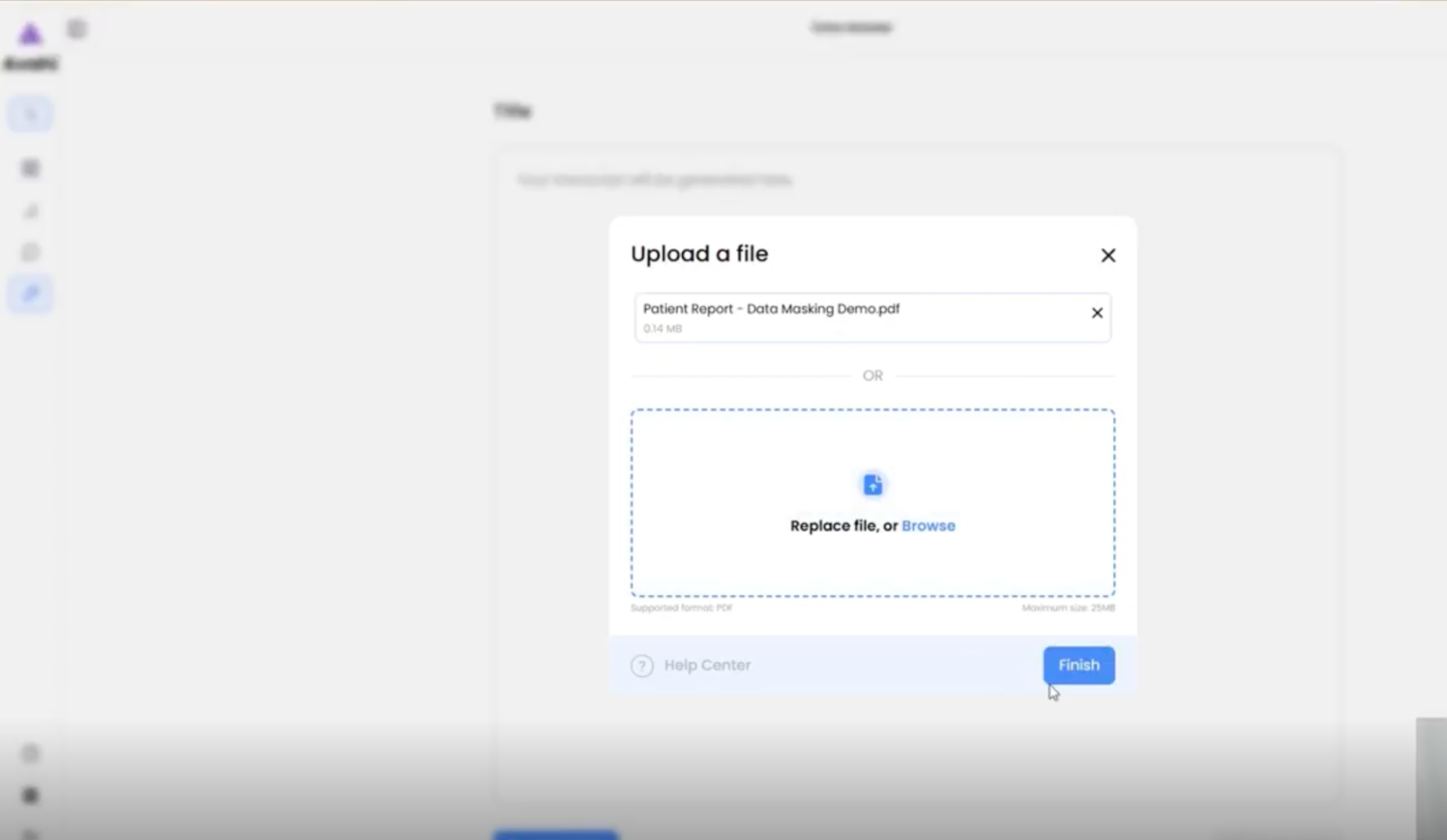
Users begin by uploading the dataset or file containing sensitive information through the Avahi platform.
2. Data Preview
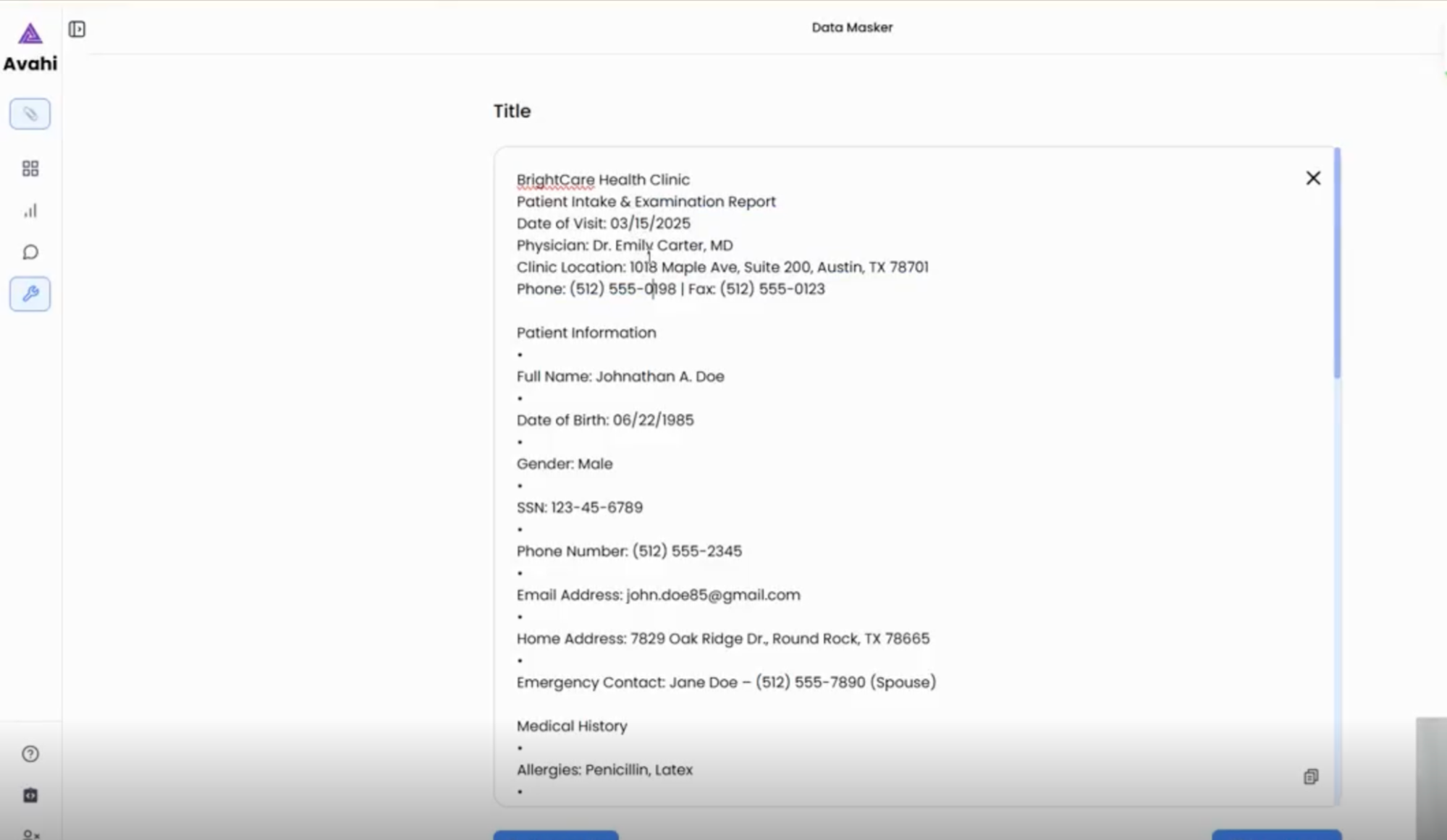
Once uploaded, the tool displays the structured content, highlighting fields typically considered sensitive (e.g., PANs, names, dates of birth).
3. Click ‘Mask Data’ Option
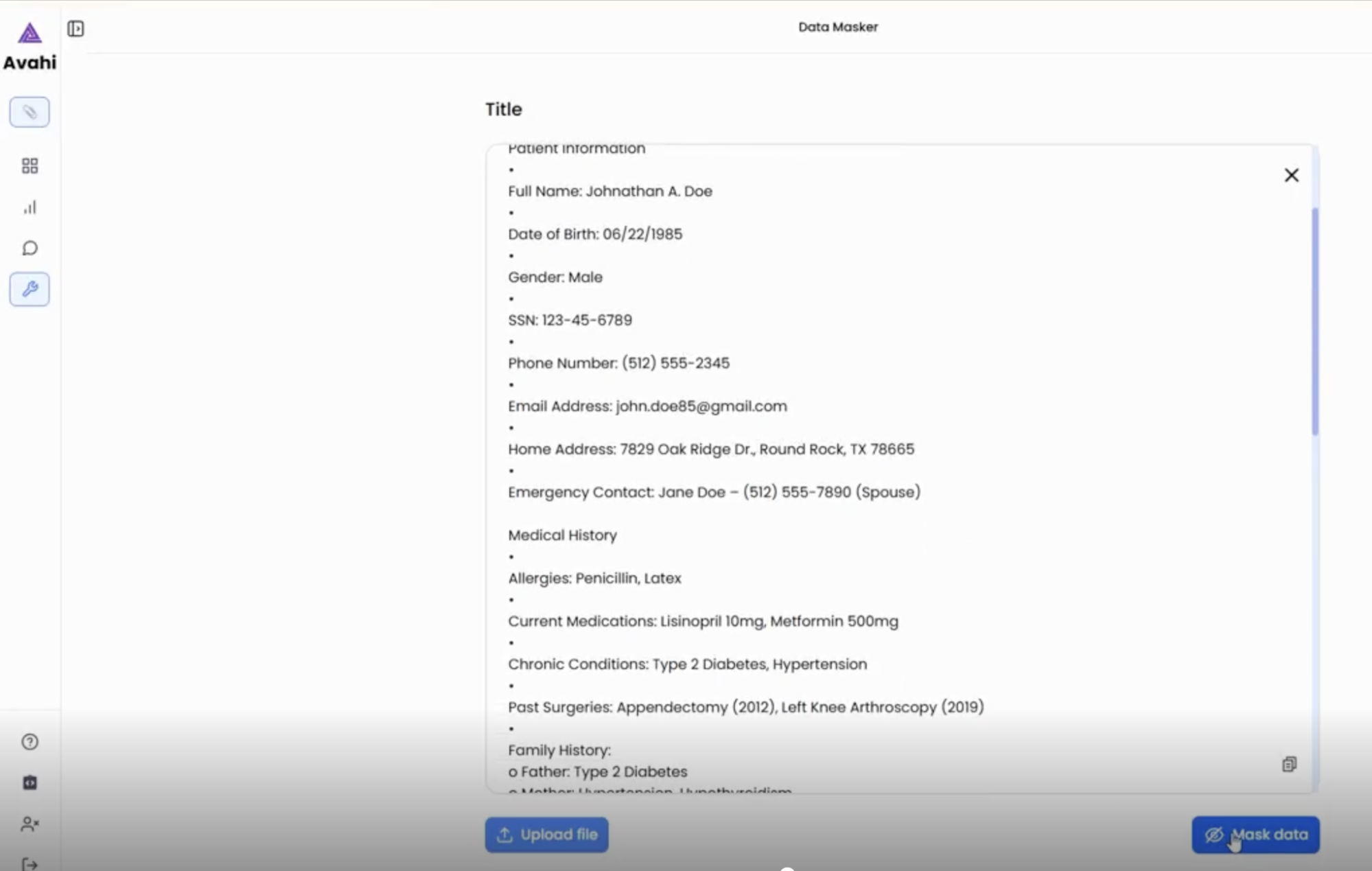
Users then initiate the masking process by selecting the ‘Mask Data’ option from the interface.
4. AI-Powered Transformation
Behind the scenes, Avahi uses intelligent algorithms and predefined rules to identify and mask sensitive data values. This transformation ensures that the masked data maintains its format and usability but does not contain the original information.
5. Secure Output
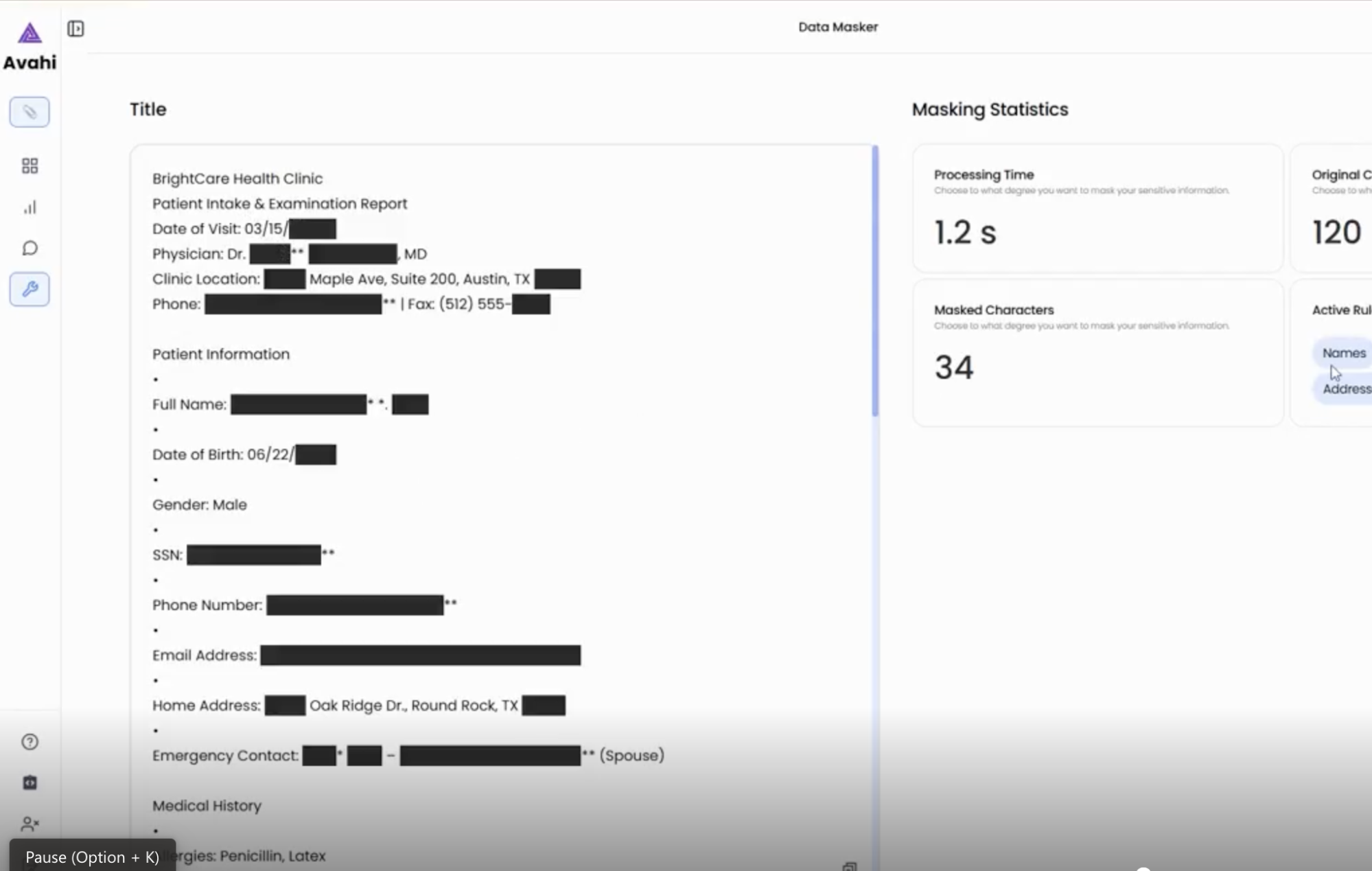
The resulting file shows obfuscated values instead of the original sensitive content, which can be used safely for fraud analysis, reporting, or third-party collaboration.
Avahi’s Data Masker integrates automation, user-friendly controls, and secure AI-driven masking to ensure regulatory compliance (e.g., PCI DSS) while minimizing operational friction.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution

At Avahi, we recognize the crucial importance of safeguarding sensitive information while maintaining seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions
1. What is the difference between data masking and data anonymization?
Data masking hides sensitive data by altering it while preserving its structure, often for testing or training purposes. Data anonymization permanently removes identifiers, ensuring that individuals cannot be identified, typically for external sharing or research purposes.
2. When should I use data masking instead of data anonymization?
Data masking is best suited for internal environments, such as testing, development, or user training, where a realistic data format is required but sensitive details must remain protected.
3. Is data anonymization better for GDPR compliance than data masking?
Yes, data anonymization is typically required for GDPR compliance when data is shared externally, as it ensures individuals cannot be re-identified. Masking may suffice for internal, controlled environments.
4. Can data masking and data anonymization be combined?
Yes, organizations can combine both methods, using masking for internal non-production environments and anonymization for external data sharing, to meet different security and compliance requirements.
5. Does anonymized data still work for analysis?
Yes, anonymized data can still support analysis, especially for trends and patterns, although it may lose some precision for individual-level insights due to data generalization or added noise.



