
TL;DR
|
A Gartner forecast predicts that by 2027, 60% of organizations will fail to realize the full value of their AI initiatives, not because of a lack of advanced tools, but due to fragmented or ineffective data governance frameworks.
This insight applies well beyond AI. The same governance gaps are a significant reason why many data protection strategies, including data masking, fall short of expectations.
Data masking is often treated as a checkbox task: mask the sensitive fields, share the dataset, and move on. But in practice, the process is far more complex.
Identifying sensitive data, preserving referential integrity, supporting multi-cloud architectures, and maintaining masking performance all require more than just tooling. They demand structure, strategy, and continuous oversight.
In this blog, we take a closer look at the top 15 data masking challenges that organizations face today. Whether you’re responsible for compliance, development, or data architecture, this breakdown will help you spot common pitfalls and understand how to implement data masking that’s secure, scalable, and truly effective.
The Fundamentals of Data Masking: How It Works and Where It Applies

Data masking is the process of replacing real, sensitive data with modified values that retain the same format and structure but are no longer identifiable. This technique helps protect confidential information such as personally identifiable information (PII), protected health information (PHI), payment details, and proprietary business data from unauthorized access.
The main objective of data masking is to secure sensitive data while keeping it usable for purposes like software testing, user training, analytics, or outsourcing, where accessing actual production data poses a security or compliance risk.
Role in Data Protection
Data masking ensures that sensitive data is not exposed in non-production environments or during data sharing. It supports regulatory compliance (e.g., GDPR, HIPAA, PCI DSS), risk mitigation by minimizing data exposure, and safe data sharing within and outside the organization. Unlike encryption, masked data does not require a key to reverse the transformation, making it inherently safer for use outside secure environments.
Types of Data Masking
1. Static Data Masking (SDM)
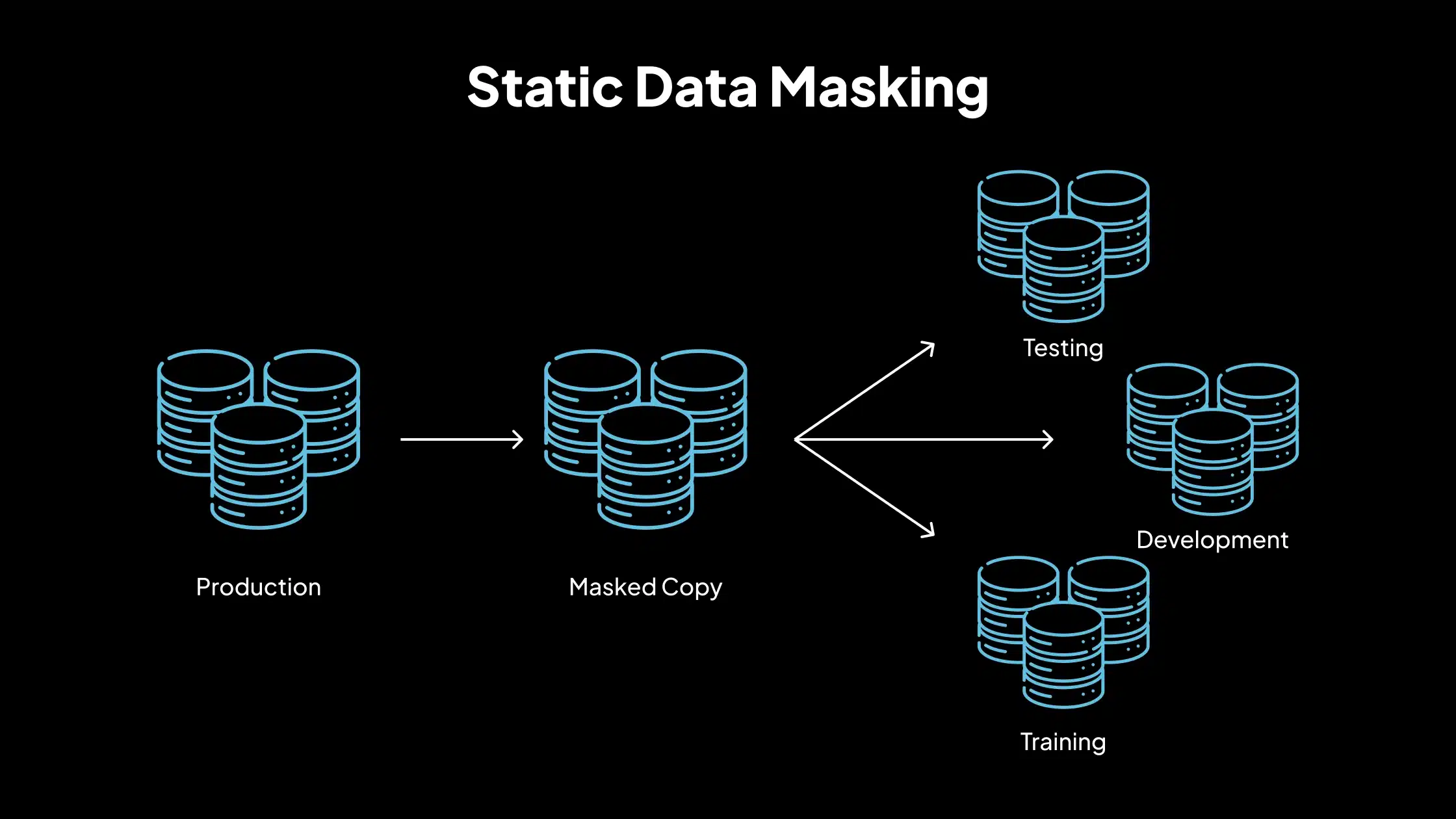
Static data masking involves creating a sanitized version of the original dataset. The data is masked at rest and stored as a separate copy. This method is used for development and testing environments, training scenarios, and data sharing with external vendors. Once masked, the data does not change and cannot be reverted to its original form.
2. Dynamic Data Masking (DDM)
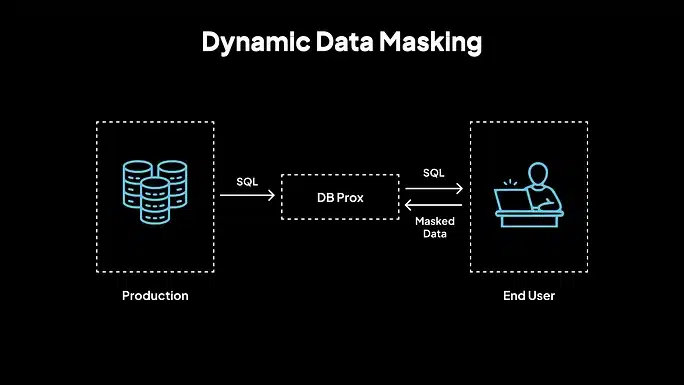
Dynamic masking occurs at runtime. The actual data remains unchanged in the database, but users with limited access see only the masked values when querying the data. This method is suitable for role-based access control, customer service platforms, and live dashboards where full access is not required. DDM is policy-driven and applied in real-time based on user privileges.
3. Deterministic Data Masking
Deterministic masking ensures that the same input always results in the same masked output. For example, “ Amanda Smith” will always become “David Jones” across all records and databases. This type is proper when maintaining referential integrity across tables and supporting analytics that rely on consistent data patterns. It allows masked datasets to retain logical relationships while ensuring privacy.
4. On-the-Fly Data Masking
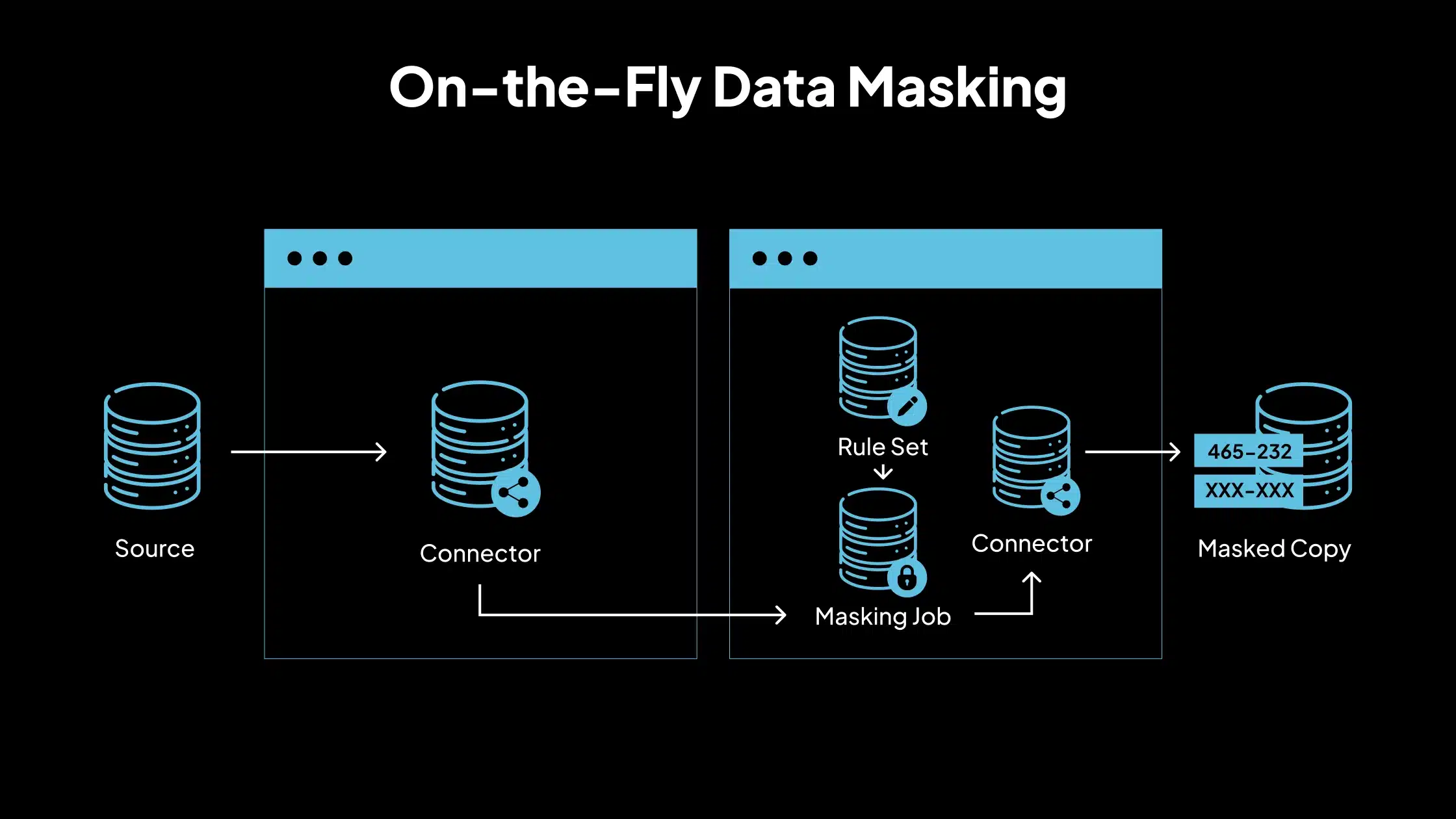
On-the-fly masking transforms data in transit, before it reaches the target environment. It does not store masked data permanently but processes it as it moves. This approach is best for continuous integration/continuous deployment (CI/CD) pipelines, real-time data replication and data migration to less secure environments. It offers flexibility without leaving masked data behind.
Top 15 Data Masking Challenges Every Organization Must Understand
Below is the list of the top 15 data masking challenges that organizations commonly face when implementing secure and scalable data protection strategies.
1. Identifying & Classifying Sensitive Data
One of the most fundamental challenges in data masking is accurately identifying and classifying sensitive data across diverse systems. Organizations often manage data stored in a variety of formats, structured (e.g., relational databases), semi-structured (e.g., JSON, XML), and unstructured (e.g., documents, emails, logs). Sensitive information such as names, social security numbers, credit card details, and medical records may exist in all these formats, sometimes in unexpected places.
In large or legacy systems, data silos, inconsistent schemas, and undocumented fields further complicate the process. Without precise classification, there is a risk of either failing to mask sensitive data (leading to compliance risks and data breaches) or masking non-sensitive data (affecting downstream applications unnecessarily).
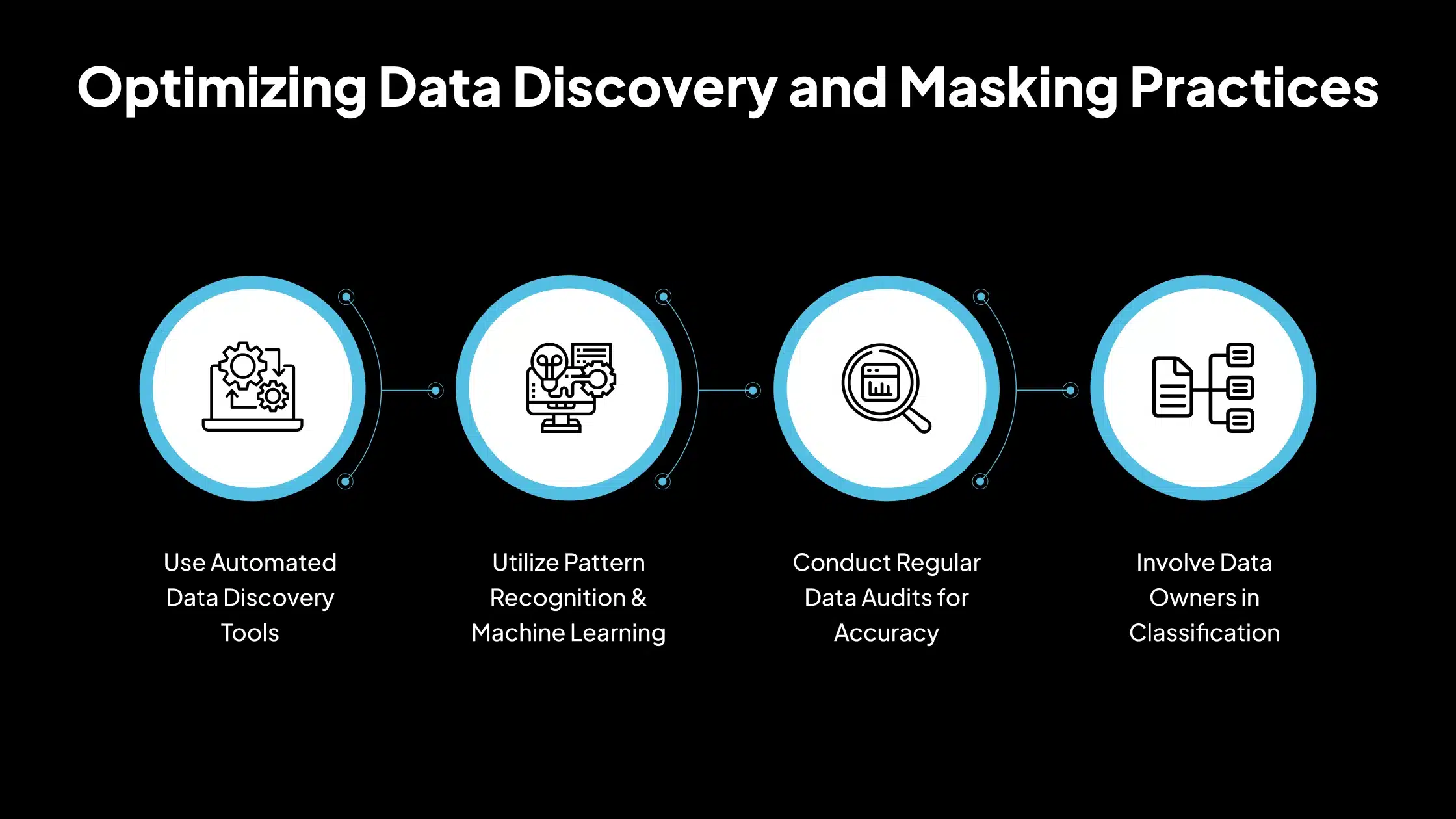
Organizations can mitigate this challenge by using automated data discovery tools that use pattern recognition, machine learning, or rule-based classification to scan and tag sensitive data. Regular data audits, metadata analysis, and involving data owners in the classification process also improve accuracy. Establishing a centralized data inventory or data catalog ensures visibility across environments.
2. Striking the Right Balance: Privacy vs. Utility
Another critical challenge is balancing privacy protection with the usability of masked data. If data is over-masked, it loses the essential attributes needed for valid testing, analytics, or development. For example, replacing all names with “X” or converting all dates to a fixed value may result in data that doesn’t reflect real-world patterns. Conversely, under-masking exposes sensitive data to unauthorized users, defeating the purpose of masking and increasing regulatory and reputational risk.
This balance becomes especially important in environments where realistic test data is necessary to validate application behavior, detect performance issues, or run machine learning models.
To achieve this balance, organizations should use context-aware masking techniques such as format-preserving, deterministic, or statistical masking. These approaches maintain the data’s format and logic without exposing the actual values. Role-based access controls (RBAC) can also be implemented alongside masking to ensure that only the right users can view or interact with sensitive data.
3. Maintaining Referential Integrity Across Systems
When sensitive data is masked, one of the biggest technical hurdles is maintaining referential integrity, the logical relationship between data across different tables, databases, or systems.
For example, if a customer ID is masked in a “Customers” table but not consistently masked in the corresponding “Orders” table, the connection between customers and their orders breaks. This inconsistency can lead to application errors, inaccurate analytics, or failed system integrations.
Maintaining these relationships is especially complex in environments with foreign key constraints, distributed databases, or data warehousing pipelines where data from multiple sources converges.
The use of deterministic masking techniques can help maintain consistent masked values across all instances of the same data. For example, ensuring that the same name or ID always results in the same masked output, regardless of where it appears, and preserves relational integrity. Organizations should also establish masking policies that apply consistently across all data sources and conduct test runs to verify that relationships remain intact after masking.
4. Handling Diverse Data Types & Formats
Modern organizations work with a wide variety of data formats, ranging from highly structured relational databases to semi-structured data like JSON files, and unstructured formats such as PDFs, emails, chat logs, and image metadata. Each format requires a different approach to identify and mask sensitive information. While structured data may allow for column-level masking, semi-structured and unstructured data often involve parsing nested fields or using natural language processing to detect sensitive content.
5. Scaling Masking in High-Volume or Big Data Environments
When working with large datasets, a common issue in big data and analytics platforms, scaling data masking processes becomes a significant challenge. Massive volumes of data, often stored in distributed systems like Hadoop, Spark, or cloud data lakes, demand high-performance masking that doesn’t delay workflows or impact system performance.
Conventional masking tools may not be optimized for such environments, leading to slow processing, memory overload, or incomplete masking. Additionally, the masking process must accommodate constant data ingestion and real-time updates without creating bottlenecks.
Organizations can overcome this by using parallelized or in-memory masking engines designed for high-speed performance across distributed data systems. Cloud-native masking solutions that integrate with data platforms like AWS, Azure, or GCP also offer better scalability. Incorporating masking early in the ETL/ELT pipeline and using incremental masking for changed data can further enhance performance in high-volume scenarios.
6. Operating Across Hybrid or Multi-Database Environments
In many enterprises, data is spread across a combination of on-premises systems, cloud services, and multiple database platforms such as PostgreSQL, MySQL, Oracle, SQL Server, or Snowflake. Each system may have its schema, access controls, and masking capabilities, or lack them entirely. Coordinating consistent data masking across this heterogeneous landscape is complex.
The lack of centralized policy enforcement can lead to inconsistent masking outcomes, increased risk of exposure, and administrative overhead in maintaining multiple toolsets and rules.
To address this, organizations should adopt centralized data masking platforms that support integration with various data sources and allow for unified policy management. These platforms can automate masking across systems using a single set of rules and provide centralized logs and controls for easier compliance monitoring.
7. Performance Impact & System Bottlenecks
Applying data masking, especially on large or complex datasets, can impact the performance of databases and applications. If masking operations are resource-intensive or poorly optimized, they can cause delays, increase processing times, or degrade the performance of the environment where they are executed. This is particularly problematic in live systems or time-sensitive processes such as analytics pipelines or CI/CD deployments.
In some cases, data masking jobs may lock tables, exhaust system memory, or interfere with other critical tasks, resulting in operational slowdowns or service disruptions.
To minimize performance impact, organizations should use masking tools optimized for their specific environment, such as column-level or in-place masking for structured databases, and batch processing for large volumes. It’s also advisable to run masking jobs during non-peak hours or in isolated staging environments.
8. Evolving Data & Masking Rules Over Time
As business systems grow and regulations evolve, data models often change, new tables are added, existing ones are modified, and new data types are introduced. At the same time, compliance requirements and internal security policies may demand updates to how data is masked. Keeping masking rules up to date and consistently applied across all systems becomes increasingly complex over time.
Without proper version control or policy governance, organizations risk leaving newly introduced sensitive data unmasked or applying outdated rules that no longer meet compliance needs.
To handle this, it’s essential to implement a governance framework for data masking that includes regular policy reviews, versioning of masking rules, and documentation of changes. Automated discovery tools can help detect schema changes and alert data teams to potential gaps.
9. Compliance & Audit Requirements
Data masking is often implemented to comply with data protection regulations such as GDPR, HIPAA, CCPA, and PCI DSS. These regulations require organizations not only to protect sensitive data but also to demonstrate that appropriate measures have been taken. Failure to produce audit trails, logs, or evidence of consistent masking can result in penalties, even if the data was technically protected.
Many masking implementations focus on the technical layer but overlook the documentation and traceability needed for audits. Without clear records of what data was masked, how it was masked, and who had access, compliance gaps can arise.

10. User Identity & Role-Based Masking
Not all users require the same level of data access. For example, a developer may only need masked values, while a compliance officer might need to view more detailed information. Implementing role-based data masking ensures that sensitive data is selectively masked based on the user’s identity, role, or access privileges. However, configuring and maintaining these dynamic rules across systems and user groups can be complex and prone to error.
Without fine-grained access control, sensitive data may be exposed to users who shouldn’t have access, or overly restrictive masking can hinder users who need real data context.
To manage this challenge, organizations should integrate data masking with identity and access management (IAM) systems. This allows masking policies to adjust based on user roles and permissions dynamically. Centralized role-based policies should be defined and regularly reviewed to ensure alignment with business needs. Monitoring access logs and implementing least-privilege access principles further help reduce unnecessary exposure while maintaining usability.
11. Quality of Masking in NLP / PII Detection Models
In many organizations, sensitive data isn’t limited to structured fields, it also exists in unstructured formats like emails, customer feedback, chat logs, or documents. Detecting and masking personally identifiable information (PII) in these sources often relies on Natural Language Processing (NLP) or Named Entity Recognition (NER) models. However, these models are not always accurate. They can misclassify or overlook certain entities, especially when dealing with slang, abbreviations, multilingual content, or irregular formatting.
As a result, critical PII may go undetected and remain unmasked, increasing the risk of data leakage or non-compliance. Alternatively, false positives may cause non-sensitive data to be masked unnecessarily, reducing data quality.
To improve accuracy, organizations should use context-aware and domain-specific NLP models trained on relevant datasets. Combining rule-based approaches (e.g., regex for phone numbers, email patterns) with machine learning models increases detection reliability. It’s also essential to validate model performance regularly and fine-tune it based on feedback. A layered approach that applies multiple detection methods can help reduce both false positives and false negatives in sensitive data identification.
12. Bias & Fairness in Masking Models
AI and machine learning models are used for data masking. Particularly for entity recognition or classification, it can exhibit bias.
For example, specific names, ethnicities, or demographic patterns may be underrepresented in training data, leading to inconsistent masking across different population groups. This creates an uneven layer of protection, where some users’ data may be masked correctly while others are overlooked. Such disparities reflect poorly on the organization’s data handling ethics and equity standards.
To address this, organizations must evaluate the fairness and representativeness of their masking models. This includes reviewing training data for diversity, measuring performance across demographic segments, and retraining models as needed. Transparency in model design and incorporating human-in-the-loop validation processes can also improve equity in data protection.
13. Securing Tokenization, Encryption & Deterministic Masking
Many organizations use advanced masking techniques like tokenization, encryption, or deterministic masking to protect sensitive data. While these methods offer strong security, they also introduce operational challenges. Tokenization and encryption require careful key management; if keys are lost, access to critical data is permanently blocked; if keys are mishandled, data could be exposed.
With deterministic masking, the same input must always yield the same masked output to preserve consistency across systems. However, ensuring this without making the data reversible can be difficult. If improperly implemented, deterministic masking may unintentionally leak patterns or enable re-identification.
14. Ensuring Data Realism and Validity
One of the goals of data masking is to preserve data usability, particularly for development, testing, or analytics. If masked data lacks realism (e.g., unrealistic birthdates, invalid phone numbers, or mismatched categories), applications may fail to function correctly. Additionally, some systems have built-in validations (such as checksum requirements for IDs) that masked data must still pass.
To ensure realism, masking should include format-preserving transformations that maintain data types, value ranges, and referential patterns. For example, masked dates should fall within realistic timeframes, and masked names should resemble valid entries. In systems that require validation (like credit card numbers), masking tools should generate syntactically correct substitutes.
Running automated validation tests after masking helps confirm that the masked data remains functionally valid and aligned with expected business rules.
15. Logging, Monitoring & Change Tracking
A frequently overlooked challenge in data masking is the lack of robust logging and monitoring mechanisms. Without detailed logs, it becomes difficult to track who applied the masking, when it was applied, what data was affected, and whether the masking process completed successfully. This can lead to issues during audits, troubleshooting, or change management.
Additionally, as data environments evolve, masking policies and configurations also need to be updated. Without change tracking, organizations risk applying outdated masking rules or introducing inconsistencies between environments.
Effective Strategies to Overcome Data Masking Challenges
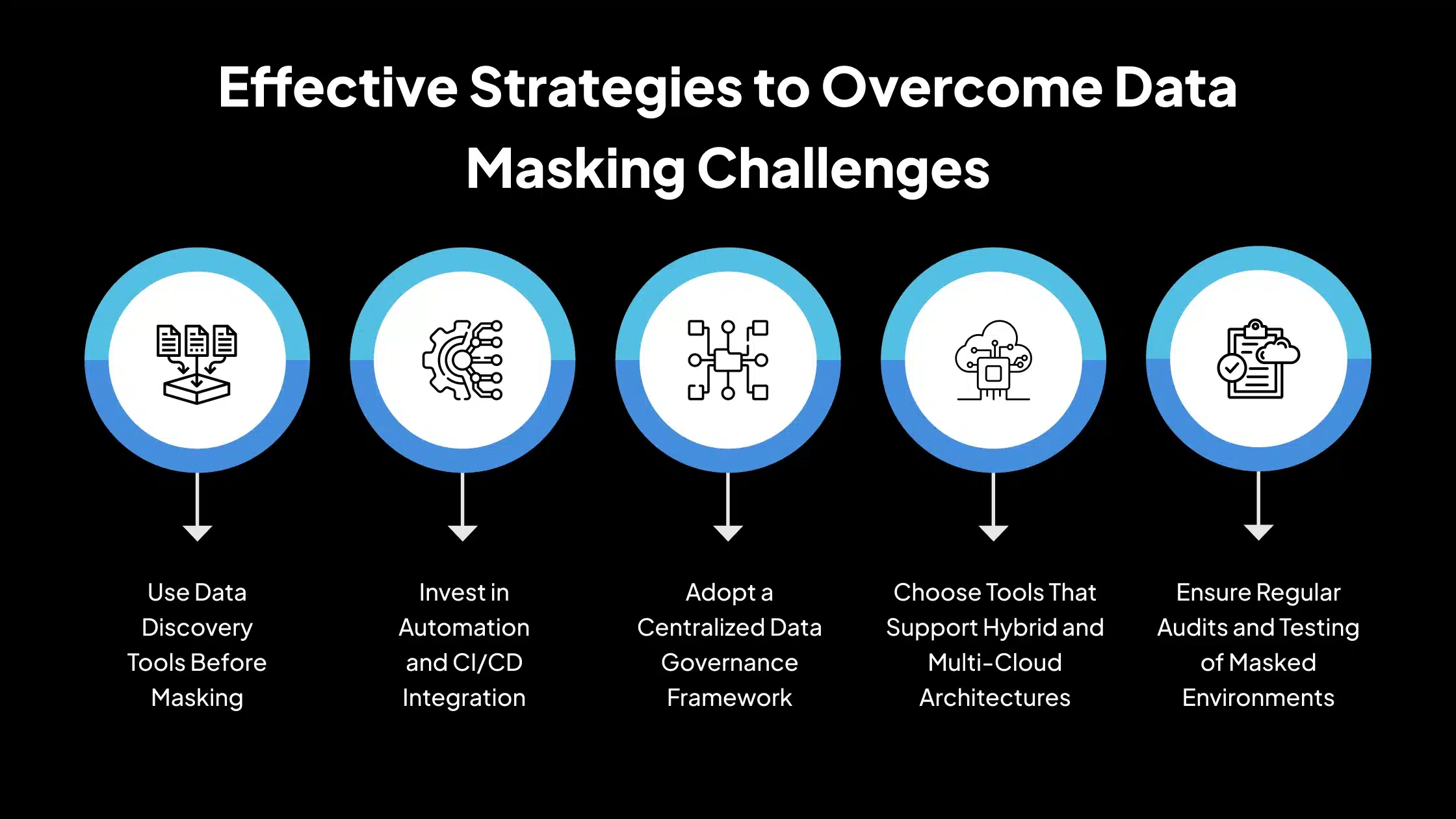
To effectively implement data masking and address the challenges discussed above, organizations should follow a structured and proactive approach. The following strategies can improve accuracy, scalability, and compliance across masking efforts:
1. Use Data Discovery Tools Before Masking
Before applying masking techniques, it’s essential to identify where sensitive data resides accurately. Data discovery tools can scan structured, semi-structured, and unstructured sources to locate PII, PHI, and other sensitive elements. These tools reduce the risk of overlooking critical data and help organizations build a reliable inventory of what needs to be protected.
2. Invest in Automation and CI/CD Integration
Manual masking is error-prone and difficult to scale. Integrating data masking into CI/CD pipelines ensures that data is automatically sanitized during development, testing, or deployment. Automation improves consistency, reduces human error, and speeds up workflows, particularly in environments that handle frequent data refreshes.
3. Adopt a Centralized Data Governance Framework
A governance framework defines how data masking policies are created, applied, reviewed, and updated. Centralizing this process allows for uniform enforcement across departments and systems. It also supports better audit readiness and policy tracking by consolidating responsibilities and documentation in one place.
4. Choose Tools That Support Hybrid and Multi-Cloud Architectures
Modern organizations often use a mix of on-premises systems, cloud services, and multiple databases. Choosing data masking tools that support hybrid and multi-cloud environments ensures consistent application of masking rules across all platforms. It also simplifies administration and reduces the need for separate tools for each system.
5. Ensure Regular Audits and Testing of Masked Environments
After masking is applied, it’s important to verify that the data remains functional, realistic, and compliant. Regular audits help detect gaps in masking coverage, while test runs confirm that applications continue to perform correctly. These checks should be part of routine data lifecycle management to ensure ongoing effectiveness.
Protect Sensitive Information with Avahi’s Intelligent Data Masking Tool
As part of its commitment to secure and compliant data operations, Avahi’s AI platform provides tools that enable organizations to manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Overview of Avahi’s Data Masker
Avahi’s Data Masker is a versatile data protection tool designed to help organizations securely handle sensitive information across various industries, including healthcare, finance, retail, and insurance.
The tool enables teams to mask confidential data such as account numbers, patient records, personal identifiers, and transaction details without disrupting operational workflows.
Avahi’s Data Masker ensures only authorized users can view or interact with sensitive data by applying advanced masking techniques and enforcing role-based access control. This is especially important when multiple departments or external vendors access data.
Whether protecting patient health information in compliance with HIPAA, anonymizing financial records for PCI DSS, or securing customer data for GDPR, the tool helps organizations minimize the risk of unauthorized access while preserving data usability for development, analytics, and fraud monitoring purposes.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution

At Avahi, we recognize the crucial importance of safeguarding sensitive information while maintaining seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions
1. What is the main difference between data masking and data encryption?
Data masking replaces sensitive values with fictitious but realistic-looking data to protect it in non-production environments. Unlike encryption, masked data is not meant to be reversed. Encryption protects data in production or transit and can be decrypted with a key, while masking is typically irreversible and used for testing, analytics, or training.
2. Why do organizations struggle to implement data masking effectively?
Common issues include poor data discovery, lack of centralized masking policies, difficulty maintaining referential integrity, and performance impacts on large datasets. Many also fail to integrate masking into CI/CD pipelines or overlook masking for unstructured data sources like logs and documents.
3. How can we ensure masked data remains useful for development and testing?
Using deterministic or format-preserving masking helps maintain data consistency and realism. This allows applications to function appropriately while ensuring privacy. Validation routines and automated testing can also confirm that masked data retains functional and logical integrity.
4. Is dynamic data masking suitable for all environments?
Not always. Dynamic data masking is ideal for real-time user access control in production but may not be sufficient for full de-identification. It’s best used when role-based access is needed, while static or on-the-fly masking is more appropriate for development, testing, or data sharing.
5. What tools or practices help mitigate data masking challenges?
Effective strategies include using automated data discovery tools, integrating masking into DevOps pipelines, adopting centralized governance, and choosing tools that support hybrid/multi-cloud environments. Regular audits and testing are also key to ensuring compliance and effectiveness.



