

TL;DR
|
One exposed database is all it takes to trigger a compliance violation, damage your reputation, and compromise customer trust.
As organizations handle increasing volumes of sensitive data—ranging from personal identifiers and financial records to proprietary business logic—securing that data has become a non-negotiable responsibility.
68% of organizations admit they store sensitive data in multiple cloud environments, often without complete visibility or control. Over 60% of breaches involve data that was not properly masked, encrypted, or anonymized (Verizon DBIR 2024).
In this environment, simply restricting access is no longer enough. Organizations must implement layered strategies that protect data across their lifecycle from development and testing to transmission and real-time processing. This is where data masking and data obfuscation come into play.
While both aim to shield sensitive information from unauthorized access, they do so using different approaches suited to other environments. Choosing the wrong one can lead to gaps in security, operational friction, or even legal exposure.
This blog will explore the differences between data masking and data obfuscation by breaking down underlying techniques and practical use cases, helping you determine which method best aligns with your data protection goals.
The Fundamentals of Data Masking: Secure Your Data Without Losing Its Value
Data masking is a data security technique that involves transforming sensitive information into a non-sensitive version, rendering it unusable to unauthorized users while maintaining its usability for authorized purposes. The primary goal is to protect sensitive data, such as personally identifiable information (PII), financial records, and health information, from unauthorized access, particularly in non-production environments like testing and development.
Common Techniques of Data Masking
1. Substitution
This technique replaces sensitive data with fictitious yet realistic values. For instance, actual names can be replaced with randomly selected names from a predefined list. This method maintains the data’s format and appearance, making it suitable for testing and training purposes.
2. Shuffling
Shuffling involves rearranging data within a dataset to disrupt the association between data elements. For example, employee names can be shuffled among different records, preserving the data’s structure but obscuring the original relationships.
3. Nulling Out
This method replaces sensitive data fields with null or blank values. While it effectively removes sensitive information, it may impact the usability of the data for certain applications, as the absence of data can affect processing and analysis.
4. Encryption
Encryption transforms data into an unreadable format using algorithms and keys. Only authorized users with the correct decryption key can access the original data. While encryption provides strong security, it requires careful key management and may introduce performance overhead.
5. Tokenization
Tokenization replaces sensitive data with non-sensitive placeholders, or tokens, which have no exploitable value. The original data is stored securely, and only authorized systems can map tokens back to the original data. This technique is commonly used in payment processing systems.
Types of Data Masking
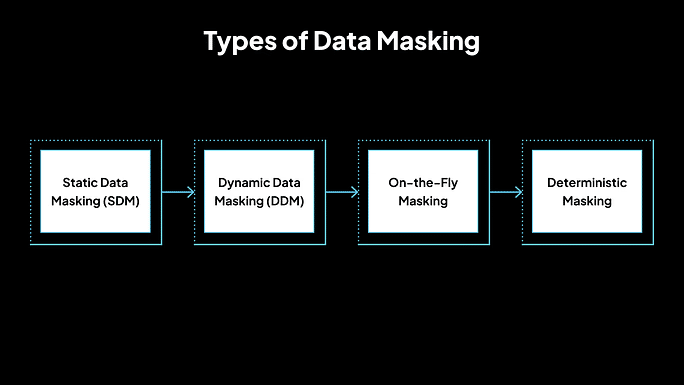
1. Static Data Masking (SDM)
SDM involves creating a masked copy of a database, where sensitive data is replaced with fictitious data. This masked dataset is then used in non-production environments. Since the masking is performed on a copy, the original production data remains untouched. SDM is suitable for scenarios where data does not need to be updated frequently.
2. Dynamic Data Masking (DDM)
DDM applies masking rules in real-time as users access data. The original data in the database remains unchanged, but unauthorized users see masked values based on their access privileges. DDM is useful for protecting sensitive data in live production environments without altering the underlying data.
3. On-the-Fly Masking
This approach masks data in transit, typically during data transfer between systems or environments. It ensures that sensitive data is protected during the transfer process without requiring storage of the masked data. On-the-fly masking is beneficial in continuous integration and deployment pipelines.
4. Deterministic Masking
Deterministic masking ensures that a specific input value is always replaced with the same masked value.
For example, the name “Alice” would always be masked as “Eve” across all datasets. This consistency is crucial for maintaining referential integrity across different systems and datasets.
The Essentials of Data Obfuscation: How It Protects Sensitive Information
Data obfuscation is a data security technique that involves deliberately transforming data to make it unintelligible or difficult for unauthorized individuals to interpret.
The primary goal is to protect sensitive information while maintaining its usability for authorized purposes. This is achieved by altering data values, structures, or representations without changing the overall functionality or format of the data.
Common Techniques of Data Obfuscation
1. Encryption
Encryption converts plaintext data into ciphertext using cryptographic algorithms and keys. Only authorized users with the correct decryption key can revert the data to its original form. Encryption is widely used for securing data at rest and in transit.
2. Tokenization
Tokenization replaces sensitive data elements with non-sensitive equivalents, known as tokens. These tokens have no exploitable meaning or value and are mapped back to the original data through a secure tokenization system. This method is commonly used in payment processing to protect credit card information.
3. Anonymization
Anonymization involves removing or modifying personal identifiers from data sets, making it impossible to link the data back to an individual. This technique is crucial for complying with privacy regulations when sharing data for research or analysis purposes.
4. Scrambling
Scrambling rearranges the characters or digits within data fields to obscure the original information. For example, scrambling a phone number would involve shuffling its digits, rendering it meaningless to unauthorized viewers.
5. Data Swapping
Data swapping involves exchanging data elements within a dataset to disrupt the association between data and individuals. For instance, swapping addresses between records ensures that while the data remains realistic, it no longer corresponds to the original individuals.
Types of Data Obfuscation
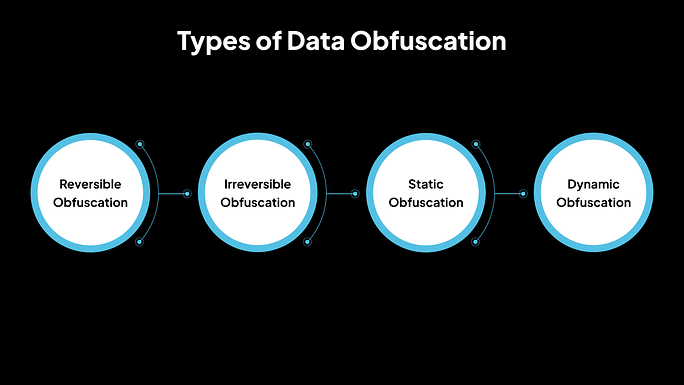
1. Reversible Obfuscation
Reversible obfuscation techniques allow the original data to be retrieved when necessary. Encryption and tokenization fall into this category, as they enable authorized users to access the original data using decryption keys or token mapping systems.
2. Irreversible Obfuscation
Irreversible obfuscation permanently alters data, ensuring that it cannot be reverted to its original form. Anonymization is a prime example, where personal identifiers are removed to protect individual privacy, and the original data cannot be reconstructed.
For example, a university shares a dataset of student health records for public health research. All names, IDs, and contact details are removed or irreversibly altered so that the data cannot be linked back to any individual.
3. Static Obfuscation
Static obfuscation is applied to data at rest, such as in databases or files, to prevent unauthorized access. The data is transformed before storage, ensuring that any unauthorized access to the storage medium yields only obfuscated data.
For instance, a company exports customer data from a live system to a staging environment for testing. Before export, all names, emails, and phone numbers are scrambled or replaced with placeholders.
4. Dynamic Obfuscation
Dynamic obfuscation occurs in real-time, transforming data as it is accessed or transmitted. This approach is helpful in protecting data in applications where data must remain secure during processing or communication.
For example, a company exports customer data from a live system to a staging environment for testing. Before export, all names, emails, and phone numbers are scrambled or replaced with placeholders.
Data Masking vs. Obfuscation: Detailed Feature Comparison for Informed Decision-Making
| Feature | Data Masking | Data Obfuscation |
| Purpose | Used in non-production (testing, dev, training). | Used in production; conceals data during use/transmission. |
| Reversibility | Irreversible. | Can be reversible (e.g., encryption) or irreversible (e.g., anonymization). |
| Data Utility | Maintains format and usability. | May reduce usability due to data alteration. |
| Complexity | More complex, it requires planning and an understanding of data. | Simpler to implement; may sacrifice accuracy or structure. |
| Implementation Time | Time-intensive; needs cross-system coordination. | Faster with tools; varies by data and technique. |
| Security Level | Strong for non-production environments. | Strong for production; protects against live access risks. |
| Performance Impact | Minimal impact in non-production use. | It can affect performance in real-time processing (e.g., encryption overhead). |
This section provides a detailed comparison between data masking and data obfuscation across various critical features. Understanding these differences will help in selecting the most suitable data protection strategy for an organization’s specific needs.
1. Purpose
Data Masking
It is primarily used to protect sensitive data in non-production environments such as testing, development, and training. It ensures that while the data is fictitious, it remains realistic and usable for these purposes.
Data Obfuscation
It aims to conceal data to prevent unauthorized access, often in production environments. It transforms data into a format that is unintelligible or less useful to unauthorized users, thereby protecting sensitive information during processing or transmission.
2. Reversibility
Data Masking
It is generally irreversible; once data is masked, it cannot be reverted to its original form. This ensures that sensitive information remains protected even if the masked data is exposed.
Data Obfuscation
Can be reversible or irreversible, depending on the technique used. For instance, encryption is reversible with the correct key, while specific anonymization methods are designed to be irreversible.
3. Data Utility
Data Masking
It maintains the usability of data for specific purposes, such as testing and training, while preserving confidentiality. The masked data retains the format and characteristics of the original data, allowing for meaningful use without exposing sensitive information.
Data Obfuscation
This may reduce the usability of data, especially if the obfuscation process significantly alters the data structure or content. This can limit the data’s applicability for specific operations or analyses.
4. Complexity
Data Masking
Often involves complex processes to ensure that the masked data remains realistic and maintains referential integrity. It requires a thorough understanding of the data and its interrelationships.
Data Obfuscation
Generally less complex and can be implemented more quickly. However, the simplicity may come at the cost of reduced data utility or effectiveness in specific scenarios.
5. Implementation Time
Data Masking
Implementation can be time-consuming due to the need for careful planning to maintain data integrity and usability. It often requires coordination across various systems and teams.
Data Obfuscation
Generally quicker to implement, especially when using automated tools or scripts. However, the speed of implementation may vary depending on the complexity of the data and the obfuscation techniques used.
6. Security Level
Data Masking
It provides a high level of security for non-production environments by ensuring that sensitive data is not exposed during testing or development activities.
Data Obfuscation
It offers robust security in production environments by making data unintelligible to unauthorized users, thereby protecting against data breaches and unauthorized access.
7. Performance Impact
Data Masking
Generally has minimal impact on system performance, especially when applied to non-production environments.
Data obfuscation
This may impact performance, particularly if complex obfuscation techniques, such as encryption, are used in real-time processing or data transmission scenarios.
Data Masking vs. Obfuscation: Which Technique Fits Your Use Case?
Understanding the appropriate context for each technique is crucial for maintaining both data security and operational effectiveness. Below is a clear explanation of when to use data masking and data obfuscation:
When to Use Data Masking
Use data masking when sensitive data needs to be used in environments where it should not be exposed, such as development, testing, analytics, or training environments.
The masked data retains its structure and format. The original data is permanently replaced or transformed. It is a one-way process; the real data cannot be retrieved from the masked version. Masked data should be realistic enough to allow for valid testing or training without compromising security.
Ideal Situations
- When developers or testers need to work with realistic data but have restricted access to actual sensitive information.
- When sharing datasets with third-party vendors or internal teams who don’t need access to real data.
For example, a healthcare provider needs to provide access to patient databases for software testing. To comply with HIPAA and protect patient privacy, they use data masking to replace names, birth dates, and medical records with fictitious but realistic values. Developers can still perform functional testing without accessing actual patient data.
Practical Use Cases of Data Masking
1. Software Testing and Development Environments
In software development, realistic data is crucial for effective testing and debugging. However, using actual production data poses significant security risks. Data masking enables developers to work with data that closely mirrors real-world scenarios without exposing sensitive information, thereby ensuring compliance with data protection regulations.
2. Data Analytics and Reporting
Analysts require access to data to derive insights and make informed decisions. Data masking enables the use of meaningful datasets for analysis while safeguarding sensitive information, thus balancing data utility with privacy concerns.
3. Training and User Demonstrations
Training sessions and product demonstrations often necessitate the use of data to simulate real-life scenarios. Employing masked data ensures that sensitive information is not inadvertently disclosed during these activities.
When to Use Data Obfuscation
Use data obfuscation to conceal or scramble information, making it difficult to interpret or reverse-engineer. This is especially useful for protecting intellectual property or transient data during communication or execution.
The transformation may be reversible (e.g., via encryption) or partially reversible, depending on the method used. It often involves code, scripts, API keys, or configuration files, rather than structured data such as database records. The focus is on making the data or logic unreadable or unusable to unauthorized users.
Ideal Situations
- When distributing compiled applications, source code must be protected.
- When sending sensitive data through APIs or storing credentials in configuration files.
- When implementing security in front-end applications (e.g., JavaScript obfuscation to hide business logic).
For example, a SaaS company offers a downloadable desktop tool. To protect proprietary algorithms and prevent reverse engineering, the company uses code obfuscation on the compiled software. Additionally, they obfuscate API keys used in their web apps to prevent unauthorized access.
Practical Use Cases of Data Obfuscation
 1. Protecting Data in Production Environments
1. Protecting Data in Production Environments
In live production systems, it’s crucial to safeguard sensitive data such as personally identifiable information (PII), financial records, and proprietary business information.
Data obfuscation techniques ensure that even if unauthorized access occurs, the exposed data remains unintelligible, thereby mitigating potential risks.
2. Securing Data During Transmission
When data is transmitted across networks, especially over the internet, it becomes vulnerable to interception. Obfuscating data before transmission ensures that, even if intercepted, the information remains unreadable to unauthorized parties.
3. Preventing Reverse Engineering of Software Code
In software development, obfuscation techniques are employed to make source code or binary files difficult to understand. This protects intellectual property by preventing competitors or malicious actors from reverse-engineering proprietary algorithms or business logic.
From Planning to Execution: Best Practices for Applying Data Masking and Obfuscation
To effectively protect sensitive data using masking or obfuscation, organizations should follow structured and proven implementation practices. Below are the essential steps that help ensure security, compliance, and operational efficiency:
-
Maintain Data Inventory
Maintaining a comprehensive inventory of sensitive data is the first critical step. Organizations must identify:
- What data is considered sensitive (e.g., names, credit card numbers, health records)?
- Where the data resides (e.g., databases, file systems, cloud environments).
- How is it accessed and by whom?
A thorough data inventory enables better planning of masking or obfuscation strategies, ensuring that no sensitive data is overlooked during implementation.
-
Access Controls
Access to sensitive data should be strictly limited to only those individuals who need it to perform their jobs. This involves assigning role-based access permissions, using multi-factor authentication for sensitive systems, and logging and monitoring all data access activities.
Implementing strong access controls reduces the risk of unauthorized data exposure and supports compliance with security regulations.
-
Conduct Regular Audits
Audits help ensure that the data protection methods in place remain effective over time. Organizations should schedule periodic reviews of masking and obfuscation processes to ensure compliance. Assess whether all sensitive data is still being protected as intended.
Verify compliance with data protection policies and external regulations. Audits also help identify any gaps in implementation and enable timely corrective actions.
-
Focus on Employee Training
Even with strong technical controls, human error can lead to data exposure. It is essential to train all employees on the importance of data privacy and security. Educate staff on how data masking and obfuscation work. Provide specific guidelines on data handling in non-production environments.
Ongoing training programs ensure that employees remain aware of their responsibilities and understand how to avoid unintentional data breaches.
-
Tool Selection
Choosing the right tools is vital for an effective data protection strategy. When selecting data masking or obfuscation tools, consider their compatibility with existing data platforms and systems, as well as support for various data types and formats.
Built-in compliance features for GDPR, HIPAA, and other regulations, ease of use, and automation capabilities. The selected tools should align with the organization’s data security objectives and scale as the business grows.
Protect Sensitive Information with Avahi’s Intelligent Data Masking Tool
As part of its commitment to secure and compliant data operations, Avahi’s AI platform provides tools that enable organizations to manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Overview of Avahi’s Data Masker
Avahi’s Data Masker is a versatile data protection tool designed to help organizations securely handle sensitive information across various industries, including healthcare, finance, retail, and insurance.
The tool enables teams to mask confidential data such as account numbers, patient records, personal identifiers, and transaction details without disrupting operational workflows.
Avahi’s Data Masker ensures only authorized users can view or interact with sensitive data by applying advanced masking techniques and enforcing role-based access control. This is especially important when multiple departments or external vendors access data.
Whether protecting patient health information in compliance with HIPAA, anonymizing financial records for PCI DSS, or securing customer data for GDPR, the tool helps organizations minimize the risk of unauthorized access while preserving data usability for development, analytics, and fraud monitoring purposes.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution

At Avahi, we recognize the crucial importance of safeguarding sensitive information while maintaining seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions (FAQs)
1. What is the main difference between data masking and data obfuscation?
Data masking replaces sensitive data with realistic but fictional values for non-production use, while data obfuscation transforms data to make it unintelligible or hard to interpret, often used in both production and transit environments.
2. When should I use data masking instead of data obfuscation?
Data masking is best suited for development, testing, and training environments where real data is not necessary. Use obfuscation when you need to protect live data during processing or transmission without compromising operational flow.
3. Is data masking reversible like encryption?
No, most data masking techniques are irreversible. Unlike encryption or tokenization, masked data cannot be restored to its original form, enhancing security in non-production use cases.
4. Is tokenization considered data masking or data obfuscation?
Tokenization is a form of data obfuscation because it replaces sensitive data with non-sensitive placeholders and allows for retrieval through a secure mapping system.
5. Does data masking comply with GDPR and HIPAA?
Yes, when properly implemented, data masking can help meet data privacy regulations such as GDPR, HIPAA, and PCI DSS by preventing unauthorized access to personally identifiable information (PII).



