
TL;DR
|
Would you trust your most sensitive data in the hands of someone testing a software feature?
You might be doing that if your data protection method isn’t carefully chosen.
According to a 2024 IBM report, nearly 60% of data breaches in non-production environments were caused by using real, unprotected data during testing and development.
While many businesses focus on securing production databases, test environments often become the weakest link, mainly when improper methods like basic scrambling are used without fully understanding the consequences.
Here’s where many teams falter: confusing data scrambling with data masking.
Though both aim to conceal sensitive information, their similarities are only surface-deep. These techniques differ significantly in purpose, protection level, compliance alignment, and practical usability. Misapplying one instead of the other could compromise system integrity, expose sensitive data, or even violate data protection regulations.
So, how do you know which one your business should use?
In this blog, we’ll explore the core differences between data scrambling and data masking, how each technique works, when to use it, and why making the right choice has never been more critical. Whether you’re building software, analyzing customer behavior, or working in a regulated industry, this blog will help you protect your data correctly.
Understanding Data Scrambling: Definition, Types, and Use Cases
Data scrambling is a method used to protect sensitive data by randomly altering its original values. The core goal is to make the data unrecognizable while maintaining its original format and structure (such as string length, data type, or character pattern). Unlike encryption or masking, scrambling does not aim to preserve data usability only the format.
For example, a customer name like “Alex Smith” may be scrambled to something like “mhtiS nhoJ.” The new value is meaningless but looks structurally similar to the original.
How It Works
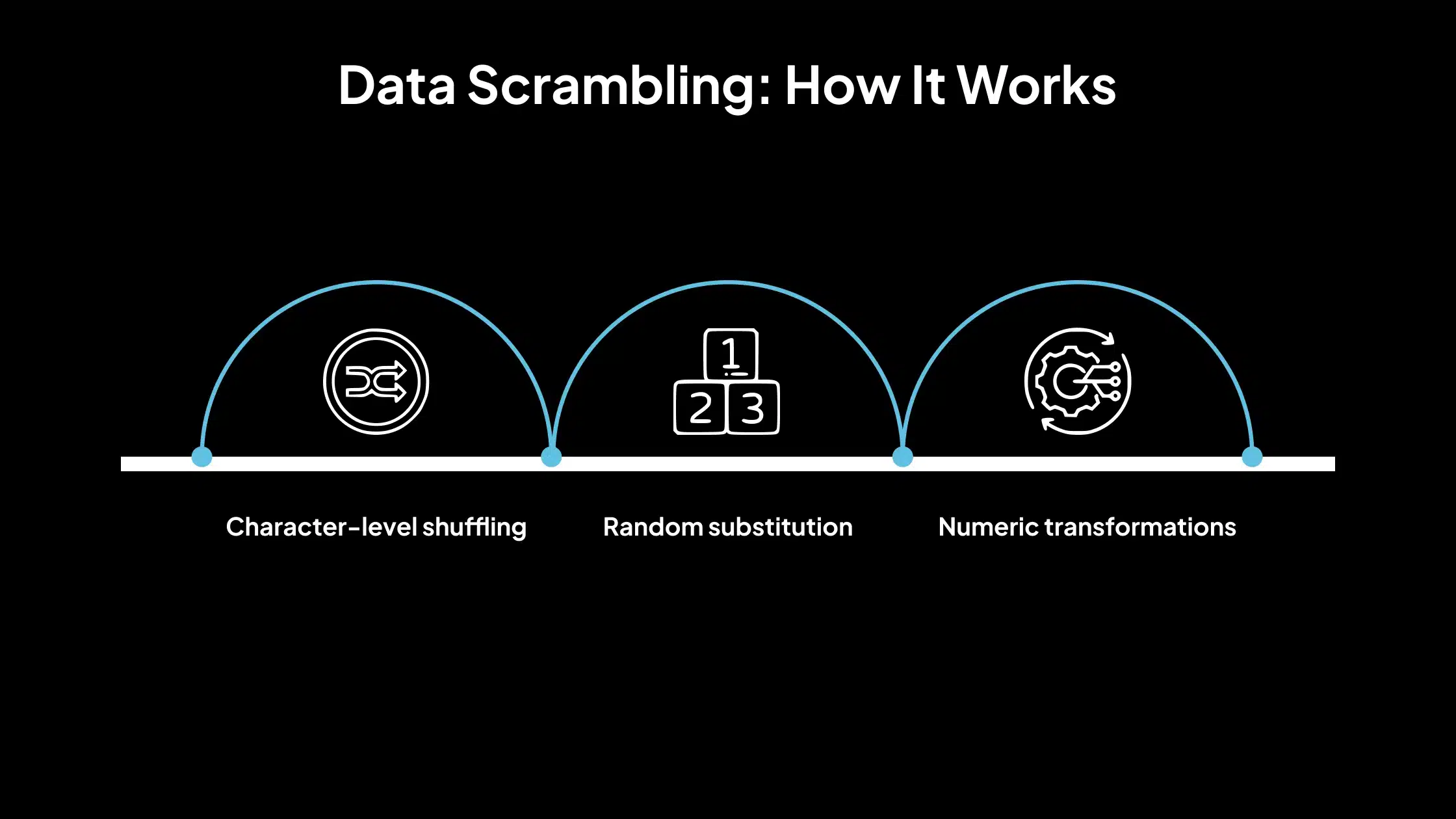
Data scrambling works through randomization techniques that change the actual data while retaining the technical requirements (e.g., length, character type). It is implemented using scripts or tools that apply:
- Character-level shuffling: Rearranges characters within a string randomly.
Example: “Tiger” → “reTgi”
- Random substitution: Replaces characters or digits with others from a predefined set. Example: “54321” → “83917”
- Numeric transformations: Apply arithmetic or pseudo-random changes to numeric fields.
Example: Salary = 60000 → 18429
These methods ensure that the database schema stays intact and no errors occur when the data is used in a testing environment.
Types of Data Scrambling
- Character-Level Scrambling
This method modifies data at the character level within individual fields. The original characters are retained but rearranged randomly. For Example: Original: “David” and Scrambled: “aDvid” or “vDaid”
Format (e.g., 5-letter string) remains the same. It does not preserve any semantic meaning.
It is often used for names, email addresses, or ID fields.
- Field-Level Scrambling
In this type, the scrambling process targets entire field values by substituting them with randomly generated or reshuffled entries.
For example: Original phone number: 98176 and Scrambled phone number: 76189
The numeric or alphanumeric structure is preserved. This is effective for fields like phone numbers, dates, ZIP codes, etc. It is often used where format validation is necessary, but real data isn’t.
Purpose of Data Scrambling
The primary purpose of data scrambling is to obscure sensitive information to prevent data misuse or exposure during internal operations, such as application development, user interface testing, database migrations, and performance/load testing.
It is beneficial when the actual data values are not needed, but the data format and structure must remain valid for application behavior to be realistic.
Pros and Cons of Data Scrambling

Ideal Use Cases
Data scrambling is best suited for non-production environments where data realism is not essential. Common scenarios include:
- Software Testing: Ensures applications work as expected without exposing actual user data.
- UI/UX Prototyping: Designers and developers can populate front-end views without needing real content.
- Database Format Testing: Verifies schema integrity and query logic using structured yet fake data.
- Training Technical Teams: Helps DBAs and developers practice operations on safe, scrambled datasets.
Scrambling should not be used when the data needs to retain real-world relationships or when compliance with data privacy regulations is required.
What is Data Masking? A Smart Solution for Secure, Usable Data
Data masking intentionally replaces sensitive data elements, such as personally identifiable information (PII), financial records, or health details, with realistic but fictitious values. Unlike data scrambling, masked data remains usable and meaningful for testing, training, or development purposes, while protecting its original form from exposure.
For example, the real customer name “Peterson Smith” might be masked as “Michael Davis,” maintaining the same structure and type of data.
How It Works
Data masking works by obfuscating the original data using systematic techniques that preserve format and data relationships. The most common masking methods include:
- Substitution: Replaces actual data with realistic dummy values from a predefined list.
Example: Credit Card = 4532 8890 1123 0009 → 4916 3456 7788 2211
- Shuffling: Randomly reassigning data values within a column to maintain statistical characteristics. An example is swapping ZIP codes between users.
- Tokenization: Replaces sensitive data with non-sensitive tokens that can be reversed via a secure token vault.
- Encryption with Masked Overlay: Encrypts the data and presents only masked versions to unauthorized users.
These methods are implemented using static or dynamic approaches. Static data masking applies masking to a copy of the dataset and is commonly used in non-production environments. Dynamic data masking is applied in real-time based on user access roles without altering the original data.
Types of Data Masking
1. Format-Preserving Masking
This method replaces sensitive data with values that retain the original format (e.g., string length, special characters). This keeps application validations functional without revealing real data.
For example, the original email, alex.jones@example.com, can be masked tomark.green@demo.org
2. Deterministic Masking
The same input always produces the same masked output, useful when consistency across systems or datasets is necessary. It is used for referential integrity across masked databases. For example: Input Alice →is always masked as EEllen at every table.
3. Non-Deterministic Masking
Each instance of the same data can result in a different masked value. For example, Alice → Ellen in one record, Maria in another. This enables higher security at the cost of consistency.
Purpose of Data Masking
Data masking primarily protects sensitive data while retaining its analytical or operational value. It allows organizations to share realistic data with developers, QA testers, analysts, or third-party vendors and comply with privacy regulations (e.g., GDPR, HIPAA, PCI DSS).
It minimizes the risk of data leaks from non-production environments. By masking data, companies can maintain business workflows without compromising security.
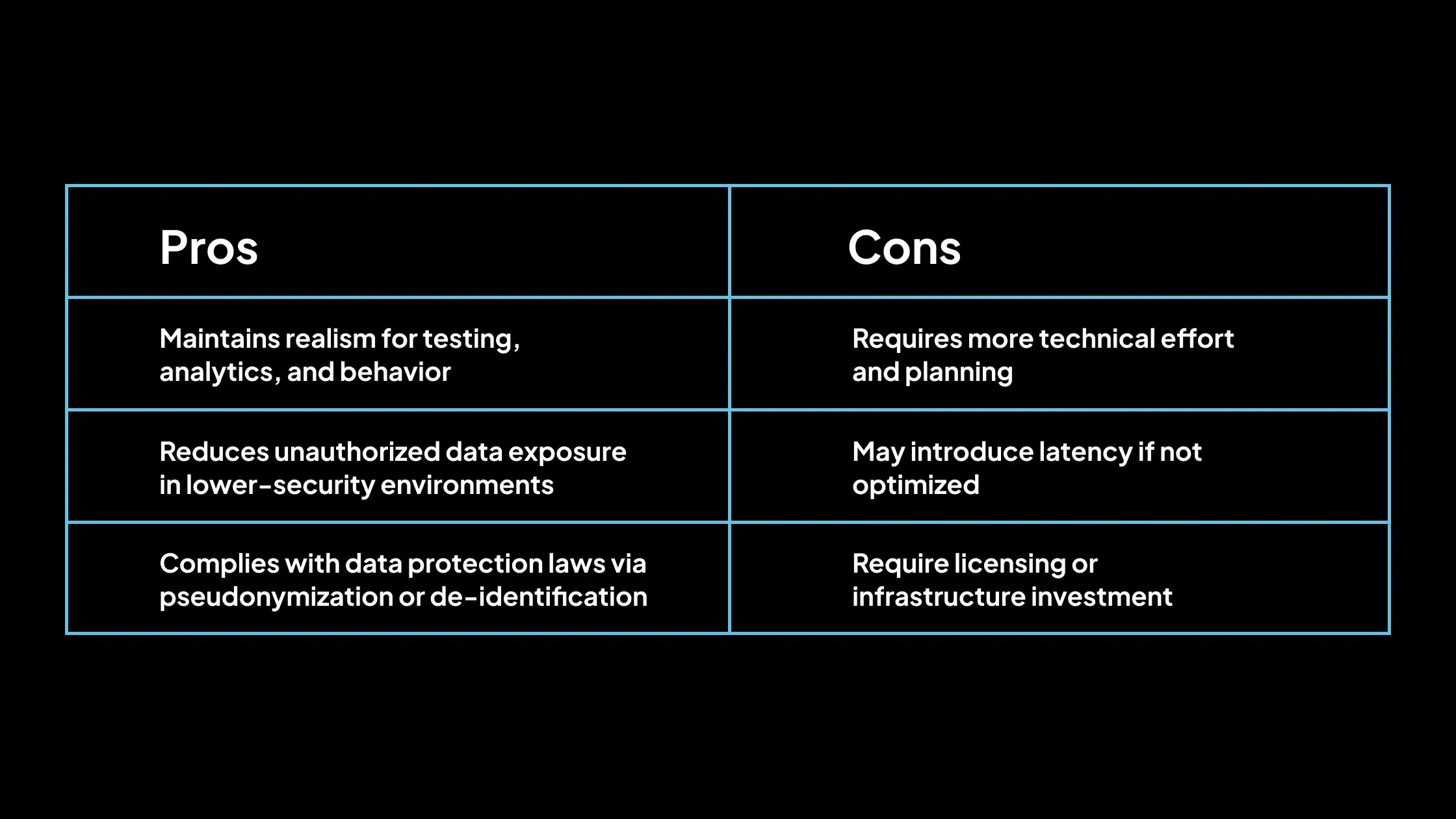
Pros and Cons of Data Masking
Ideal Use Cases
Data masking is preferred when data needs to be realistic, analyzable, and privacy-compliant. Common scenarios include:
- User Acceptance Testing (UAT): Ensures real-world test scenarios with realistic masked data.
- Data Analytics: Analysts can derive insights without accessing true customer identities.
- Training and Education: Helps train internal teams or AI/ML models using meaningful yet safe data.
- Third-party Collaboration: Enables secure data sharing with outsourced vendors, auditors, or consultants.
- Cloud Migration Testing: Protects PII during data transitions from on-premise to cloud environments.
Data masking is significant in industries with strict compliance requirements like finance, healthcare, and insurance.
Data Scrambling vs. Data Masking: Breaking Down the Technical and Practical Differences
Below are the essential points that explain the difference between data scrambling and masking, helping you choose the proper method for your data protection needs.
1. Data Realism
Data Scrambling
Scrambled data does not retain any meaningful resemblance to the original values. The transformation is random, which strips away any contextual or semantic value. This limits the usefulness of scrambled data for realistic simulations, testing workflows that rely on specific patterns, or user behavior modeling.
Data Masking
Masked data is designed to be realistic while protecting sensitive content. Although the data is replaced, the substituted values follow logical patterns and domain constraints (e.g., realistic names, valid email formats). This enables meaningful analysis and functional testing while hiding personal or confidential details.
2. Reversibility
Data Scrambling
Once data is scrambled, it cannot be reverted to its original form. The process is irreversible by design, as no mapping is retained between the original and scrambled values. This makes it unsuitable for scenarios where audibility or data restoration is required.
Data Masking
Data masking can be reversible or irreversible, depending on the method used. For example, tokenization allows for controlled reversibility through secure token vaults, enabling recovery when needed. This flexibility supports use cases that demand both data protection and optional traceability.
3. Compliance Compatibility
Data Scrambling
Data scrambling does not meet the requirements of data protection regulations such as GDPR, HIPAA, or PCI DSS. Since it offers no audit trail, control, or verification of protection measures, it is not considered a compliant method for handling sensitive or regulated data.
Data Masking
Data masking is widely recognized as a compliance-friendly approach. It supports pseudonymization and de-identification, aligning with legal and regulatory frameworks. Properly implemented masking techniques help organizations fulfill security, privacy, and audit requirements.
4. Complexity
Data Scrambling
Scrambling is relatively simple to implement. It usually involves lightweight scripts or basic database functions that randomize characters or values. It requires minimal setup and is often used when data security is not the primary concern.
Data Masking
Masking introduces more complexity due to preserving data integrity, consistency, and realism. It may require specialized tools, format-preserving transformation rules, and role-based access control integration. This added complexity supports broader use cases and compliance needs.
5. Use Case Suitability
Data Scrambling
It is best suited for early-stage development or testing environments where only the data structure needs to be validated. It is ideal when realistic content is not required and the goal is to protect original values from being exposed.
Data Masking
It is better suited for functional testing, analytics, user training, or third-party data sharing where the data must look and behave like real data. It supports complex scenarios like performance testing, AI training, or integration testing across systems with referential integrity.
6. Security
Data Scrambling
This provides a basic level of data protection by removing identifiable information. However, its security strength is moderate and insufficient for high-risk environments because it lacks reversibility, control mechanisms, or context-aware transformations.
Data Masking
It offers a stronger level of data security, particularly when implemented with structured methods like dynamic masking, tokenization, or role-based masking policies. It prevents unauthorized access while allowing legitimate operations on safe, de-identified data.

Data Scrambling vs. Data Masking: Compliance and Regulatory Considerations
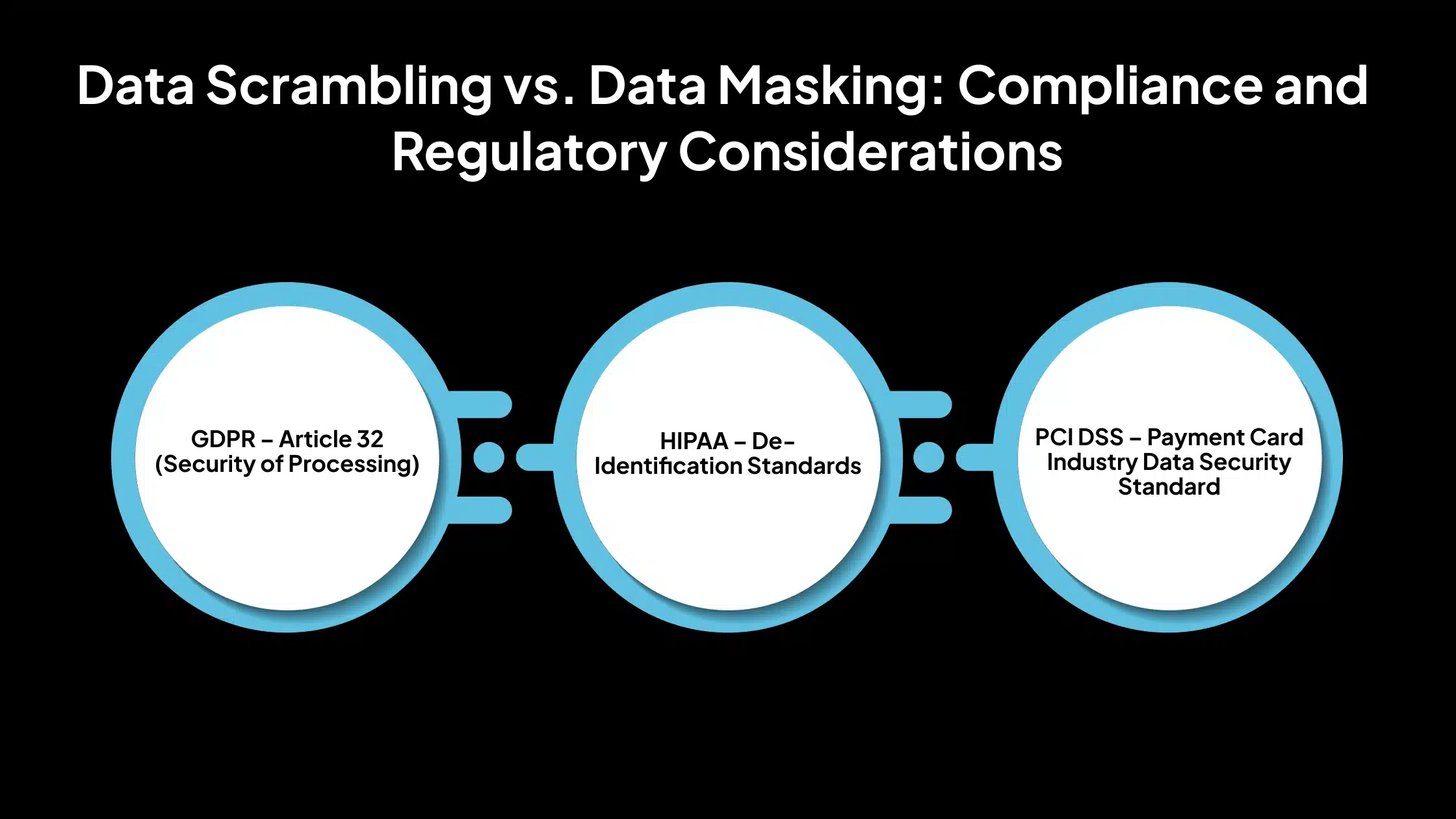
Protecting sensitive data is a security best practice and a legal requirement in many industries. Regulations such as GDPR, HIPAA, and PCI DSS mandate specific controls around how personal and sensitive information is stored, processed, and shared. In this context, data masking is often the preferred method for meeting these requirements, while data scrambling falls short. Here is why data masking is favored for compliance:
1. GDPR – Article 32 (Security of Processing)
Article 32 of the General Data Protection Regulation (GDPR) requires organizations to implement appropriate technical and organizational measures to protect personal data. One such recommended measure is pseudonymization, which involves replacing identifiable data with substitute values that do not directly reveal the individual’s identity.
GDPR data masking techniques align well with this requirement by:
- Replacing real data with realistic but fictitious values.
- Allowing organizations to process and analyze data without exposing real identities.
- Supporting controlled reversibility when necessary, such as through secure tokenization.
These techniques help maintain data usability while reducing privacy risks. In contrast, data scrambling lacks control, auditability, and reversibility, making it unsuitable for meeting GDPR requirements. It offers no assurance that the transformation was performed according to compliance standards or that data relationships were preserved.
2. HIPAA – De-Identification Standards
The Health Insurance Portability and Accountability Act (HIPAA) in the U.S. defines strict rules for protecting Protected Health Information (PHI). PHI must be de-identified using specific rules or protected through secure handling. Data masking supports HIPAA compliance by:
- Removing direct identifiers (e.g., names, Social Security numbers).
- Maintaining realistic datasets for healthcare analytics or testing.
- Enabling expert-determined de-identification methods when required.
Scrambled data lacks controlled methods to ensure identifiers are entirely removed or replaced based on defined standards.
3. PCI DSS – Payment Card Industry Data Security Standard
PCI DSS applies to any organization handling credit card information. It mandates the protection of cardholder data through techniques such as masking or truncation.
Data masking aligns with these rules by:
- Hiding or replacing sensitive portions of the card number.
- Ensuring that masked data cannot be used for fraud.
- Maintaining the data format for testing or user interfaces.
Scrambled data cannot ensure that the correct parts of the card data are protected and often fails to meet the format and visibility requirements of PCI DSS.
Risks of Using Scrambled Data in Compliance Scenarios
Scrambling does not track or log how data is altered. Since the process is random and non-reversible, there is no way to prove how the data was transformed. This lack of documentation and control makes it unsuitable for audits or regulatory reviews.
Scrambled data may look different, but it does not follow standard de-identification rules. Some sensitive data elements may remain partially exposed or identifiable without structured methods to remove or mask identifiers, creating potential compliance gaps and increasing the risk of data leaks.
Data handling must be deliberate, traceable, and aligned with legal standards in regulated environments. Data masking provides structured protection, controlled reversibility (if needed), and supports industry-specific compliance frameworks. Data scrambling, while simple, does not offer the control, auditability, or assurance required for handling sensitive or regulated data.
Data Scrambling vs. Data Masking: Choosing the Right Technique for Your Business
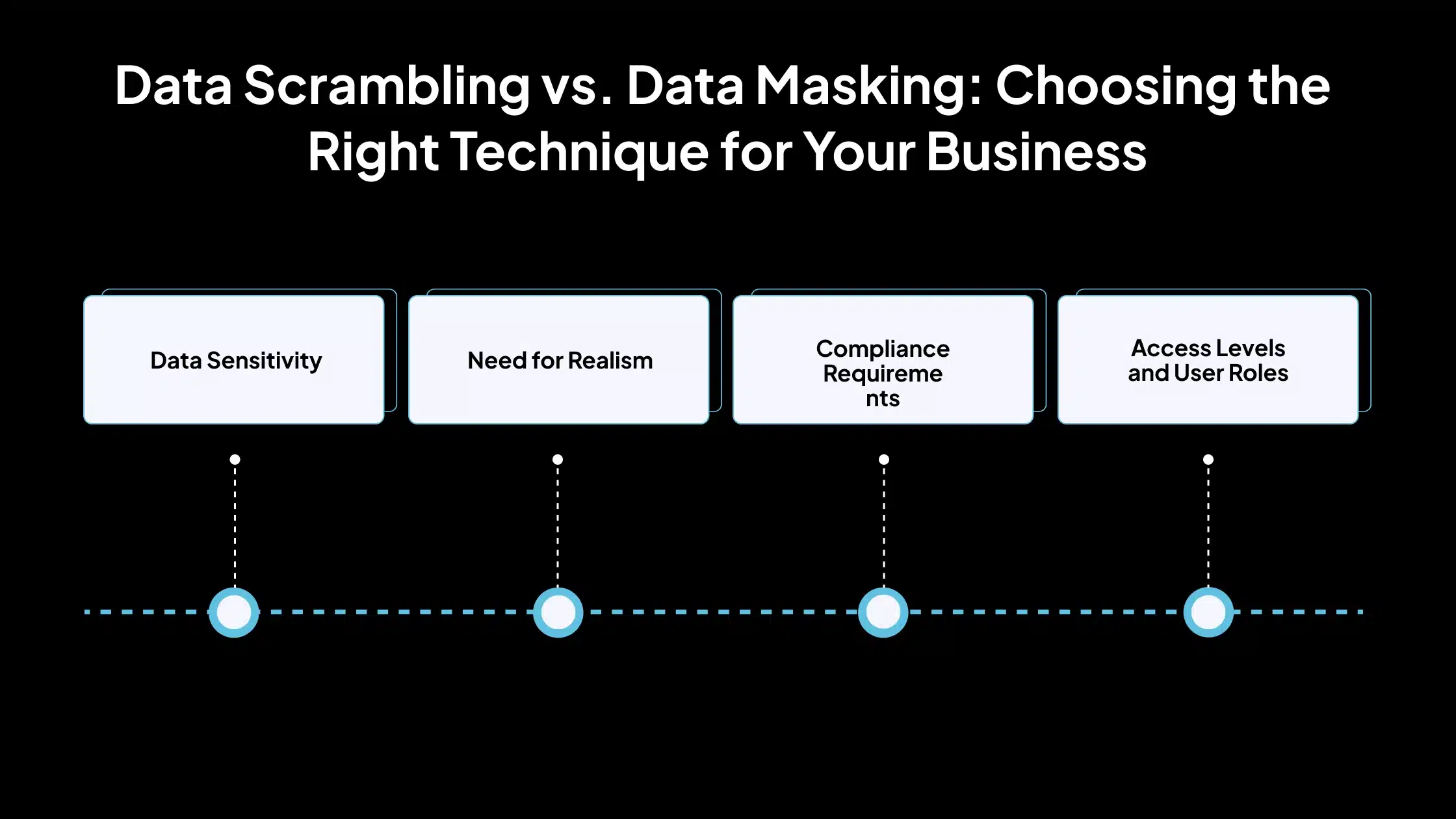
Selecting between data scrambling and data masking depends on your business goals, the nature of the data, and the risks involved. Each method serves different purposes and suits various environments. Below are the factors to consider when deciding which technique to use.
1. Data Sensitivity
Masking is preferred if the dataset contains personally identifiable information (PII), health records, payment details, or regulated data due to its structured protection and compliance compatibility.
Scrambling may be sufficient if the dataset is non-sensitive or requires format preservation (not content realism).
2. Need for Realism
Choose data masking if the data must look realistic for testing, training, user interface validation, or analytics.
Choose scrambling if realism is unnecessary and only structural compatibility (e.g., the same data type and length) is required.
3. Compliance Requirements
Use data masking if your organization must comply with GDPR, HIPAA, PCI DSS, or similar standards. It supports de-identification, pseudonymization, and secure access controls.
Scrambling is unsuitable for compliance-related environments as it lacks traceability and standards-based implementation.
4. Access Levels and User Roles
If the data will be accessed by external vendors, third-party developers, analysts, or testers, use data masking to ensure safety without exposing actual values.
Scrambling may be acceptable if access is limited to internal development teams and the data is only for preliminary testing.
Tools for Data Masking and Scrambling: Powering Secure Data Transformation
Businesses often rely on dedicated tools and platforms to implement data protection effectively, which provides automation, policy controls, and integration with existing systems. Below are commonly used tools for both data masking and scrambling:
Data Masking Tools
These tools are designed to support compliance, preserve data relationships, and offer masking rules that can be applied at scale.
- Informatica Dynamic Data Masking: It supports both static and dynamic masking. It offers pre-built masking rules for PII, financial, and healthcare data. It is suitable for large enterprises with regulatory needs.
- Delphix: It provides real-time, on-the-fly data masking and maintains referential integrity across systems. It is commonly used for DevOps and continuous integration environments.
- Oracle Data Masking and Subsetting: This tool offers database-native masking for Oracle environments. It includes built-in templates for masking different data types and supports data subsetting for smaller masked datasets.
- IBM Optim: It specializes in enterprise-scale data masking and archiving. It is designed for structured and unstructured data. It is an integrated role-based access and compliance reporting.
Data Scrambling Tools
Data scrambling is generally implemented through simpler solutions, often using internal tools or native features in database systems.
- Custom Scripts: Developers often use Python, SQL, or shell scripts to shuffle or randomize data values. These scripts are simple to implement but limited in control and compliance.
- Database-Native Options: SQL Server and Oracle databases offer basic functions (e.g., NEWID(), DBMS_RANDOM) to scramble strings, numbers, or rows. This makes them suitable for quick data obfuscation in test environments without compliance requirements.
For regulated industries, prioritize platforms like Informatica, Delphix, or IBM Optim that offer complete control, reporting, and compliance support. For internal, low-risk environments, custom scripts or native database functions may be sufficient for scrambling purposes.
Why Choose Avahi Data Masker: Streamlined, Scalable, and Secure Data Masking
As part of its commitment to secure and compliant data operations, Avahi’s AI platform offers tools that help organizations manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Avahi Data Masker is built for organizations that must handle sensitive information securely without compromising operational efficiency. It offers a structured, AI-powered approach to data masking, ensuring that confidential fields, such as personal identifiers, financial records, and health data, are protected while remaining usable for internal processes like analytics, development, and testing. Here are the reasons to choose Avahi Data Masker:
- Cross-Industry Compliance Support: Enables secure data handling across healthcare (HIPAA), finance (PCI DSS), retail, and other regulated sectors.
- Role-Based Access Control: Restricts data visibility to authorized users, ensuring sensitive data is protected during multi-team or vendor access.
- AI-Powered Masking Logic: Uses intelligent algorithms to identify and mask sensitive fields without altering data structure or usability.
- Simple, Guided Workflow: A user-friendly interface streamlines the process from file upload to secure output.
- Data Usability Post-Masking: Masked data retains its format, supporting downstream tasks such as reporting, fraud detection, or test environments.
This functionality ensures data security, regulatory alignment, and operational continuity in one solution.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution

At Avahi, we understand the critical importance of safeguarding sensitive information while ensuring seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions
1. What is the difference between data scrambling and data masking?
Data scrambling randomly alters values while maintaining the data’s structure, making it unusable but technically valid. On the other hand, data masking replaces sensitive data with realistic, fictitious values that are still useful for testing, analytics, or training. While scrambling is irreversible and non-compliant with regulations, masking sometimes supports compliance, realism, and even reversibility.
2. Is data scrambling compliant with regulations like GDPR or HIPAA?
Data scrambling is generally not compliant with privacy regulations like GDPR, HIPAA, or PCI DSS. It lacks auditability, traceability, and structured control. In contrast, data masking supports de-identification and pseudonymization, making it the preferred choice for organizations operating in regulated industries.
3. When should a business use data masking instead of data scrambling?
A business should use data masking when the data needs to look and behave like real data, especially in testing, analytics, user training, or third-party data sharing. It is ideal for situations requiring compliance, data realism, and controlled access, whereas data scrambling should be used only for internal testing where structure matters more than content.
4. Can data scrambling and masking be used in a data protection strategy?
Some organizations combine data scrambling and data masking based on the environment and data sensitivity. Scrambling might be used for early-stage development, while masking is applied where realism, compliance, and controlled access are required, such as user acceptance testing or third-party collaboration.
5. Is data masking reversible?
Data masking can be either reversible or irreversible, depending on the method. For example, tokenization allows for secure reversibility using a token vault, while substitution or shuffling is often irreversible. This flexibility will enable businesses to choose based on data access and audit needs.



