

TL;DR
|
Modern engineering teams are not failing because they lack tools; they are struggling because their operations have become too complex to manage manually.
As systems scale, infrastructure grows, and software architectures become more distributed, operational workloads increase dramatically. Engineers spend more time responding to alerts, troubleshooting deployments, and managing infrastructure than actually building new ones capabilities.
The result is a growing operational burden across engineering and DevOps teams.
Engineers spend 30–40% of their time on operational toil, such as debugging, monitoring, and incident response. Cloud waste accounts for nearly 30% of infrastructure spending due to idle or overprovisioned resources.
These inefficiencies do more than increase operational costs. They slow down innovation, reduce engineering productivity, and make it harder for teams to maintain reliable systems at scale.
Although automation was designed to address some of these problems, it has clear limitations. Most automation relies on static scripts and predefined workflows, which still require human intervention whenever conditions change.
This is where Agentic AI is starting to reshape engineering and operational environments.
Agentic AI introduces systems that can detect issues, analyze system behavior, make decisions, and autonomously execute operational tasks. Instead of relying on engineers to manually investigate alerts or coordinate workflows across multiple tools, AI agents can manage many of these processes independently.
In this blog, you will explore how agentic AI reduces operational costs across engineering and operations, the core mechanisms behind this shift, and the practical ways organizations are beginning to adopt autonomous operational systems.
Understanding Agentic AI and Its Role in Modern Engineering Operations
If you manage engineering systems, DevOps pipelines, or operational infrastructure, you already rely on automation. Scripts trigger builds, alerts notify teams, and workflows handle routine tasks. But most of this automation still depends on predefined rules and human intervention when something unexpected happens.
This is where Agentic AI introduces a fundamental shift.
Agentic AI refers to AI systems that can reason, plan, and execute tasks independently with minimal human supervision. Instead of simply following fixed instructions, these systems work toward a goal. They analyze situations, decide on actions, and execute multi-step workflows across multiple tools and systems.
For engineering and operations teams, this shift changes how work gets done. Instead of writing more scripts or manually investigating alerts, you can deploy systems that:
- Investigate incidents automatically.
- Coordinate remediation actions across tools.
- Optimize infrastructure decisions in real time.
- Reduce the need for constant manual oversight.
In other words, you move from automation that executes tasks to AI agents that manage operational outcomes. This distinction is what makes agentic AI a foundational capability for modern engineering and operations environments.
Where Operational Costs Come From in Engineering and Operations

If you are responsible for engineering systems, DevOps workflows, or platform operations, you already know that operational costs rarely come from a single source. Most of the expense comes from small inefficiencies that accumulate across infrastructure, tooling, and daily engineering work. Below are the most common cost drivers across engineering and operations environments.
1. Incident Response and Firefighting
Operational incidents are one of the largest hidden cost drivers for engineering teams. Every production issue requires engineers to investigate alerts, analyze logs, coordinate responses, and restore system stability.
In many organizations, this process remains highly manual. Engineers often spend hours reviewing logs, tracing service dependencies, and identifying the root cause of failures.
High Mean Time to Resolution (MTTR) increases operational costs because incidents consume engineering hours and can also affect customer experience or service availability. At the same time, constant monitoring alerts create alert fatigue, making it harder for teams to identify the issues that truly require attention.
Over time, repeated firefighting reduces engineering efficiency and increases operational overhead.
2. Infrastructure Inefficiencies
Infrastructure is another major contributor to operational spending, especially in cloud-based environments.
To avoid performance issues, teams often overprovision compute, storage, and networking resources. While this approach reduces the risk of outages, it frequently leads to underutilized infrastructure.
Idle workloads, unused instances, and inefficient resource allocation can quietly increase cloud costs month after month. Without continuous optimization, infrastructure expenses grow even when system usage remains stable. For many organizations, this results in paying for capacity that is rarely used.
3. Manual DevOps Workflows
DevOps practices aim to streamline software delivery, but many workflows still require manual intervention. Engineering teams frequently spend time troubleshooting failed CI/CD pipelines, investigating build errors, and resolving deployment conflicts. Configuration drift across environments can also introduce operational complexity, requiring teams to repeatedly verify and correct system configurations.
These manual DevOps activities may appear small individually, but collectively they consume a significant portion of engineering time. As systems scale, maintaining pipelines and infrastructure configurations becomes an ongoing operational burden.
4. Operational Fragmentation
Modern engineering environments rely on a large number of tools. Monitoring platforms, observability systems, logging solutions, incident management tools, and ticketing platforms often operate independently.
While each tool solves a specific problem, the lack of integration between them creates operational fragmentation. Engineers must switch between multiple dashboards, manually correlate data, and piece together insights from different systems.
Data silos across observability, monitoring, and incident management tools slow and complicate troubleshooting. As a result, teams spend more time gathering information before they can take action. This fragmentation increases both operational complexity and operational cost.
5. Engineering Productivity Loss
Highly skilled developers and platform engineers frequently spend large portions of their time on operational work such as investigating alerts, reviewing logs, responding to incidents, or maintaining infrastructure.
While these tasks are necessary, they often prevent engineers from focusing on higher-value work such as building features, improving product performance, or developing new capabilities.
Over time, this shift from innovation to maintenance slows down development velocity and increases the overall cost of engineering operations.
The Agentic AI Cost Reduction Framework for Engineering and Operations
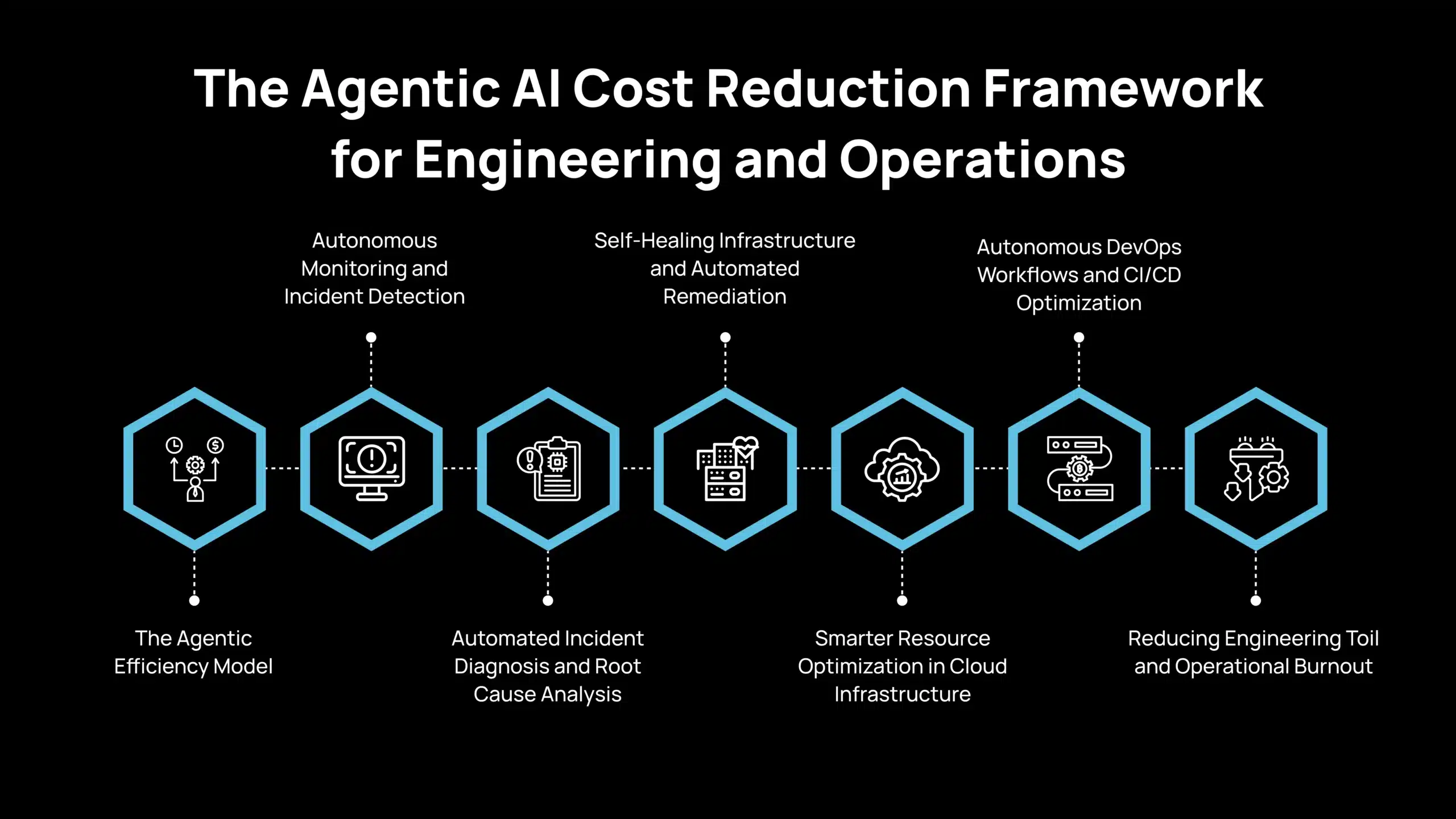
Agentic AI introduces a structured approach to reduce this overhead. Instead of simply automating tasks, it allows systems to detect issues, investigate problems, execute remediation, and optimize operations autonomously. Here is the detailed framework that the engineering and operations team can follow:
1. The Agentic Efficiency Model
At its core, the model focuses on progressively shifting operations from reactive human work to autonomous system management. Autonomous detection ensures systems continuously monitor infrastructure and services without waiting for engineers to review alerts.
Intelligent diagnosis enables AI agents to automatically investigate incidents and determine likely root causes. Self-healing remediation enables systems to resolve common operational failures without human intervention.
Workflow orchestration connects tools across the DevOps stack, enabling operational taskston run end-to-end automatically. Continuous optimization ensures infrastructure and operational processes improve over time based on real system data.
To simplify the framework, think of it as a layered operational capability:
- Detect problems automatically
- Diagnose issues without manual investigation.
- Resolve incidents through automated remediation.
- Coordinate workflows across systems.
- Continuously improve operational efficiency.
When these layers work together, the result is fewer manual interventions, faster incident response, and lower operational costs.
2. Autonomous Monitoring and Incident Detection
One of the earliest operational improvements from agentic AI comes from smarter monitoring.
Regular monitoring systems generate thousands of alerts across infrastructure, applications, and services. Engineers must constantly review these alerts to determine which ones represent real issues. Over time, this leads to alert fatigue and slower incident response.
Agentic AI changes how monitoring works. Instead of relying on static thresholds, AI agents continuously analyze telemetry data, correlate signals across systems, and detect unusual behavior patterns. This allows your systems to identify issues before they escalate into production incidents.
AI monitoring agents perform tasks such as:
- Analyzing telemetry across infrastructure and applications
- Correlating signals across multiple observability tools
- Detecting anomalies in real time
- Identifying early warning signals of system instability
As a result, monitoring becomes more proactive and far less noisy. Operational benefits include earlier detection of system issues, fewer false alerts reaching engineers, and faster incident resolution cycles. This results in reduced system downtime and lower incident management overhead.
3. Automated Incident Diagnosis and Root Cause Analysis
Once an incident occurs, the next major operational cost comes from investigation.
Engineers typically spend hours analyzing logs, tracing service dependencies, and reviewing recent deployments to determine the cause of the failure. This manual triage process slows down recovery and consumes valuable engineering time.
Agentic AI dramatically accelerates this stage by performing automated incident analysis.
AI agents investigate issues by simultaneously evaluating multiple operational data sources.
These agents:
- Analyze application and infrastructure logs
- Trace dependencies across microservices
- Review recent deployments or configuration changes.
- Correlate metrics across observability systems
By combining these signals, agentic systems can quickly identify probable root causes.
In many environments, AI-driven observability tools have reduced time-to-insight dramatically compared to traditional investigation methods.
These capabilities significantly improve operational efficiency. By automating incident investigation and log analysis, teams can identify root causes faster and reduce the time spent on manual triage. This leads to lower Mean Time to Resolution (MTTR), fewer engineering hours spent troubleshooting, and faster recovery during production incidents.
4. Self-Healing Infrastructure and Automated Remediation
Self-healing systems represent one of the most powerful cost-reduction capabilities of agentic AI.
Once an issue is detected and diagnosed, AI agents can automatically execute corrective actions. Instead of waiting for engineers to respond to alerts, the system attempts to resolve the issue immediately.
Typical remediation actions include:
- Restarting failed services
- Rolling back faulty deployments
- Scaling infrastructure resources
- Fixing configuration inconsistencies
These automated responses allow systems to recover quickly without requiring manual intervention. In large distributed environments, self-healing capabilities significantly reduce operational workload and improve reliability.
These capabilities reduce the need for manual troubleshooting while enabling faster recovery from system failures. As a result, infrastructure becomes more resilient, operational overhead decreases, downtime costs are minimized, and overall system uptime improves.
5. Smarter Resource Optimization in Cloud Infrastructure
For many organizations, cloud infrastructure represents the largest operational expense.
To prevent outages or performance issues, teams often provision more resources than necessary. Over time, this leads to underutilized infrastructure and increasing cloud bills.
Agentic AI introduces continuous infrastructure optimization. AI agents analyze workload patterns, infrastructure metrics, and system performance to determine how resources should be allocated. Based on this data, they can dynamically adjust infrastructure capacity.
Examples of optimization actions include:
- Dynamically scaling compute resources
- Shutting down idle workloads
- Redistributing workloads across regions
- Optimizing compute and storage utilization
Instead of relying on periodic manual reviews, infrastructure efficiency becomes an ongoing automated process.
These improvements help organizations use infrastructure resources more efficiently while reducing the need for constant manual monitoring. As a result, systems maintain better alignment between usage and capacity, leading to lower cloud spending, improved infrastructure efficiency, and reduced operational complexity.
6. Autonomous DevOps Workflows and CI/CD Optimization
DevOps pipelines are designed to accelerate software delivery, but they still require frequent maintenance and troubleshooting.
Build failures, test issues, and deployment errors often require engineers to intervene and diagnose problems within the CI/CD pipeline. Agentic AI improves this process by automating many DevOps workflows.
AI agents can integrate with CI/CD systems, monitoring tools, and infrastructure platforms to automate pipeline actions.
Examples include:
- Analyzing failed builds to identify root causes
- Rerunning only the tests that failed
- Triggering new deployments after fixes
- Optimizing release pipelines across environments
By coordinating across DevOps tools, agentic AI agents ensure that workflows continue to run smoothly without constant supervision. These improvements enable faster and more reliable software releases while reducing pipeline failures and the time spent maintaining DevOps workflows. As a result, organizations benefit from faster development cycles, lower operational maintenance effort, and improved engineering efficiency.
7. Reducing Engineering Toil and Operational Burnout
A major hidden cost in engineering organizations is engineering toil.
Toil refers to repetitive operational work that engineers must perform regularly but does not directly contribute to product innovation. Examples include:
- Manual log analysis
- Routine debugging tasks
- Repetitive system health checks
- Incident ticket triage
While necessary, these tasks consume engineering capacity that could otherwise be spent on building features or improving system architecture.
Agentic AI helps eliminate much of this repetitive work by automating operational processes.
Instead of responding to routine operational issues, engineers can focus on higher-value initiatives.
Practical Steps to Implement Agentic AI in Engineering Operations
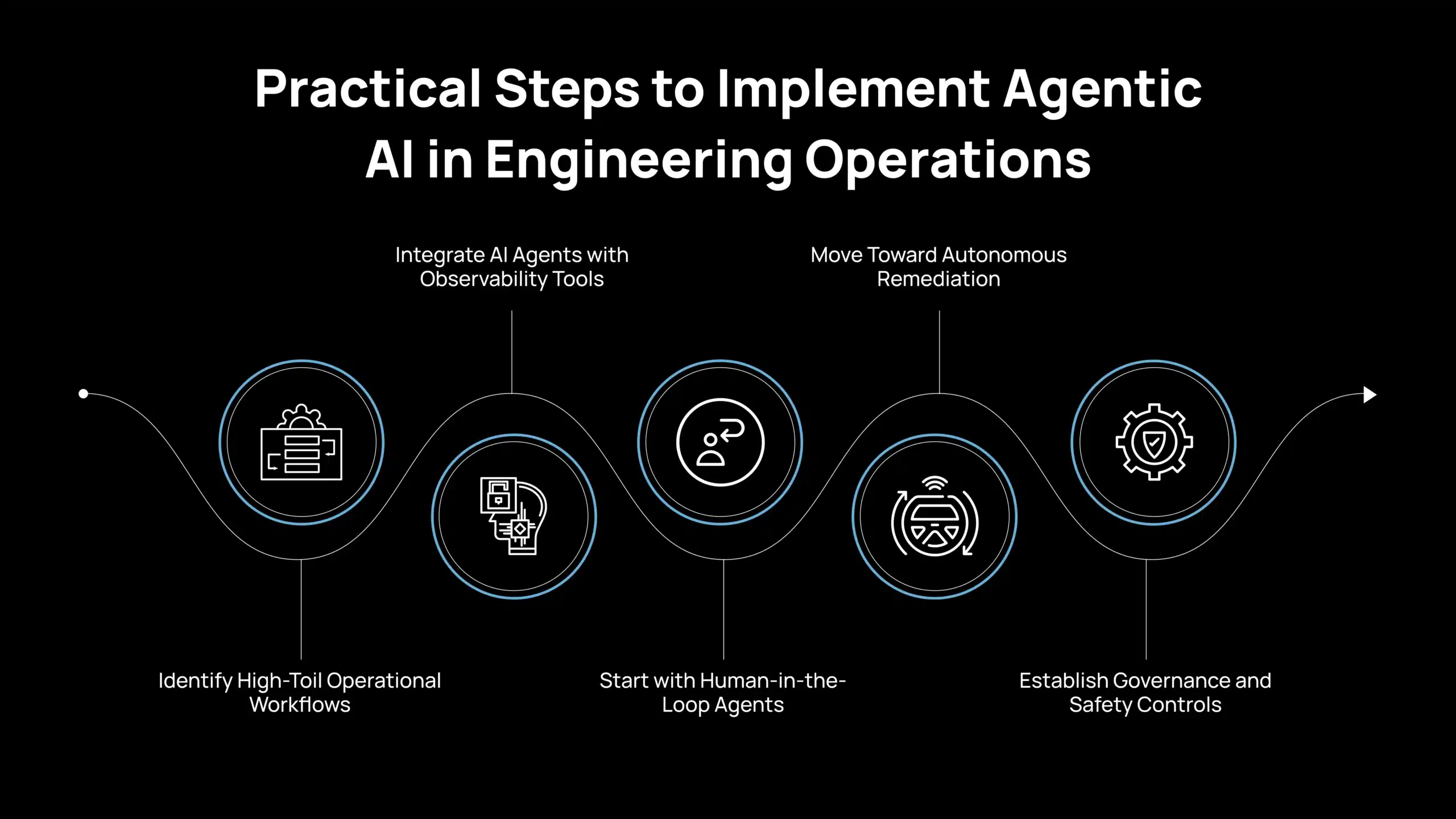
Below is a practical implementation path many engineering teams follow.
Step 1: Identify High-Toil Operational Workflows
Start by identifying operational tasks that consume the most engineering time but deliver limited strategic value. These are often repetitive processes that can benefit the most from intelligent automation. Common high-toil workflows include:
- Incident triage and alert investigation
- Debugging deployment failures
- Monitoring infrastructure alerts
- Log analysis and troubleshooting.
- Ticket triage in incident management systems
By focusing on these workflows first, you can quickly reduce operational overhead while demonstrating measurable value from agentic AI.
Step 2: Integrate AI Agents with Observability Tools
Agentic systems rely heavily on operational data. To function effectively, AI agents need access to signals from your observability stack. Start by integrating agents with systems such as:
- Monitoring platforms
- Logging and telemetry tools
- Infrastructure metrics systems
- Incident management platforms
This allows AI agents to analyze system behavior, correlate signals, and detect operational anomalies in real time.
Step 3: Start with Human-in-the-Loop Agents
In the early stages, it is important to maintain human oversight. Human-in-the-loop systems allow AI agents to recommend actions or prepare remediation steps, while engineers review and approve them before execution. This approach helps teams:
- Build confidence in AI-driven decisions
- Validate the accuracy of automated diagnosis.
- Reduce operational risk during early adoption.
Over time, teams can gradually increase the autonomy of these systems.
Step 4: Move Toward Autonomous Remediation
Once the system demonstrates reliable performance, you can begin enabling automated remediation for well-understood operational scenarios. Examples include:
- Restarting failed services automatically
- Rolling back problematic deployments
- Scaling infrastructure during traffic spikes
- Resolving known configuration issues
At this stage, AI agents begin handling routine operational incidents without requiring manual intervention.
Step 5: Establish Governance and Safety Controls
As autonomous systems become more active in production environments, governance becomes critical. Organizations should implement clear guardrails to ensure agentic AI operates safely and transparently. Important governance practices include:
- Policy-based automation controls
- Observability for AI agent actions
- Audit trails for automated decisions
- Security and access management policies
Strong governance ensures that agentic AI improves operational efficiency while maintaining reliability and compliance across engineering systems.
How Avahi Helps You Turn AI Into Real Business Results?

If your goal is to apply AI in practical ways that deliver measurable business impact, Avahi offers solutions designed specifically for real-world challenges. Avahi enables organizations to quickly and securely adopt advanced AI capabilities, supported by a strong cloud foundation and deep AWS expertise.
Avahi AI solutions deliver business benefits such as:
- Round-the-Clock Customer Engagement
- Automated Lead Capture and Call Management
- Faster Content Creation
- Quick Conversion of Documents Into Usable Data
- Smarter Planning Through Predictive Insights
- Deeper Understanding of Visual Content
- Effortless Data Access Through Natural Language Queries
- Built-In Data Protection and Regulatory Compliance
- Seamless Global Communication Through Advanced Translation and Localization
By partnering with Avahi, organizations gain access to a team with extensive AI and cloud experience committed to delivering tailored solutions. The focus remains on measurable outcomes, from automation that saves time and reduces costs to analytics that improve strategic decision-making to AI-driven interactions that elevate the customer experience.
Discover Avahi’s AI Platform in Action

At Avahi, we empower businesses to deploy advanced Generative AI that streamlines operations, enhances decision-making, and accelerates innovation, all with zero complexity.
As your trusted AWS Cloud Consulting Partner, we empower organizations to harness the full potential of AI while ensuring security, scalability, and compliance with industry-leading cloud solutions.
Our AI Solutions Include
- AI Adoption & Integration – Leverage Amazon Bedrock and GenAI to Enhance Automation and Decision-Making.
- Custom AI Development – Build intelligent applications tailored to your business needs.
- AI Model Optimization – Seamlessly switch between AI models with automated cost, accuracy, and performance comparisons.
- AI Automation – Automate repetitive tasks and free up time for strategic growth.
- Advanced Security & AI Governance – Ensure compliance, detect fraud, and deploy secure models.
Want to unlock the power of AI with enterprise-grade security and efficiency?
Start Your AI Transformation with Avahi Today!
Frequently Asked Questions
1. How does the cost reduction of agentic AI impact engineering operations at scale?
Agentic AI cost reduction helps organizations lower operational expenses by automating monitoring, incident diagnosis, and remediation. AI agents handle routine operational tasks, allowing engineering teams to manage complex systems more efficiently while reducing manual workload and infrastructure inefficiencies.
2. Why should CTOs prioritize cost-reduction strategies for agentic AI?
CTOs should prioritize cost reduction in agentic AI because operational complexity and cloud costs continue to rise. By automating repetitive operational processes, agentic AI improves system reliability, reduces engineering toil, and allows teams to focus on innovation rather than ongoing operational maintenance.
3. How does agentic AI improve operational efficiency for engineering teams?
Agentic AI improves efficiency by automatically detecting issues, analyzing system behavior, and triggering remediation actions across operational tools. This reduces the time engineers spend on troubleshooting and incident management while improving response speed.
4. Which operational areas benefit most from the adoption of agentic AI?
The biggest benefits typically appear in incident response, infrastructure optimization, monitoring, and DevOps workflows. Automating these areas helps organizations improve reliability while lowering operational costs.
5. What should CTOs consider before implementing agentic AI in engineering operations?
CTOs should first identify high-effort operational workflows and ensure their observability systems provide reliable data. Most organizations start with human-in-the-loop automation before gradually enabling autonomous remediation for routine operational tasks.



