
TL;DR
|
Every 39 seconds, a cyberattack hits a business.
In an environment where sensitive data fuels everything from customer insights to financial operations, a single breach can disrupt trust, trigger regulatory fines, and damage reputation, often beyond repair.
As data breaches increase in frequency and severity, organizations are under immense pressure to secure personal and transactional information. Two of the most widely adopted techniques in data protection today are data tokenization and data masking. Both serve a common goal, safeguarding sensitive data, but they work in fundamentally different ways, and choosing the wrong one for the wrong context can leave critical gaps.
This blog breaks down the difference between tokenization vs data masking, explaining how each method works, when to use them, and how they align with the regulatory framework.s
Whether protecting credit card information in a payment system or anonymizing patient records for analysis, understanding the strengths and limitations of each is the first step toward building a stronger, smarter data defense.
Understanding Data Tokenization: Definition, Types, Use Cases, and Benefits
Data tokenization is a data security technique that replaces sensitive information, such as credit card numbers, social security numbers, or personal identifiers, with non-sensitive placeholders called tokens.
These tokens are randomly generated values with no meaningful relationship to the original data. Importantly, the original data is stored securely in a separate system known as a token vault, which maps tokens back to their real values when authorized systems need them.
The essential feature of tokenization is that the format of the original data is preserved. For instance, a 16-digit credit card number might be replaced with another 16-digit token that resembles a valid card number but holds no value outside the system.
Type of Data Tokenization
1. Vaulted Tokenization
In vaulted tokenization, a secure database, often called a token vault, stores the relationship between the original sensitive data and its corresponding token.
When sensitive data needs tokenized, it is sent to the vault, which generates a unique token and stores the mapping. Access to the vault is strictly controlled; only authorized systems can retrieve the original data using the token.
2. Vaultless Tokenization
Vaultless tokenization eliminates the need for a central database by using algorithms to generate tokens. These algorithms can deterministically produce the same token for a given input, allowing token generation and reversal without storing the original data.
This enhances scalability and reduces latency, making it suitable for high-performance applications.
3. Format-Preserving Tokenization
Format-preserving tokenization ensures that the generated tokens maintain the same format and length as the original data.
For example, a 16-digit credit card number would be replaced with another 16-digit token. This preservation allows systems to process tokenized data without requiring significant changes to existing infrastructure.
Advantages of Data Tokenization
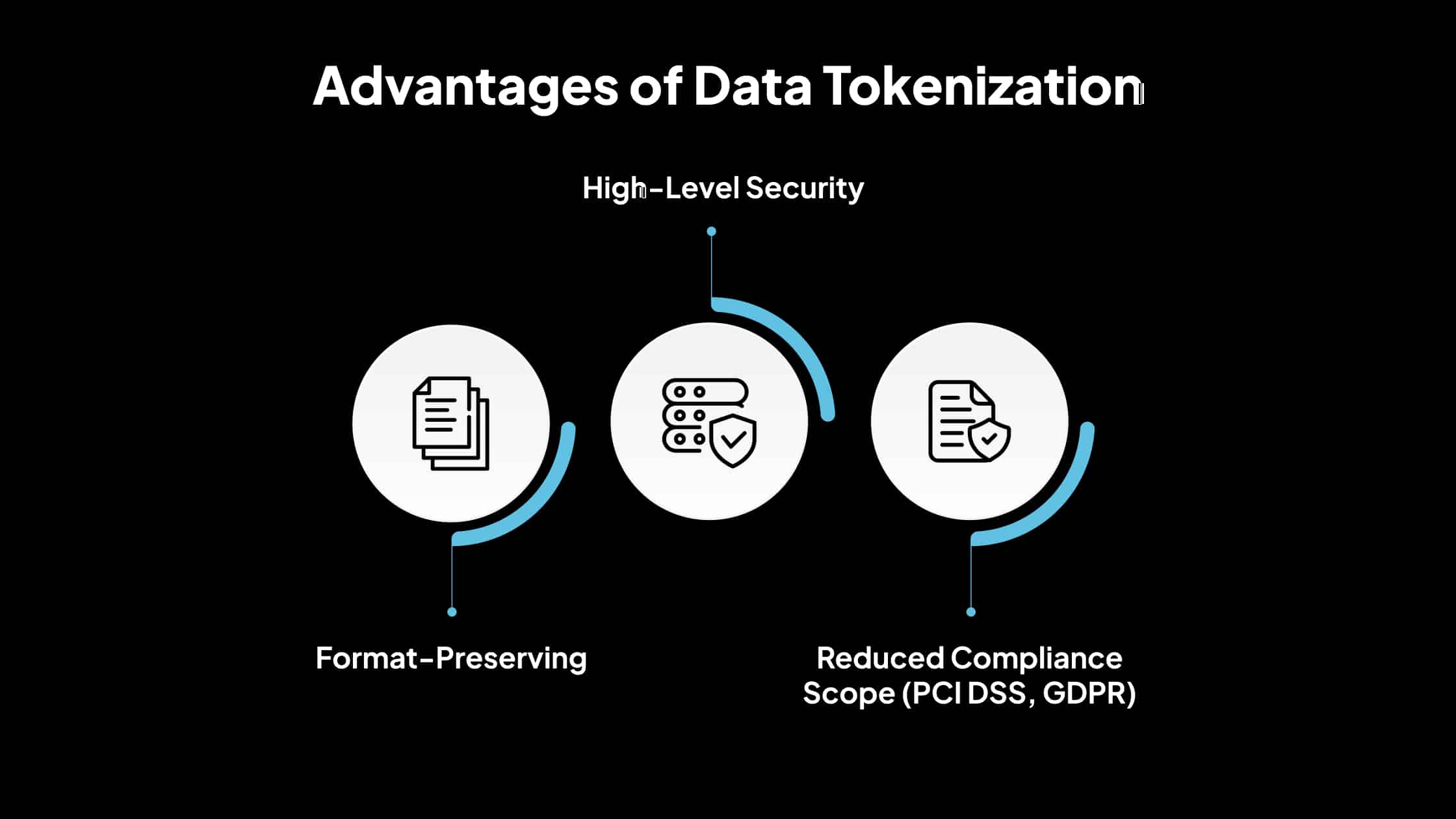
1. Format-Preserving
One of the main advantages of tokenization is that the tokens maintain the same structure and length as the original data. This makes integrating tokenized data into existing systems easier without requiring changes to database schemas, application logic, or user interfaces.
For example, a system expecting a 10-digit phone number can still operate correctly using a 10-digit token.
2. High-Level Security
Tokenization enhances data security by eliminating sensitive data from vulnerable environments. Since tokens are random and hold no intrinsic meaning, they are not helpful even if intercepted.
Moreover, because tokenization does not use mathematical algorithms to transform the data (unlike encryption), it is immune to cryptographic attacks and brute-force methods.
3. Reduced Compliance Scope (PCI DSS, GDPR)
Tokenization significantly narrows the scope of compliance audits by removing sensitive data from the primary processing environment. Under PCI DSS, systems that only handle tokens instead of card data can be exempt from stringent controls.
Similarly, in the context of the General Data Protection Regulation (GDPR), tokenization helps minimize the amount of personally identifiable information (PII) stored, thereby reducing exposure and potential penalties in the event of a data breach.
Data Masking Explained: Methods, Applications, and Compliance Advantages
Data masking is a technique used to hide or obscure sensitive information by altering its content so that it becomes unreadable or meaningless to unauthorized users.
Unlike tokenization, which replaces data with a retrievable token, data masking typically involves transforming the data in a way that prevents it from being reversed. Masking aims to protect sensitive data in non-production environments, such as during software development, testing, training, or analytics, where real data is not necessary.
Multiple masking techniques exist, including character scrambling, nulling out data, shuffling, substitution, and data blurring. Each method is selected based on the use case and the level of protection required.
Types of Data Masking
1. Static Data Masking
Static data masking is performed on a copy of the production database. The original sensitive data is replaced with masked values in this duplicate version before it is used in lower environments such as development or QA.
This ensures that sensitive data never leaves the secure production boundary. Once masked, the data cannot be reversed.
2. Dynamic Data Masking
Dynamic data masking occurs in real time during data retrieval. Sensitive fields are masked on the fly based on user roles and access rights, while the underlying data remains unchanged in the database. This method is suitable when different users require different access levels to the same dataset.
For example, a customer service representative may see only the last four digits of a customer’s credit card number, while a manager with higher privileges may see the full number. DDM is helpful in controlling access to sensitive data in live production environments without modifying the actual data.
3. Deterministic Masking
Deterministic masking ensures that the same input value is always replaced with the same masked value. This consistency is crucial when masked data needs to maintain referential integrity across different systems or databases.
For instance, if the name “Alice” is masked as “Elex” in one table, it will also be masked as “Elex” in all other related tables. This is particularly beneficial in testing scenarios where consistent data relationships are necessary.
Benefits of Data Masking
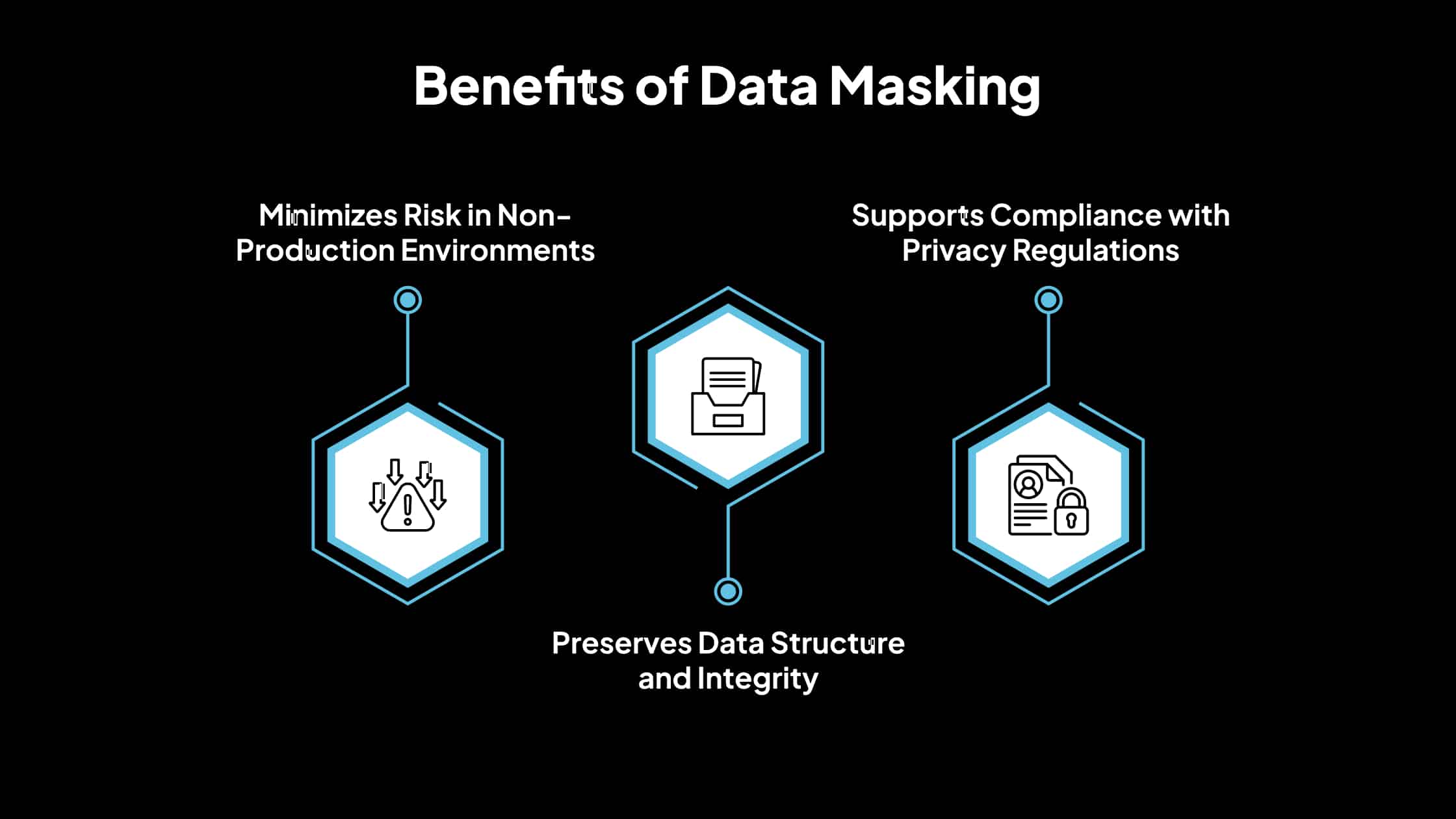
1. Minimizes Risk in Non-Production Environments
One of the primary benefits of data masking is its ability to protect sensitive data outside the production environment. Since test, staging, or analytics systems are more vulnerable to unauthorized access, using masked data ensures that any breach in these environments does not expose real data.
2. Preserves Data Structure and Integrity
Masked data maintains the original database’s format, relationships, and referential integrity. This allows teams to perform accurate testing and analytics without needing real data.
For example, customer IDs may be masked but still follow a valid format and remain linked to associated transaction records.
3. Supports Compliance with Privacy Regulations
Data masking is widely used to support compliance with various data protection regulations, including HIPAA, GDPR, and ISO standards. Organizations reduce their legal and financial exposure in case of a data breach by anonymizing or pseudonymizing sensitive data.
Tokenization vs. Data Masking: How Each Process Works
Understanding how data tokenization and masking operate is crucial for implementing effective data protection strategies. Both techniques aim to safeguard sensitive information but differ in their methodologies and applications.
1. How Data Tokenization Works
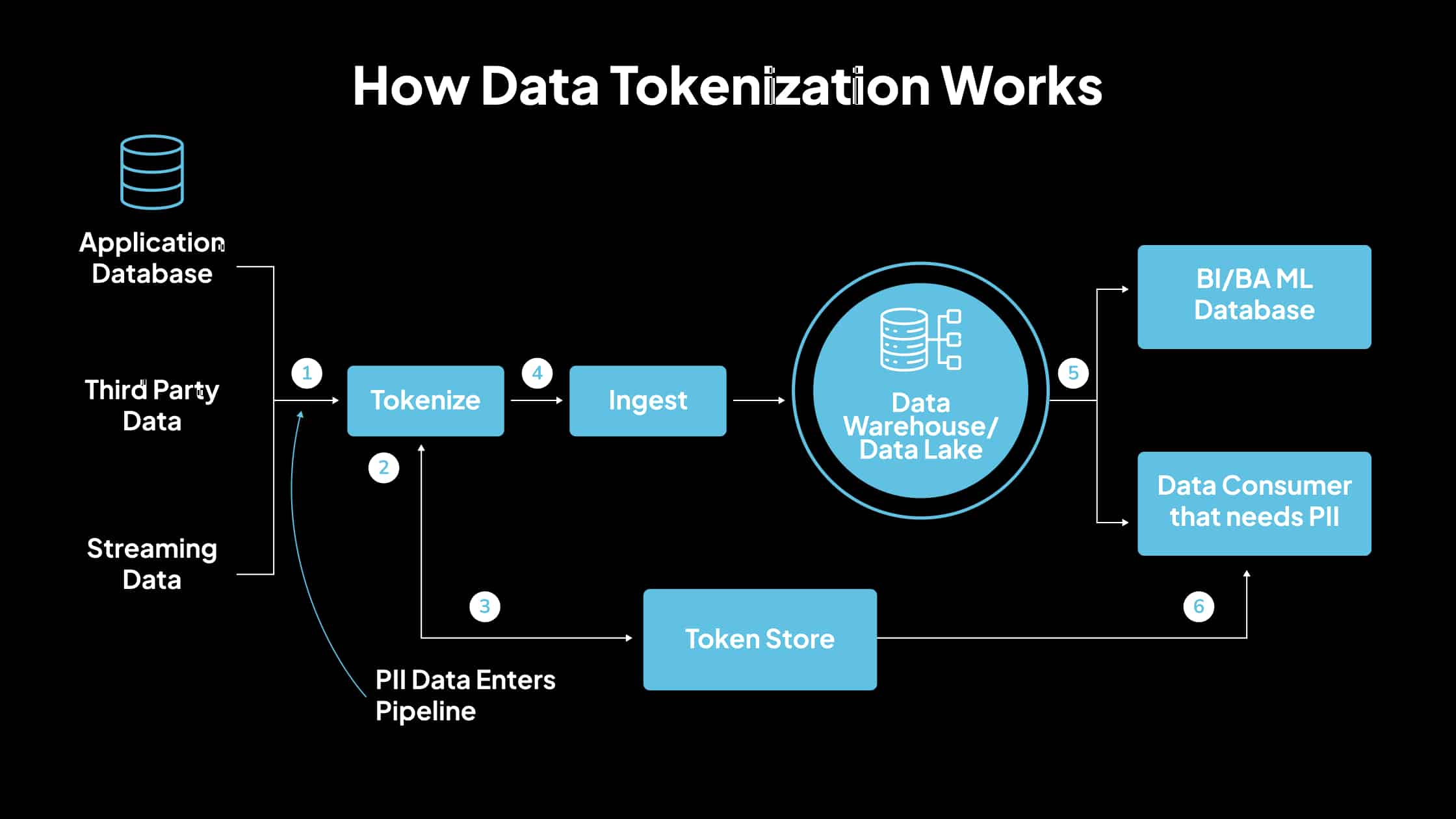
Data tokenization involves substituting sensitive data elements with non-sensitive, or tokenized, equivalents. These tokens have no exploitable meaning or value, reducing the risk associated with data breaches. The original sensitive data is stored securely in a separate location, often referred to as a token vault.
Essential Steps in Tokenization:
- Identification of Sensitive Data: Determine which data elements require protection, such as credit card numbers, social security numbers, or personal identifiers.
- Token Generation: Create a token that replaces the sensitive data. This token is typically a random string that maintains the format of the original data but lacks any meaningful value.
- Secure Mapping: Establish a secure association between the token and the original data. This mapping is stored in a protected environment, ensuring only authorized systems can retrieve the original data when necessary.
- Data Usage: Replace the token with sensitive data in systems and processes. This allows for normal operations without exposing actual sensitive information.
2. How Data Masking Works
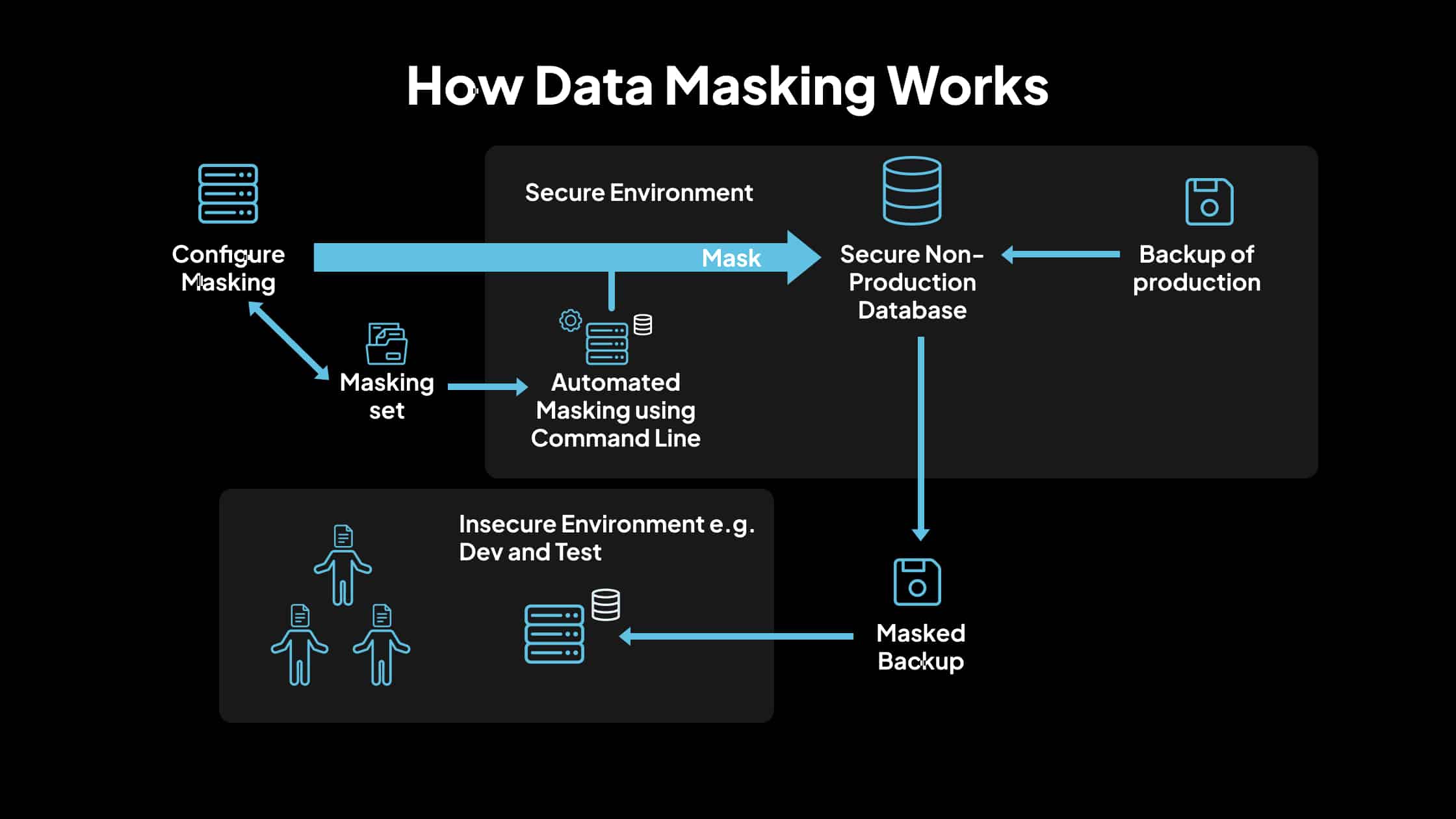
Data masking is a method used to protect sensitive information by replacing it with fictitious yet realistic data. This ensures that unauthorized individuals cannot access actual data, while still allowing the data to be useful for testing, development, and training purposes. Below is a detailed explanation of how the data masking process works:
- Identify and Classify Sensitive Data
Begin by conducting a comprehensive inventory of your data assets to pinpoint sensitive information that requires protection. This includes personally identifiable information (PII), financial records, health information, and other confidential data. Classify this data based on sensitivity levels and regulatory requirements to determine the appropriate masking techniques.
- Define Masking Policies and Rules:
Establish clear policies outlining which data elements need masking and the specific rules for transforming them. These policies should align with organizational security standards and compliance obligations.
For instance, replace real names with fictitious ones or obfuscate credit card numbers except for the last four digits.
- Select Appropriate Masking Techniques
Choose masking techniques that best suit the data types and intended use cases. Common techniques include:
- Substitution: Replacing real data with realistic, fictitious data (e.g., swapping actual names with randomly generated ones).
- Shuffling: Randomly rearranging data within a column to disrupt the original order.
- Number and Date Variance: Altering numerical values or dates within a specified range to obscure exact figures while maintaining data utility.
- Masking Out: Concealing parts of data with characters like asterisks (e.g., displaying a credit card number as **** **** **** 1234).
- Nulling Out: Replacing data with null values effectively removes the dataset’s information.
- Redaction: Removing or blacking out sensitive data entirely.
- Apply Masking to the Data
Implement the selected masking techniques on the identified data. Depending on the complexity and scale of the data, this can be done using specialized data masking tools or scripts.
Ensure that the masking process maintains data integrity and that the masked data remains usable for its intended purposes.
- Test and Validate Masked Data
After masking, thoroughly test the data to confirm that it meets the required security and usability standards.
Verify that the masked data does not properly expose sensitive information and functions within applications and systems. This step is crucial to ensure the masking process has not introduced errors or inconsistencies.
- Deploy Masked Data to Target Environments
Once validated, deploy the masked data to non-production environments such as development, testing, or training platforms. Ensure access controls are in place to prevent unauthorized access to masked and original data.
- Monitor and Maintain Masking Processes
Continuously monitor the effectiveness of the data masking processes and update them to address new data types, regulatory changes, or evolving security threats. Regular audits and reviews help maintain compliance and data protection standards.
Tokenization vs Data Masking: Feature Comparison
Below is a detailed feature-by-feature comparison of tokenization vs data masking to help you understand their differences in functionality and application.
1. Reversibility
Tokenization
Tokenization is a reversible process. Each token is mapped to its original data using a secure token vault. Only authorized systems or users with the correct permissions can retrieve the original data by accessing this vault. This makes tokenization suitable for use cases where the original data must be restored for processing or reporting purposes.
Masking
Most data masking techniques are irreversible. Once data is masked, especially in static masking, the original values are permanently altered or obfuscated.
This makes it impossible to retrieve the original data, which is acceptable in environments such as software testing or analytics, where real data is not required.
2. Data Format Preservation
Tokenization
Tokenized data retains the same format and structure as the original data. For example, a 16-digit credit card number remains a 16-digit token, making it easier to maintain compatibility with existing applications, database schemas, and user interfaces.
This enables organizations to integrate tokenization without requiring system redesign.
Masking
Masked data also preserves format, especially when using format-preserving masking techniques. However, depending on the method used, variations may be introduced (e.g., character substitution vs nulling).
While the structural integrity is usually maintained, the content is altered to render it non-sensitive and unusable outside the intended environment.
3. Security Level
Tokenization
Tokenization provides a high level of security by completely replacing sensitive values with unrelated tokens.
These tokens have no exploitable value unless paired with the heavily secured token vault. This minimizes exposure in case of unauthorized access and is not susceptible to cryptographic attacks.
Masking
Data masking also enhances security by transforming data to hide sensitive content. However, because it often uses deterministic methods or patterns, masked data may be partially inferred if not appropriately designed.
Its primary use is in environments with lower exposure risk but still needs to be managed (e.g., development, analytics).
4. Compliance Support
Tokenization
Tokenization supports compliance with industry regulations like PCI DSS and GDPR by removing sensitive data from systems in scope.
By storing only tokens in most environments and isolating the real data in a secure vault, organizations can significantly reduce the number of systems subject to compliance audits and lower associated costs.
Masking
Data masking is commonly used to support compliance with regulations like HIPAA, GDPR, and ISO standards, particularly in protecting personally identifiable information (PII) or personal health information (PHI) during internal operations. It is a practical method to achieving data minimization in analytics and testing environments.
5. Integration Complexity
Tokenization
Implementing tokenization requires changes to the data flow, secure vault infrastructure, and application tokenization logic.
It involves setting up access controls, secure storage, and detokenization processes, which makes deployment more complex but beneficial in high-risk environments.
Masking
Data masking generally has lower integration complexity. It can be applied to static copies of data or dynamically at the application layer with minimal infrastructure changes. Many masking solutions can be integrated quickly into test or development pipelines, offering a faster deployment path.
When to Use Tokenization vs. Masking: Choosing the Right Data Protection Method
Choosing between tokenization and masking depends on how and where your data is used.Here’s how to pick the right method based on how you use and protect your data.
When to Use Tokenization
Payment Processing and PCI DSS Compliance
In payment processing, tokenization is a critical tool for enhancing security and achieving compliance with the Payment Card Industry Data Security Standard (PCI DSS). By replacing sensitive cardholder data, such as Primary Account Numbers (PANs), with non-sensitive tokens, businesses can minimize the storage of actual card data within their systems.
This reduces the risk of data breaches and narrows the scope of PCI DSS compliance requirements, potentially lowering associated costs and efforts.
Healthcare Data Protection and HIPAA Compliance
Protecting patient information is paramount in healthcare, and tokenization serves as an effective method to secure electronic health records (EHRs). By substituting sensitive health data with tokens, healthcare providers can ensure that patient information remains confidential, aligning with the Health Insurance Portability and Accountability Act (HIPAA) regulations.
This technique allows for the safe handling of data in various applications, including billing and research, without exposing aatient details.
Protecting Sensitive Data in Analytics
Organizations often need to analyze data containing sensitive information. Tokenization enables the use of such data in analytics by replacing sensitive elements with tokens, thereby preserving data utility while maintaining privacy.
This is beneficial when analyzing customer behavior or conducting market research, as it enables the collection of meaningful insights without compromising individual privacy.
Cloud Data Storage
Organizations often store sensitive data in cloud environments for analytics, customer service, or operational purposes. Tokenization allows them to store and process data without revealing real identities or confidential information to cloud service providers.
This is particularly valuable when working with third-party platforms, as it limits the exposure of original data and ensures compliance with privacy regulations across various jurisdictions.
Mobile Payment Applications
In mobile wallets and payment apps (e.g., Apple Pay, Google Pay), tokenization protects cardholder data during transactions. Instead of transmitting the actual card number, a token is used.
This token is unique per transaction or per device, making it much harder for attackers to intercept and reuse payment data. It enables secure, contactless transactions without exposing the original financial information.
When to Choose Data Masking
Development and Testing Environments
Access to realistic data is essential for accurate results in software development and testing. However, using actual sensitive data poses security risks.
Data masking addresses this challenge by obfuscating sensitive information and creating datasets that mimic real data, thereby protecting confidential details. This practice ensures developers and testers can work effectively without compromising data security.
Training and Educational Purposes
Training staff or educating students often requires access to data that reflects real-world scenarios. Data masking enables organizations to disclose data without revealing sensitive information. Trainees can learn and practice using realistic datasets by masking personal identifiers and confidential details, ensuring compliance with privacy regulations and maintaining data confidentiality.
Secure Data Sharing with Third Parties
When sharing data with external partners, such as vendors or researchers, protecting sensitive information is crucial. Data masking facilitates secure data sharing by anonymizing confidential details while preserving the data’s structure and usability.
This enables organizations to collaborate effectively without risking data breaches or violating privacy laws.
Data Masking for Developers and Analysts
Access to production data is often necessary for debugging, feature development, or statistical analysis in software development and data analytics. However, exposing sensitive data in such environments increases the risk of accidental leakage or misuse.
Data masking enables developers and analysts to work with realistic data while maintaining confidentiality. It ensures consistency in data relationships (e.g., customer transactions, account balances) while hiding personally identifiable information (PII).
Streamlining Secure Access with Avahi’s Intelligent Data Masking Tool
As part of its commitment to secure and compliant data operations, Avahi’s AI platform provides tools that enable organizations to manage sensitive information precisely and accurately. One of its standout features is the Data Masker, designed to protect financial and personally identifiable data while supporting operational efficiency.
Overview of Avahi’s Data Masker
Avahi’s Data Masker is a versatile data protection tool designed to help organizations securely handle sensitive information across various industries, including healthcare, finance, retail, and insurance.
The tool enables teams to mask confidential data such as account numbers, patient records, personal identifiers, and transaction details without disrupting operational workflows.
Avahi’s Data Masker ensures only authorized users can view or interact with sensitive data by applying advanced masking techniques and enforcing role-based access control. This is especially important when multiple departments or external vendors access data.
Whether protecting patient health information in compliance with HIPAA, anonymizing financial records for PCI DSS, or securing customer data for GDPR, the tool helps organizations minimize the risk of unauthorized access while preserving data usability for development, analytics, and fraud monitoring purposes.
How the Data Masking Feature Works
The process of masking sensitive information using Avahi’s Data Masker is intuitive and AI-powered:
1. Upload File
Users begin by uploading the dataset or file containing sensitive information through the Avahi platform.
2. Data Preview
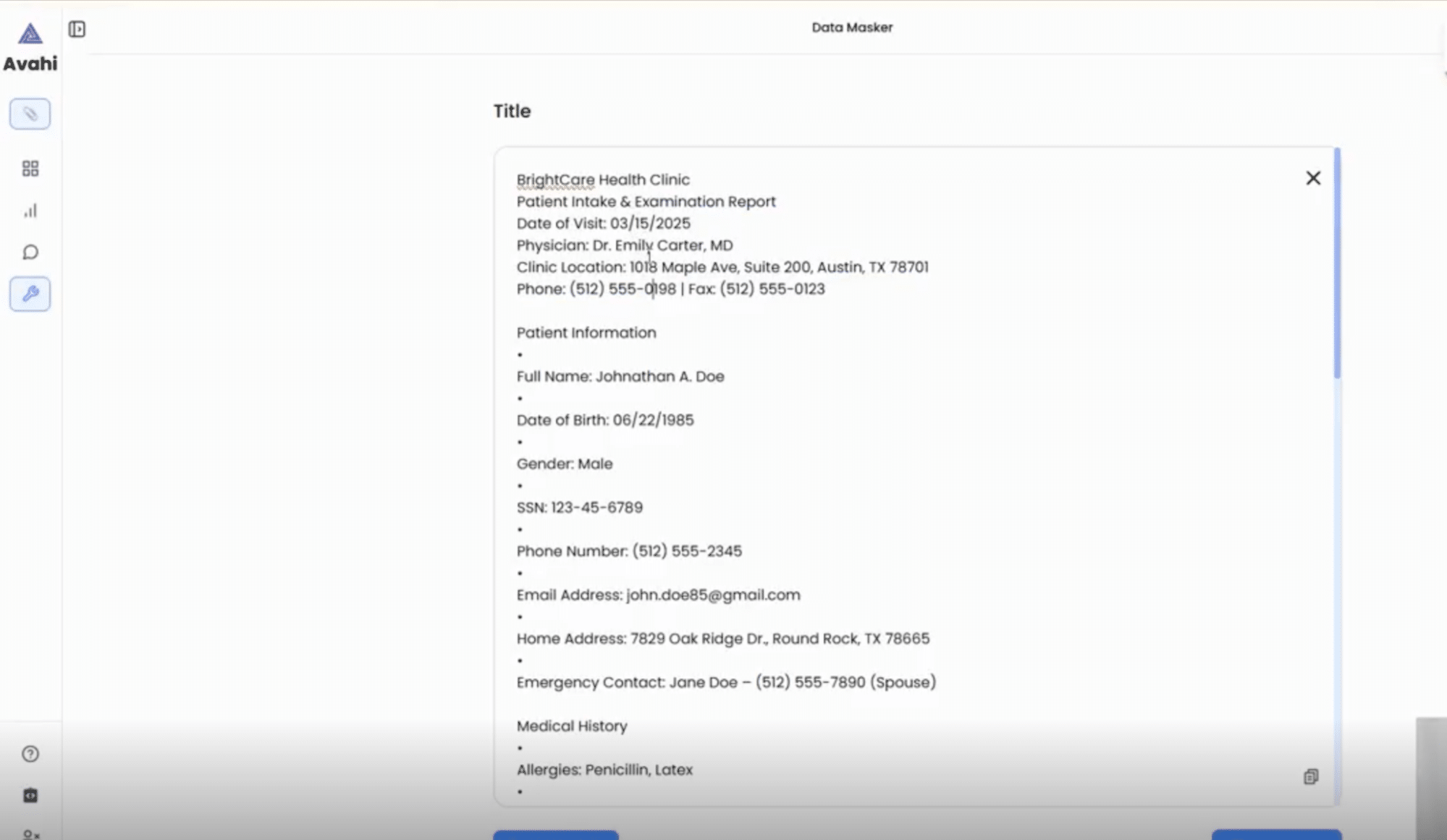
Once uploaded, the tool displays the structured content, highlighting fields typically considered sensitive (e.g., PANs, names, dates of birth).
3. Click ‘Mask Data’ Option
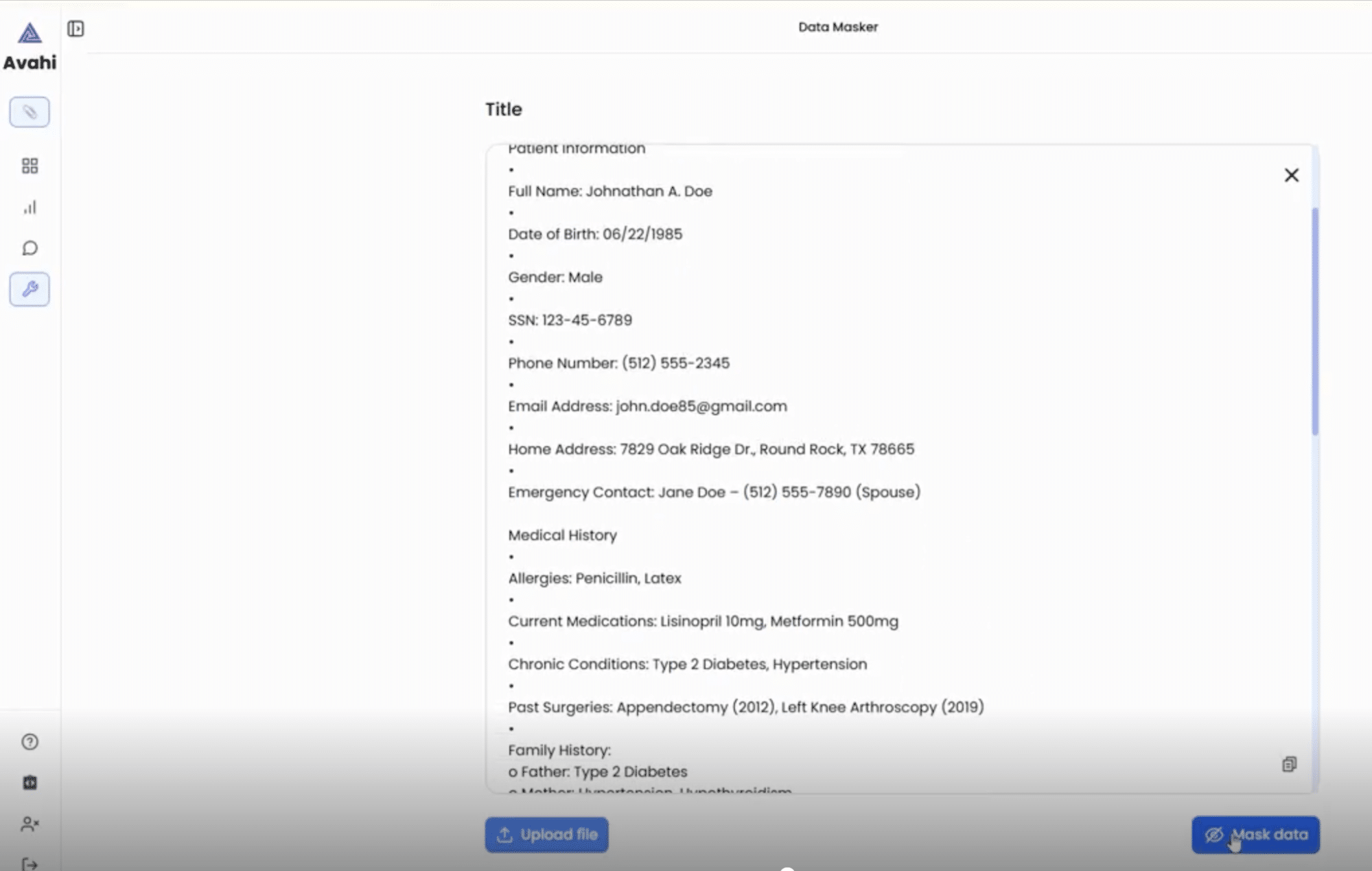
Users then initiate the masking process by selecting the ‘Mask Data’ option from the interface.
4. AI-Powered Transformation
Behind the scenes, Avahi uses intelligent algorithms and predefined rules to identify and mask sensitive data values. This transformation ensures that the masked data maintains its format and usability but does not contain the original information.
5. Secure Output
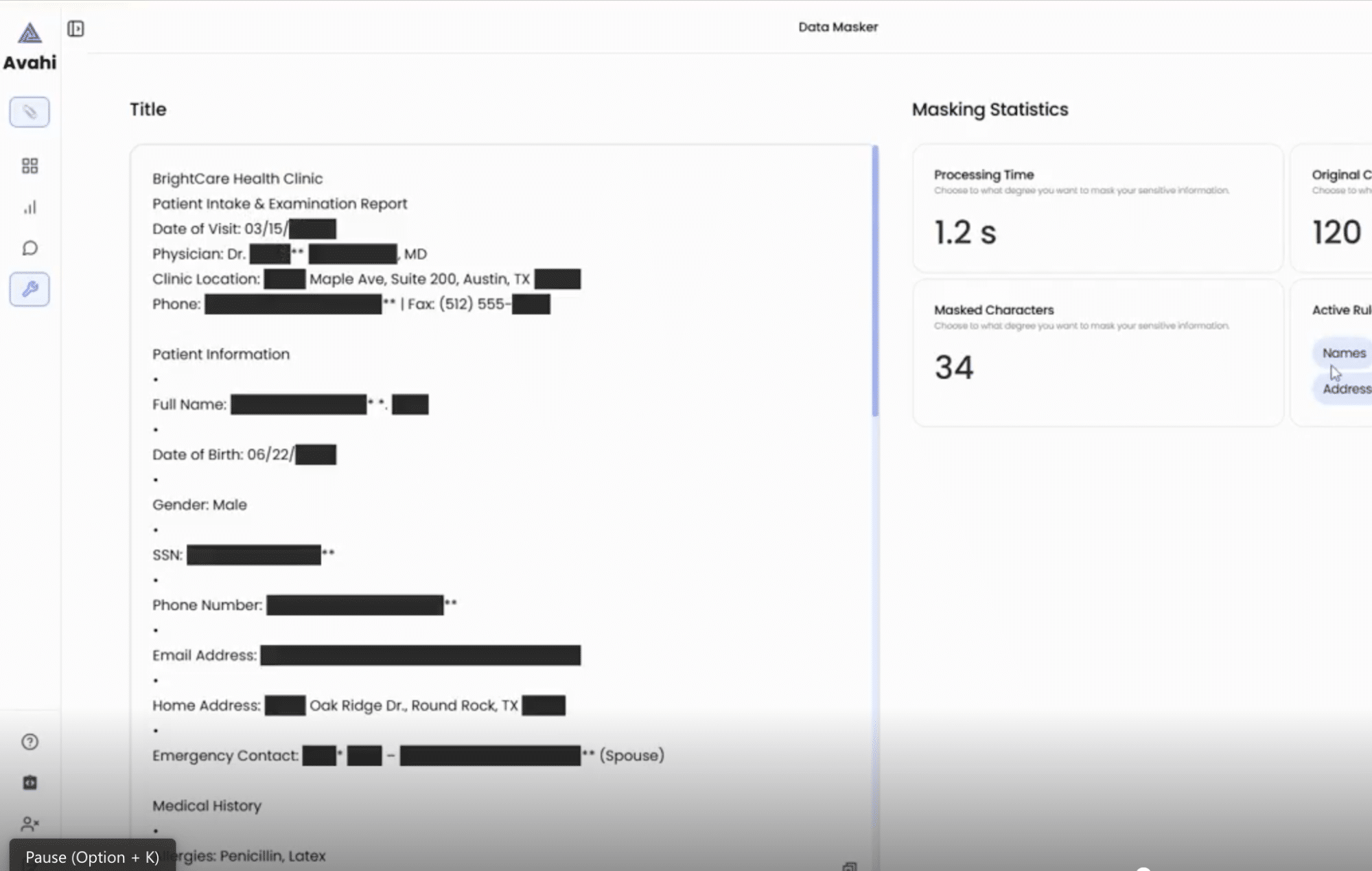
The resulting file shows obfuscated values instead of the original sensitive content, which can be used safely for fraud analysis, reporting, or third-party collaboration.
Avahi’s Data Masker integrates automation, user-friendly controls, and secure AI-driven masking to ensure regulatory compliance (e.g., PCI DSS) while minimizing operational friction.
Simplify Data Protection with Avahi’s AI-Powered Data Masking Solution

At Avahi, we recognize the crucial importance of safeguarding sensitive information while maintaining seamless operational workflows.
With Avahi’s Data Masker, your organization can easily protect confidential data, from healthcare to finance, while maintaining regulatory compliance with standards like HIPAA, PCI DSS, and GDPR.
Our data masking solution combines advanced AI-driven techniques with role-based access control to keep your data safe and usable for development, analytics, and fraud detection.
Whether you need to anonymize patient records, financial transactions, or personal identifiers, Avahi’s Data Masker offers an intuitive and secure approach to data protection.
Ready to secure your data while ensuring compliance? Get Started with Avahi’s Data Masker!
Frequently Asked Questions (FAQs)
1. What is the difference between tokenization and masking in data security?
The primary difference between tokenization and masking lies in their reversibility and the specific use cases for which they are applied. Tokenization replaces sensitive data with non-sensitive tokens and securely stores the original data, making it ideal for transactional systems. In contrast, data masking alters the data to prevent reversibility, making it suitable for non-production environments, such as development or testing.
2. When should you use tokenization vs masking for protecting data?
When to use tokenization vs masking depends on your environment. Use tokenization for live production systems, especially where PCI compliance is required. Use masking in non-production areas such as development, QA, or training to work with realistic but anonymized data safely.
3. How do tokenization and masking compare to other data security techniques?
In a comparison of data security techniques, tokenization and masking stand out for protecting sensitive data at rest or in use. While encryption secures data mathematically, tokenization and masking reduce risk exposure by replacing or obfuscating sensitive elements, especially in analytics, storage, and third-party environments.
4. Can tokenization support GDPR compliance for protecting customer data?
Yes, GDPR tokenization techniques help protect personal data by replacing identifiers with meaningless tokens, reducing the risk of exposure. It minimizes the storage of personally identifiable information (PII) and limits the potential impact in the event of a data breach.
5. How does data masking help developers and analysts in secure environments?
Data masking for developers and analysts ensures that teams can work with realistic datasets without exposing sensitive information. It maintains data relationships and structure while removing identifiable data, which is especially useful in HIPAA data masking solutions and test environments.



